
Stop Pretending Personalization Is Magic
The entire premise of “personalization at scale” rests on a single, fragile assumption. The assumption is that your data is clean, current, and accessible. Most of the time, it’s none of those things. The system isn’t failing because the templating engine is weak. It’s failing because the data pipeline is a mess held together with cron jobs and wishful thinking.
Before you blame the ESP or the SMS gateway, look at your database. The root of every failed `{{user.firstName}}` merge is a null value in a column that someone swore would always be populated. This isn’t about better algorithms. It’s about better data discipline and engineering for failure, because failure is the default state.
Data Hydration Is Not A Batch Job Anymore
Relying on a nightly batch job to sync user data for your messaging platform is a recipe for embarrassment. A user updates their preferences, then gets an email an hour later that completely ignores that update. This happens because the automation trigger fired before your ETL process lumbered to life. The data was stale the moment the event occurred.
You have to gut the batch-processing mentality. The correct architecture is event-driven. A user action, like a purchase or a profile update, must fire a webhook or drop a message onto a queue. A listener service then immediately fetches that delta and pushes it to the marketing platform’s API. This forces data consistency between your system of record and your messaging system in near real-time.
The trade-off is complexity and cost. An event-driven architecture means more services to monitor and more API calls, which can turn into a wallet-drainer. But the alternative is sending messages based on what a user did yesterday, which is a fast track to the spam folder.
Real-Time vs. Micro-Batch: A Necessary Compromise
A pure real-time event stream sounds great until a downstream API goes down and your message queue backs up into the millions. We often implement a micro-batching system as a buffer. Events are collected for 60 seconds, bundled into a single API call, and then processed. This reduces API chatter and provides a small cushion for transient network failures.
This approach isn’t truly real-time, but it’s close enough for most marketing automation. The user won’t notice a 60-second delay. They will absolutely notice a 24-hour delay.
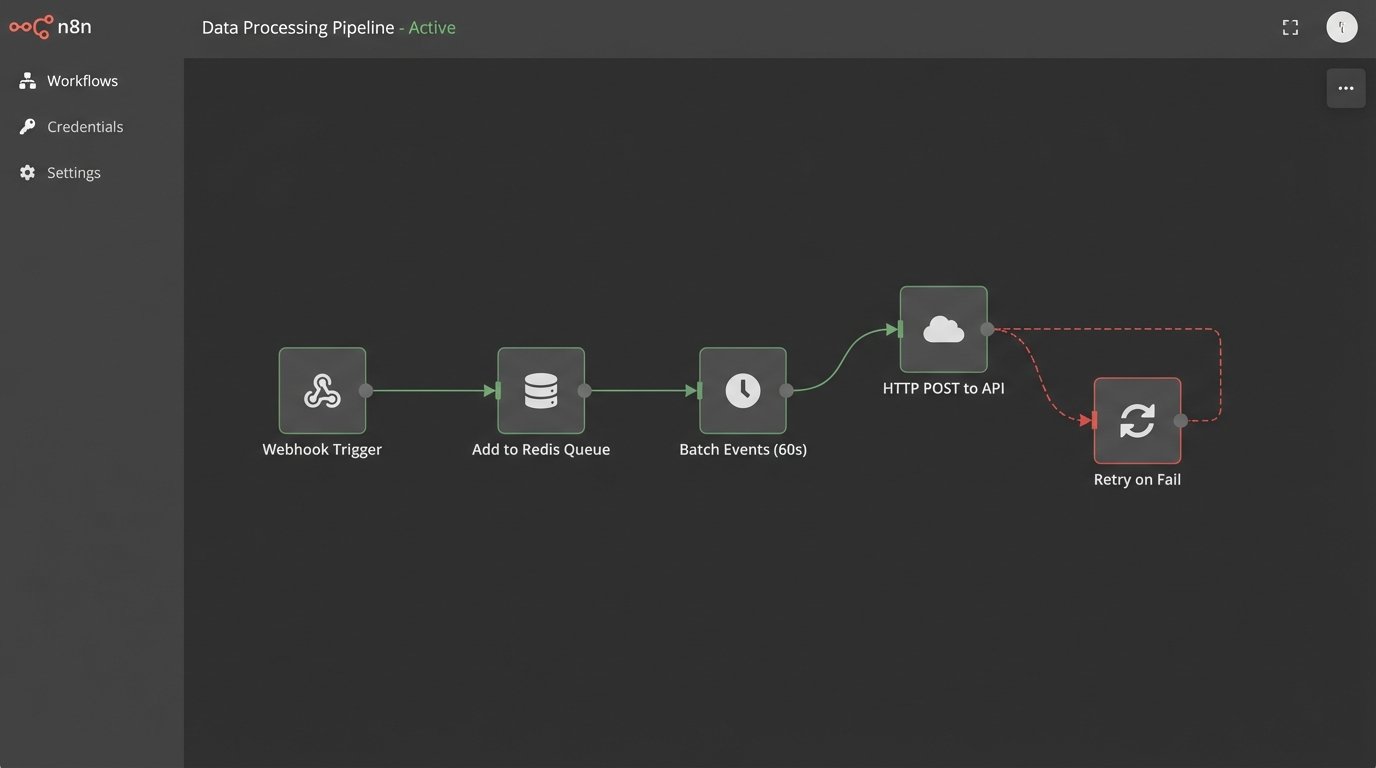
Treating your data pipeline like a pristine laboratory is a fantasy. It’s more like a city’s sewer system. You have to engineer for clogs, unexpected inputs, and sudden deluges. Your hydration logic needs circuit breakers and retry mechanisms built in from day one.
