
Your open rates are dropping. This is not a hypothesis. It’s a material reality reflected in your delivery reports. The standard advice is to A/B test subject lines. This advice is correct but incomplete. Manual A/B testing, as practiced by most teams, is a slow, error-prone ritual that generates statistically insignificant data points. By the time you’ve picked a “winner” from a single test on a small segment, the rest of your audience has already ignored three more of your campaigns.
The core failure is latency. Human-driven testing introduces massive delays between hypothesis, execution, analysis, and implementation. A campaign manager thinks of two subject lines on Monday, the test runs on Tuesday, they check the results on Wednesday, and maybe, if nothing else is on fire, they apply the learning to next week’s send. This workflow is a relic. It cannot compete with the aggressive filtering of modern inboxes or the sheer volume of noise your audience endures.
The Failure Point of Manual Processes
Manual testing is fundamentally broken at scale. The process relies on an analyst pulling a CSV, a campaign manager duplicating a campaign in the ESP, and someone remembering to check the results 24 hours later. Each step is a vector for error. Segments get misaligned. The control group gets contaminated. The results are analyzed based on gut feeling over statistical confidence.
This approach also fails to test the right variables. Teams fixate on subject lines while ignoring equally critical factors like the preview text, the sender name, or the precise send time. Testing these variables concurrently is a combinatorial nightmare for a manual process. The result is a shallow testing pool that optimizes for a local maximum, leaving massive conversion opportunities on the table.
The Architecture of an Automated Testing Engine
The fix is to remove the human bottleneck. This requires building a closed-loop system that programmatically generates variations, executes tests, analyzes results, and feeds winning attributes back into the system. This is not about using your ESP’s built-in A/B test button. It is about architecting an external system that drives your ESP via its API.
A functional architecture consists of four primary components:
- The Triggering Logic: Tests are not initiated manually. They are triggered by performance degradation. A monitoring script checks key campaign metrics. If a campaign’s open rate drops below its 30-day moving average by a predefined threshold, say 15%, the system automatically queues up a testing sequence for subsequent sends to that audience segment.
- The Variation Generator: This component programmatically creates the test assets. It combines predefined elements like value propositions, urgency drivers, and personalization tokens to generate hundreds of potential subject line and preheader combinations. It forces you to move beyond human creativity, which is inconsistent.
- The Execution Engine: A service that interacts with your ESP’s API. It creates the campaign variants, splits the target audience into statistically relevant control and test groups, and schedules the sends. It handles the low-level mechanics of campaign creation that humans are slow and bad at.
- The Analysis and Feedback Pipeline: Webhooks from your ESP feed open, click, and delivery data in near real-time to an API endpoint. This data is piped into a database or data warehouse where a script calculates the performance of each variant and determines statistical significance. Winners are flagged, and their attributes are stored to be used as the control for future campaigns or as inputs for the variation generator.
This entire loop runs without a single human click. It is a machine for finding what works, not a tool for confirming a marketer’s bias.
Diving into the Variation Generator
A simple variation generator can be built with a Python script. It doesn’t require a complex machine learning model. The objective is to create structured permutations from a dictionary of components. You define lists of greetings, value props, calls to action, and formatting styles. The script then assembles them into coherent subject lines.
Consider this stripped-down example. It takes a base structure and injects components to create multiple unique outputs. This is how you scale hypothesis generation beyond what a single person can brainstorm in a meeting.
def generate_subject_lines(components):
"""
Generates subject line variations from a dictionary of components.
