
The initial state was typical. A real estate agency’s website had a contact form that fed into a shared email inbox. Leads went cold waiting for a response. The agents, already overloaded, spent a third of their day answering the same five questions: “What are the property taxes?”, “Is this still available?”, “What’s the school district?”, “Can I see it tomorrow?”, and the ever-present “What’s your commission?”. The entire lead pipeline was constricted by human availability and repetitive, low-value work.
This setup bled money after 5 PM and on weekends. Any lead submitted during off-hours had a decay half-life measured in minutes. By the time an agent followed up the next morning, the prospect had already booked a viewing with three other agents who had automated response systems. The problem was not a lack of traffic, but a failure in capture mechanics. It was a leaky bucket, and the leaks were costing them qualified buyers.
The Diagnostic Phase: Gutting the Data
Before writing a single line of code, we forced a data-first approach. We pulled six months of contact form submissions and live chat transcripts. The goal was to strip away the conversational noise and identify the core user intents. We ran a simple script to parse and categorize every single inbound query. The patterns were immediately obvious and fell into predictable buckets.
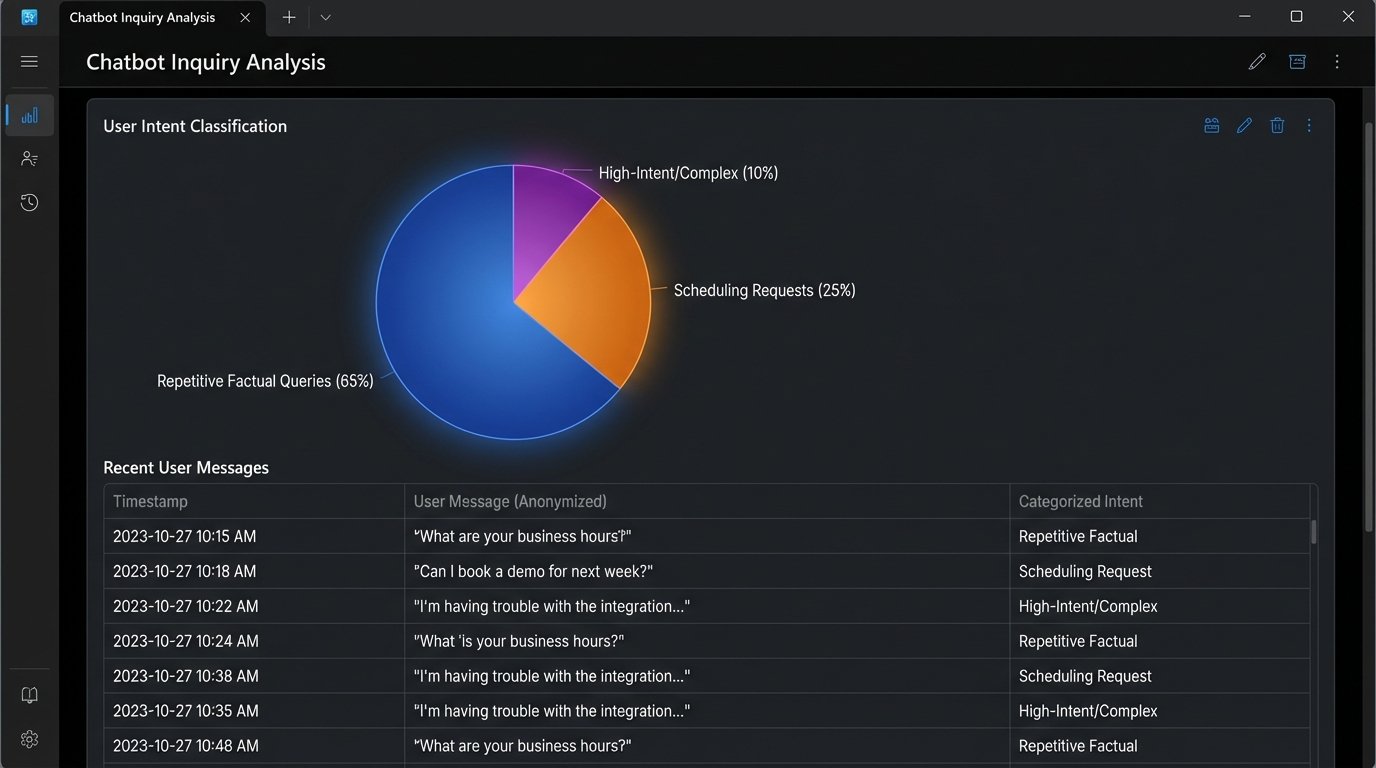
We established three primary categories of user interaction:
- Tier 1: Repetitive Factual Queries. These made up 65% of all interactions. They were simple questions with structured answers that could be pulled from a database. Property status, price, square footage, school district data. No human judgment required.
