Your email service provider’s API returning a `200 OK` is the biggest lie in automation. It confirms nothing beyond the fact that their server accepted your request payload. It doesn’t mean the email landed in an inbox, bypassed a spam filter, or was ever seen by a human. We build critical workflows on this flimsy assumption of delivery, and then act surprised when users claim they “never got the message.”
This isn’t a simple delivery issue. It’s a fundamental architectural failure rooted in fire-and-forget communication. We push data into a black box and hope for the best. The real problem is the absence of a feedback loop. Without one, you’re operating blind, making business decisions based on API theater instead of actual user engagement.
Diagnosing the Core Failure: The Delivery Black Box
The standard operational flow is dangerously simple. An application event, like a user signup or a password reset request, triggers an API call to a service like SendGrid or Mailgun. The service validates the API key, checks the payload syntax, and queues the email for delivery. It then sends back a success response. The application logic dutifully logs `email_sent: true` and moves on. The job is considered done.
This is where the chain of custody breaks. Between that `200 OK` and the user’s screen, the message traverses a dozen systems, each with its own failure points. Corporate firewalls, overzealous spam filters, inbox provider rate limiting, and even simple typos in the recipient address can cause the delivery to fail silently. Your system remains blissfully unaware, assuming the message was received and read.
Relying on open and click rates from the ESP’s dashboard is a lagging indicator, not a real-time operational tool. It’s useful for marketing campaign analysis, but it’s useless for driving an immediate, state-dependent action for a single user. We need to gut this passive model and replace it with an active, event-driven architecture that listens for confirmation.
The Fix: Architecting an Event-Driven Confirmation Loop
The solution is to invert the communication model. Instead of just pushing data out, we need to ingest events back from the service provider. This requires two primary components: a webhook listener on our end and proper webhook configuration at the ESP. This transforms a one-way shout into a two-way conversation, where every step of the email’s journey generates a machine-readable event.
This architecture forces us to stop thinking about notifications as a single action and start modeling them as a state machine. The states are not just `sent` and `failed`. They are `processed`, `delivered`, `bounced`, `deferred`, `opened`, and `clicked`. By capturing these state transitions, we can build logic that reacts to reality, not to a five-minute-old API response.

Component 1: The ESP Webhook Emitter
Your first task is to configure your ESP to send event data to an endpoint you control. In services like Mailgun or SendGrid, this is usually found under a “Webhooks” or “Event Notifications” section. You provide a URL and select which events you want to subscribe to. At a minimum, you need `delivered`, `bounced`, and `opened`. Subscribing to every event is just asking to get battered by unnecessary traffic.
The ESP will POST a JSON payload to your endpoint for every subscribed event. The structure of this payload is specific to the provider, but it generally contains the event type, a timestamp, the recipient email, and some metadata you might have injected into the original API call. This metadata, like a `user_id` or `transaction_id`, is critical for connecting the event back to a specific user or action in your system.
Component 2: The Ingestion Endpoint and Logic
The webhook listener is a simple API endpoint that does one thing: it catches the JSON payload from the ESP, validates it, and queues it for processing. It should not perform heavy logic synchronously. Its only job is to acknowledge the request with a `200 OK` as fast as possible. If your endpoint is slow, the ESP might time out and retry the webhook, leading to duplicate events and a world of pain.
A serverless function like AWS Lambda or a Cloudflare Worker is a perfect fit here. It’s cheap, scales automatically, and forces you into a lean processing model. The function receives the payload, performs a basic sanity check (e.g., verifying a signature token to ensure the request came from the ESP), and then places the validated event onto a message queue like SQS or a Redis stream for asynchronous processing.
Here’s a bare-bones example of what the listener logic might look like in a Python Flask application. This is simplified for clarity. A production version would have robust error handling and signature verification.
from flask import Flask, request, jsonify
import json
app = Flask(__name__)
# This is a simplified example. In production, you would use a message queue.
# And you MUST validate the request signature.
def process_event_async(event_data):
user_id = event_data.get('user_id')
event_type = event_data.get('event')
timestamp = event_data.get('timestamp')
print(f"Processing event for user {user_id}: {event_type} at {timestamp}")
# Here you would update your state database (e.g., Redis, DynamoDB)
# update_user_communication_status(user_id, 'email', event_type)
@app.route('/webhooks/email-events', methods=['POST'])
def email_event_webhook():
events = request.get_json()
# ESPs often send events in batches
for event in events:
# Immediately hand off to an async worker or queue
process_event_async(event)
return jsonify({'status': 'success'}), 200
if __name__ == '__main__':
app.run(debug=True, port=5000)
Trying to manage this without an asynchronous worker is like shoving a firehose through a needle. The webhook endpoint will buckle under any significant load.
State Management is Not Optional
Simply receiving events is not enough. You must track the state of each user’s communication journey. Without a persistent state store, you have no context. An `opened` event means nothing if you don’t know that a `delivered` event preceded it. Webhook events can and will arrive out of order, so your logic must be idempotent and rely on timestamps.