"""
permutations = []
for verb in components.get('verbs', ['']):
for noun in components.get('nouns', ['']):
for urgency in components.get('urgency', ['']):
# Strip extra spaces if a component is empty
line = f"{verb} your {noun} {urgency}".strip().replace(' ', ' ')
permutations.append(line)
return permutations
# Define the building blocks for the subject lines
subject_components = {
'verbs': ['Get', 'Download', 'Access'],
'nouns': ['report', 'guide', 'checklist'],
'urgency': ['now', 'today', 'before it expires']
}
variants = generate_subject_lines(subject_components)
for v in variants:
print(v)
# Output would include lines like:
# "Get your report now"
# "Download your guide today"
# "Access your checklist before it expires"
# ...and so on for all 27 combinations.
The logic can be expanded to include preview text, sender name variations (e.g., “John at Company” vs. “The Company Team”), and other elements. The point is to systematize the creative process, turning it into a predictable, machine-driven task. This is how you test dozens of hypotheses per week, not one.
The Truth about Send Time Optimization
Most ESPs offer a “Send Time Optimization” feature. It’s usually garbage. The logic is naive, typically sending the email at the same time of day the user last opened a message from you. This identifies correlation, not causation. It creates an echo chamber, reinforcing existing behavior without discovering new engagement windows.
A true optimization engine tests this variable rigorously. It uses a chronosending approach. A target segment is split into 24 smaller, statistically identical cohorts. The automation engine then sends the exact same campaign to each cohort, one per hour, over a 24-hour period. This is the only way to build a true map of your audience’s attention. It’s a brute-force method that finds the actual causal relationship between send time and engagement.
Of course, this approach is a wallet-drainer. It requires a high send volume and a sophisticated segmentation engine to execute without burning out your list. But it yields data you can actually trust, unlike the black-box feature your vendor sold you.
Building a Self-Correcting Feedback Loop
The most critical part of this architecture is the feedback loop. A test without a feedback mechanism is just a data point. A test integrated into a feedback loop is part of an intelligence-gathering system. When the analysis pipeline declares a winner, two things must happen automatically. First, the winning variant’s attributes (subject, sender, send time) become the new control for that specific audience segment. This creates a continuous, incremental improvement cycle.
Second, the attributes of the winning variant are fed back into the variation generator. If subject lines with numbers consistently outperform those without, the generator should learn to prioritize number-based formats in future tests. This turns the system from a simple testing framework into a self-optimizing engine. It’s the difference between a conveyor belt that moves parts and a flywheel that stores and reapplies energy. The system gets smarter with every send.