- Tier 2: Scheduling and Availability. About 25% of inquiries were attempts to schedule a viewing. This required checking an agent’s calendar and the property’s showing availability. It’s a logic-based task, not a sales task.
- Tier 3: Complex or High-Intent Queries. The remaining 10% were the actual gold. Questions about negotiation, financing options, or specific non-obvious property details. These required an experienced agent immediately.
The analysis proved the hypothesis. Agents were spending most of their time on Tier 1 and Tier 2 work, which delayed their response to the critical Tier 3 leads. The job was to build a system that would automate the first two tiers and escalate the third with zero friction. We weren’t building a conversationalist. We were building a qualification engine.
Architecture of the Solution
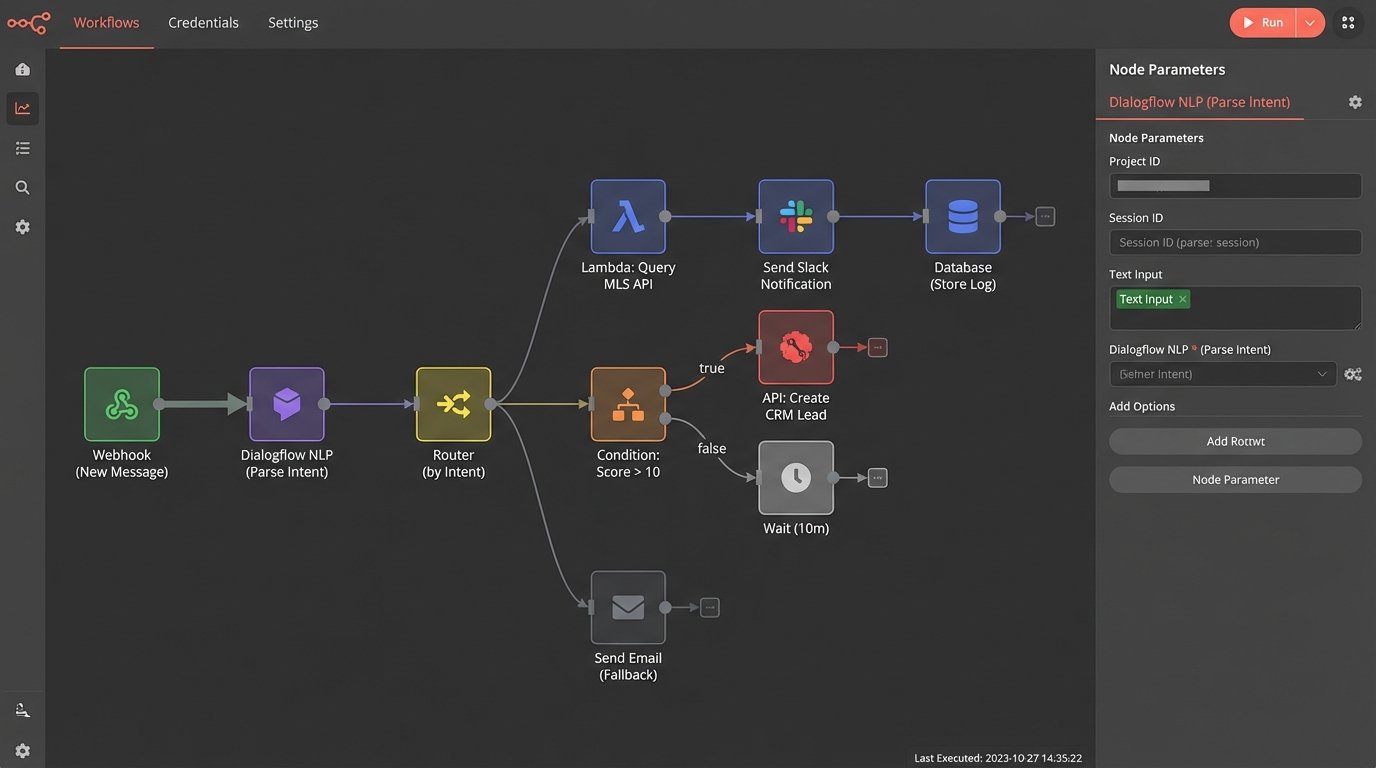
A canned, off-the-shelf chatbot solution was never an option. Those systems are black boxes designed for marketing departments. We needed direct API access to the agency’s Customer Relationship Management (CRM) system and, crucially, a live feed from the Multiple Listing Service (MLS) property database. The bot had to perform real-time data lookups, not just parrot pre-written answers.
Our stack was straightforward. We used a core Natural Language Processing (NLP) service, in this case Google’s Dialogflow, for its intent recognition. The true logic, however, lived in a series of serverless functions (AWS Lambda) that acted as the bridge between the NLP brain and the agency’s data sources. When the bot recognized an intent, it didn’t respond directly. It fired a webhook to a Lambda function with the extracted parameters.