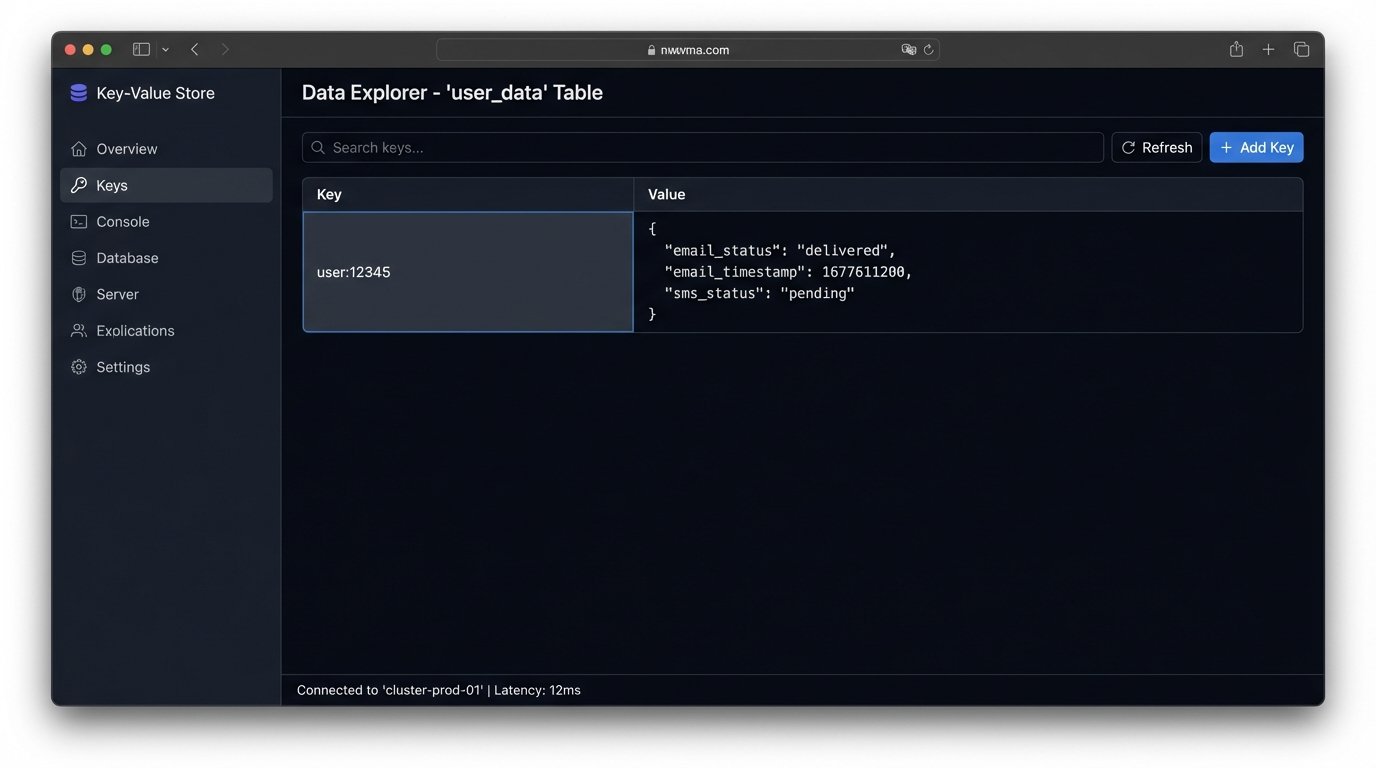
A key-value store like Redis or DynamoDB is ideal for this. The key can be the `user_id`, and the value can be a JSON object tracking the status of each channel. For example, a user’s record might look like this: `user:12345 -> {“email_status”: “delivered”, “email_timestamp”: 1677611200, “sms_status”: “pending”}`. When your asynchronous worker processes an `opened` event, it retrieves this record, checks the timestamp, and updates the `email_status` to `opened`.
This state record becomes your single source of truth. It drives all subsequent decisions. It prevents you from sending duplicate messages and allows you to build time-based escalation logic.
Triggering the Secondary Channel: The SMS Escalation
With a stateful system in place, you can now build intelligent cross-channel logic. The business rule might be: “If a critical email (like an account verification) is not opened within 15 minutes of delivery, send an SMS confirmation.” This is impossible with a stateless, fire-and-forget approach.
The implementation requires a scheduled job or a time-based workflow. Every minute, a scheduler scans the state database for users whose `email_status` is `delivered` and whose `email_timestamp` is more than 15 minutes in the past. For each match, it triggers an API call to an SMS provider like Twilio, sending a concise message like: “We sent an important verification email to you. Please check your inbox to continue.”
This secondary channel is not a replacement. It’s a nudge. It drives the user back to the primary channel, increasing the probability of the desired action. But be warned, SMS is a wallet-drainer. Unlike email, every message has a direct, non-trivial cost. This escalation logic must be reserved for high-value transactions, not for marketing newsletters.
Bracing for Failure: Edge Cases and Real-World Messiness
This architecture is more resilient, but it introduces new failure modes you must anticipate. Your webhook listener is now a mission-critical piece of infrastructure. If it goes down, your entire feedback loop is severed. You need robust monitoring, alerting, and a plan for what happens when your endpoint is unavailable. Most ESPs have a retry policy, but they will eventually give up and discard the events.
Handling Out-of-Order Events
Network latency and distributed systems guarantee that events will not always arrive in the order they occurred. You might receive a `clicked` event before the `opened` event. Your state update logic must handle this by checking timestamps. Never update a status to an earlier state. If the current status is `opened` at time `T+5` and you receive a `delivered` event with time `T`, you ignore the incoming event.
The Unsubscribe Problem
You must also provide a way for users to opt out of SMS messages. This means your Twilio webhook handler needs to process `STOP` messages and update the user’s state record to `{…, “sms_opt_out”: true}`. Your escalation logic must check this flag before ever attempting to send an SMS. Failing to honor opt-outs is a fast track to getting your number blocked by carriers.
Building this multi-channel confirmation system is not a trivial undertaking. It requires a shift from simple scripting to thinking in terms of distributed, event-driven systems. You are effectively building a small-scale observability platform focused on user communication.
The result is a system that no longer operates on assumptions. It operates on verifiable data, reacting to actual user engagement signals in near real-time. You stop wasting support cycles on “I never got the email” tickets and start building workflows that intelligently adapt to communication breakdowns. It’s more complex, but it replaces blind hope with architectural certainty.