Build Templates That Don’t Explode
Every templating language allows for default values. Almost no one uses them correctly. A message that reads “Hello, !” is a direct result of engineering laziness. The frontend team would never let an empty variable render on a webpage, yet we allow it in emails that go to millions.
The fix is to enforce a strict policy of fallbacks on every single personalization token. Every variable must have a sane, generic default. This is non-negotiable. The goal is that if the entire data object for a user fails to load, the message still renders as a readable, if generic, communication. It’s damage control.
Tiered Fallback Logic
A single fallback isn’t enough. We build a tiered system. For a product recommendation, the logic checks for personalized recommendations first. If none exist, it falls back to category-level recommendations. If that’s also empty, it falls back to site-wide best-sellers. If the entire recommendation engine is down, it injects a static, generic promotional block.
This prevents the dreaded empty space in an email where a dynamic block was supposed to be. Here is a simplified example using a Jinja2-like syntax for an email subject line. The logic attempts to use a specific item name, then a category, then a generic default.
<h3>
{% if AbandonedCart.ItemName %}
Still thinking about the {{ AbandonedCart.ItemName }}?
{% elif AbandonedCart.ItemCategory %}
Don't miss out on these great items in {{ AbandonedCart.ItemCategory }}!
{% else %}
You left something in your cart
{% endif %}
</h3>
This code prevents a catastrophic failure. It guarantees a usable subject line even if parts of the data payload are missing. This is basic defensive programming applied to marketing.
Dynamic Content Is More Than Variable Substitution
Injecting a first name is trivial. Real personalization involves swapping entire sections of a message based on user attributes. A new user gets the “Welcome” block with onboarding tips. A power user gets the “Advanced Features” block. A user in a specific segment gets a block with content localized to their region.
This requires your data source to provide clean segmentation data. Attributes like `user.segment`, `user.lifecycleStage`, or `user.isPowerUser` must be readily available at send time. The messaging template then becomes a container with conditional logic that determines which content blocks to render.
The operational load here is significant. You are no longer managing one template. You are managing dozens of modular content blocks and the complex business logic that stitches them together. This is where version control and a proper deployment process become critical. You can’t let marketers edit this logic directly in a WYSIWYG editor.
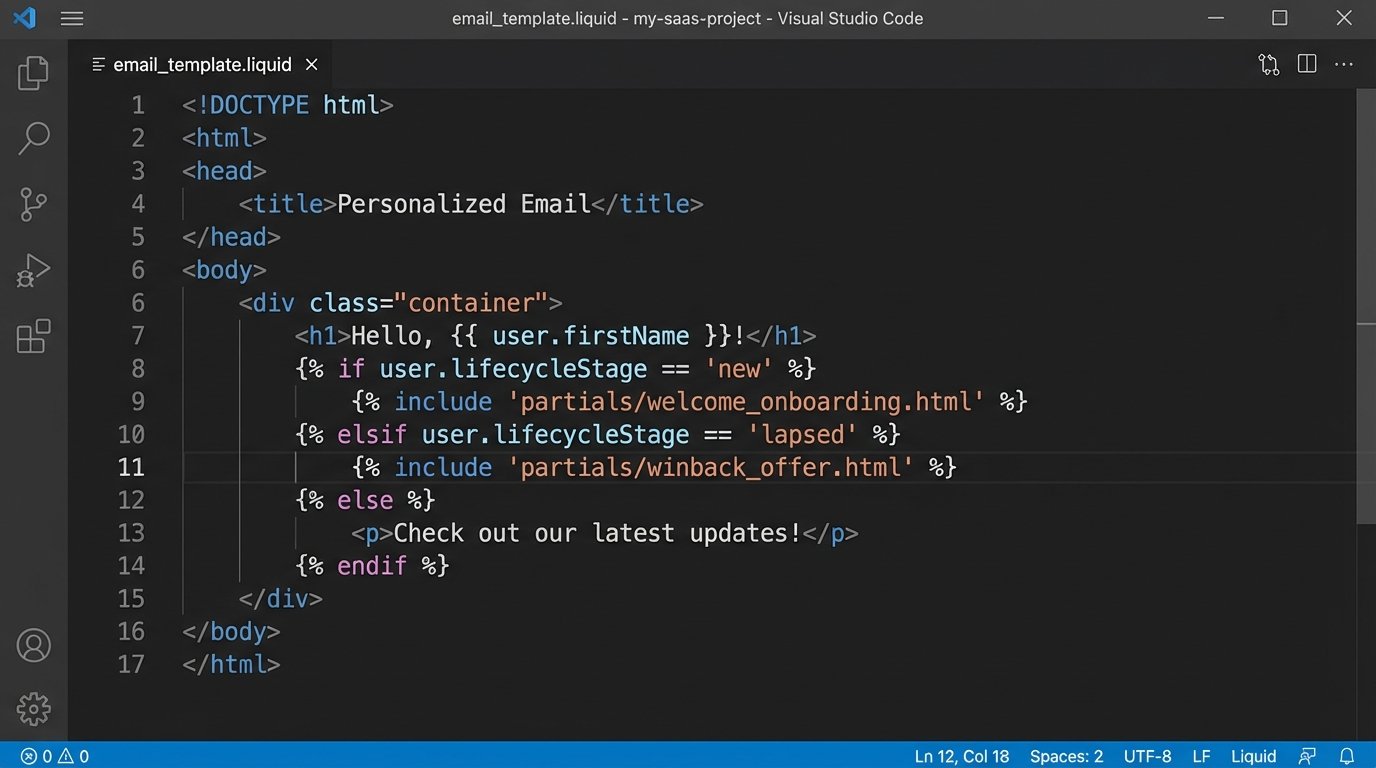
Pre-computation vs. On-the-Fly Generation
Assembling these complex, modular messages at the moment of send can be slow. If the logic requires multiple data lookups, it can bottleneck your entire send pipeline. This is shoving a firehose of data through a needle.
A better pattern for non-transactional sends is pre-computation. A nightly or hourly job can pre-generate the full message body for users in common segments and store it in a cache like Redis or even as a field on the user profile itself. When it’s time to send, the system just pulls the pre-rendered payload. This shifts the computational load from the critical send window to a less sensitive time.