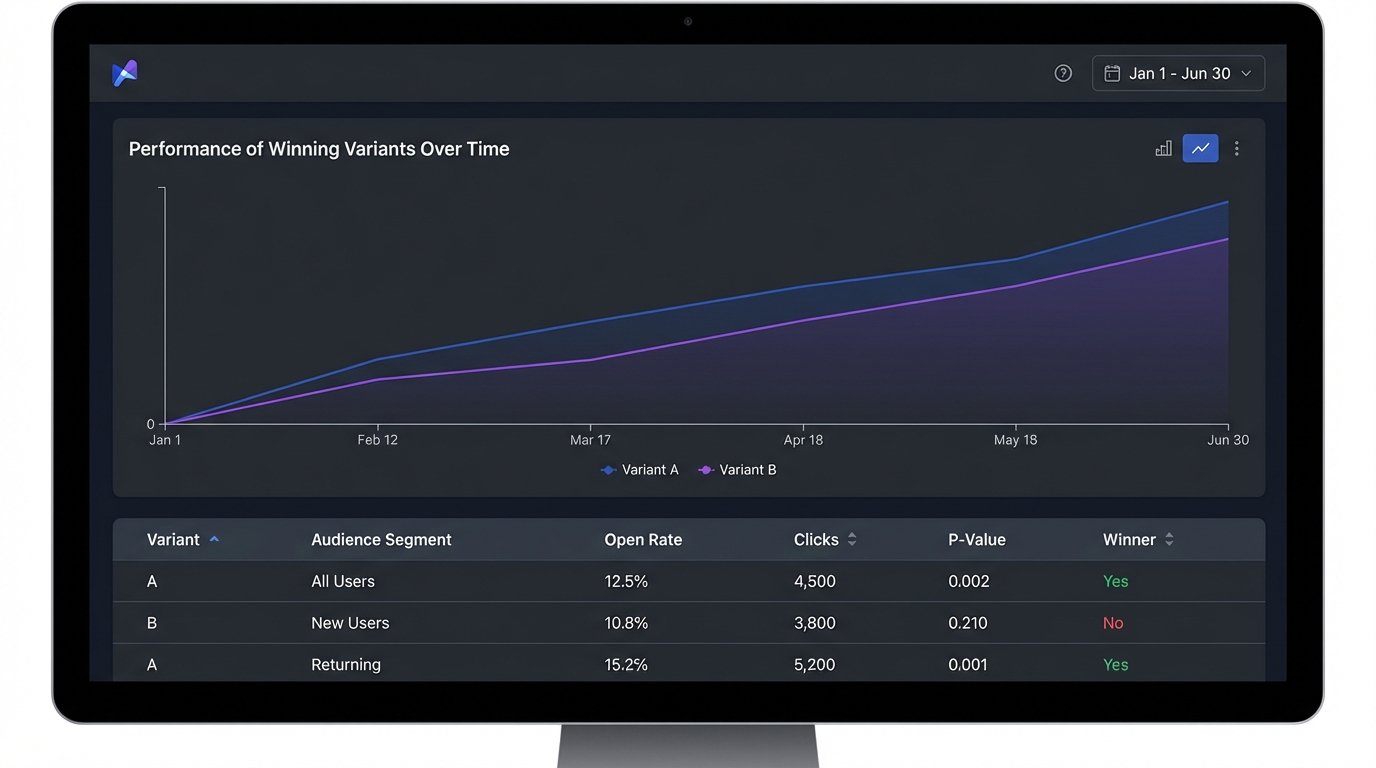
This requires a database to store test results, not just a spreadsheet. You need to log the variant, the audience segment, the performance data, and the confidence level of the result. Over time, this historical data becomes your most valuable asset, providing a detailed map of what resonates with different parts of your audience.
Implementation Traps That Will Wreck Your Project
Building this system is not a weekend project. Several technical and logical traps can invalidate your results or get your IP address blacklisted. You need to anticipate them.
Trap 1: Chasing Statistical Noise
The system must be configured to demand statistical significance. A test run on a 200-person segment that shows a 2% lift is just noise. Your analysis script must calculate a p-value or a Bayesian probability to ensure the result is not due to random chance. Set a confidence threshold, typically 95%, that must be met before a winner is declared. If no variant reaches this threshold after a predetermined number of sends, the test is marked inconclusive and the control variant wins by default. Without this rigor, you’ll be “optimizing” your campaigns based on randomness.
Trap 2: API Rate Limiting
Your ESP’s API is not an infinite resource. If you start creating and querying hundreds of campaigns programmatically, you will hit your rate limits. A robust execution engine must include logic for handling 429 “Too Many Requests” responses. It should respect `Retry-After` headers, implement exponential backoff, and use batch processing for data retrieval wherever possible. Ignoring this will get your API key temporarily, or permanently, revoked. You become a noisy neighbor on the ESP’s platform, and they have ways of quieting you down.

Trap 3: Audience Contamination
Running multiple tests concurrently on a large, undifferentiated audience is a recipe for bad data. A user who is part of a subject line test and a send time test at the same time pollutes both experiments. You cannot isolate the variable responsible for a change in their behavior. Your automation architecture needs a “test scheduler” or a master segmentation logic that ensures test groups are mutually exclusive. It’s like trying to get a clean audio recording in a room with three different songs playing. You have to isolate the signal.
This system demands a more disciplined approach to audience management. You can’t just blast your whole list. You need clearly defined, stable segments that can be used for consistent testing over time. The alternative is a mess of overlapping tests that produces meaningless data.
The goal is not simply to run more A/B tests. The goal is to build an engine that perpetually refines your communication strategy. It’s a shift from manual, intuition-based decisions to a data-driven, automated system that is always learning. Your competitors are likely still arguing about which emoji to use in a subject line. This machine makes that argument obsolete.