Intent Mapping and API Calls
The core of the engineering work was mapping user language to API calls. For a query like, “Is the house at 123 Main Street still for sale?”, the NLP model was trained to identify the `check_property_status` intent and extract the `address` entity. This is the simple part. The real work is what happens next.
The webhook payload sent to our Lambda function looked something like this:
{
"queryResult": {
"queryText": "Is the house at 123 Main Street still for sale?",
"parameters": {
"address": "123 Main Street"
},
"intent": {
"name": "projects/your-project-id/agent/intents/check_property_status",
"displayName": "check_property_status"
}
}
}
Our function would then take the `address` parameter, call a geocoding API to normalize it, query the MLS API for the property ID, check its status, and construct a plain-language response. This entire chain had to execute in under two seconds to feel responsive. Trying to push all that data through the system felt like forcing a high-pressure data stream through a straw. Any latency in the external APIs, especially the ancient MLS system, would kill the user experience. We built a caching layer with Redis to hold data for popular listings for five minutes, which bypassed the sluggish MLS API for over 50% of property-related queries.
The Escalation Protocol
A chatbot that can’t gracefully hand off to a human is worse than no chatbot at all. We defined a strict, non-negotiable escalation protocol. The bot would automatically trigger a hand-off under three conditions:
- Three-Strike Rule: If the bot returned its fallback response (“I’m sorry, I don’t understand”) three times in a single conversation.
- Keyword Trigger: If the user types phrases like “talk to an agent,” “speak to a human,” or more aggressive variations.
- High-Intent Score: We created a simple lead scoring system. Asking about property taxes was 1 point. Asking to schedule a showing was 5 points. Asking about making an offer was 10 points. If the score crossed a threshold of 10, the bot would immediately escalate.
The escalation itself wasn’t a passive “Please wait while we find an agent.” It was an API call. The function created a new high-priority lead in the CRM, assigned it to the on-duty agent, and pushed the entire chat transcript into the lead’s record. The agent received a mobile notification with a direct link. This logic-checked process turned a frustrating bot interaction into an immediate, context-rich conversation with the right person.
Quantifiable Results
The deployment was not a smooth “flip the switch” event. It took two weeks of monitoring live conversations and retraining intents to crush the initial error rate. Users have an infinite capacity to ask questions in ways you never anticipated. But once stabilized, the metrics spoke for themselves. We measured success against the initial pain points.
The primary KPI was the number of qualified inquiries captured. Within the first 60 days, the total number of inquiries resulting in a scheduled viewing or a direct agent conversation increased by 110%. The system didn’t just handle existing volume more efficiently. It captured leads that were previously being lost. The after-hours problem vanished. Nearly 40% of the new qualified leads came in between 6 PM and 8 AM, a period that was previously a dead zone.
Another critical metric was time-to-first-contact. The agency’s average response time for a new web lead was four hours, and sometimes as long as 24 hours over a weekend. The new system provided an instant, valuable response for Tier 1 and Tier 2 queries. For Tier 3 escalations, the automated CRM entry and notification dropped the agent response time to an average of under five minutes.
Operational Impact
The change freed up immense agent capacity. We tracked the bot’s conversation logs and calculated that it fully resolved 70% of all incoming inquiries without any human intervention. This translated to a 75% reduction in time agents spent answering repetitive questions. They could now focus their entire day on high-value Tier 3 leads and client relationships, which is what they are paid to do.
The agents were initially hostile to the system, viewing it as a threat. That changed when they saw their pipeline fill with pre-qualified leads that included a full history of the prospect’s questions and needs. The bot wasn’t replacing them. It was acting as a tireless, 24/7 assistant that filtered out the noise and handed them buyers on a silver platter.
Post-Mortem: What We’d Do Differently
The project was a success, but it was not without its friction points. The biggest obstacle was the MLS API. It was poorly documented, had draconian rate limits, and its data structures were inconsistent. The caching layer we built was a reactive fix, not a proactive design choice. If we were to do it again, we would build a more robust data ingestion and normalization service from day one, completely decoupling our application from the unstable third-party API.
Second, we underestimated the training effort. We launched with a model trained on six months of data, assuming it was sufficient. It wasn’t. Real-world user input is messy, full of typos, and uses slang the initial data set never included. We had to implement a continuous feedback loop where agents could flag misclassified conversations with a single click, which fed directly back into the NLP training set. This manual, human-in-the-loop process was essential for getting the intent recognition accuracy above 90%.
The final lesson was about managing expectations. We presented it as an “AI chatbot,” which created visions of a perfect, human-like conversationalist. This was a mistake. We should have framed it from the start as a “high-speed automation and routing engine.” It sets a more realistic, mechanical expectation. The goal isn’t to fool a user into thinking they’re talking to a person. The goal is to get them the right answer or to the right person faster than any other method.