This is a classic speed versus data freshness problem. The pre-rendered content might be a few hours stale, but it allows you to send millions of highly complex messages without your send infrastructure catching fire. For a weekly newsletter, that’s an acceptable compromise.
You Can’t Manually Test a Million Variations
The idea of QA’ing personalized content by sending “test emails” is absurd at scale. You cannot manually check all the permutations of your dynamic logic. If you have five conditional blocks, each with two variations, you already have 32 possible message combinations. It’s not scalable.
The only sane approach is to unit test your templating logic. You need a testing framework where you can feed mock user data objects into your template renderer and assert the expected output. You create mock objects for your key segments: the new user, the lapsed user, the user with missing data, the user from a specific country.
Isolating Logic from Presentation
Your tests shouldn’t be checking HTML rendering. They should be checking logic. Did the correct content block get selected? Did the fallback logic trigger when a key was null? The test runner should be able to take a template file and a JSON object and spit out the rendered text, which your test can then check against an expected string.
This separates the engineering responsibility from the marketing responsibility. The engineers guarantee the logic works as designed with a suite of automated tests. The marketing team is responsible for ensuring the content within each individual block is correct. This division of labor is the only way to maintain velocity without shipping broken messages.

Performance Is a Feature, Not an Afterthought
Every decision in personalization has a performance cost. Every additional data point you want to merge might require another API call. Each segment you check in your conditional logic adds processing overhead. At a small scale, this is unnoticeable. When you’re trying to send 10 million emails in an hour, those milliseconds add up to a system-wide collapse.
We enforce a “personalization budget” for our campaigns. A high-priority transactional message, like a password reset, gets the highest budget. It can make real-time API calls to get the freshest possible data. A bulk promotional send gets a very low budget. It must rely on cached data that’s at least an hour old, and its template is restricted to a few simple conditional blocks. This tiered approach prevents a low-priority campaign from DDoSing our own internal services.
Cache Everything Aggressively
The data used for personalization is often repetitive. The “top 10 best-selling products” don’t change every second. User segment assignments are not in constant flux. Any data that can be cached, should be cached. A simple Redis layer between your message generator and your primary databases can absorb a massive amount of load.
The key is setting intelligent TTLs (Time to Live) on your cache keys. User profile data might be cached for 15 minutes. Product catalog data might be cached for an hour. Global site configuration data could be cached for a day. Fine-tuning these values requires monitoring, but it’s the most effective way to achieve personalization at scale without buying a data center’s worth of hardware.