
The Problem: A Dispatch Desk Bleeding Payroll on Repetitive Calls
Our client, a mid-sized logistics firm, had a fundamental operational bottleneck. Their dispatch desk was a glorified answering service. The team spent an estimated 65% of its time fielding the same question: “Where is my shipment?”. This wasn’t just inefficient. It was a direct drain on payroll, created a high-stress environment, and led to inevitable data entry errors when dispatchers misheard a PRO number or keyed a delivery address incorrectly into the Transportation Management System (TMS).
Their existing IVR system was a relic. It presented a numeric menu that frustrated callers and almost always resulted in them mashing ‘0’ to reach a human. The core issue was simple. The system was dumb. It couldn’t understand intent or extract critical data from a conversation. We weren’t tasked with an upgrade. We were tasked with a gut-and-replace operation.
Defining the Failure Points
Before architecting a solution, we had to map the specific points of failure. The primary pain points were not technological but human. Dispatchers were context-switching constantly between answering calls, updating the TMS, and handling actual escalations like damaged freight or driver issues. This constant cognitive load was the direct cause of errors that cost the company real money in miss-deliveries and client dissatisfaction.
The business objectives were clear. We needed to automate the high-volume, low-complexity inbound calls. We had to design a system that could understand a caller’s request, query the internal TMS for shipment status, and provide a clear, accurate answer without any human touching the process. This would free up the dispatchers to focus on the complex, high-value problems that actually required a human brain.
The Architecture: Bridging Voice, NLP, and a Legacy TMS
We designed a service-oriented architecture to intercept and process calls. The goal was to build a pipeline that could ingest raw audio, strip out the meaning, execute a database lookup, and generate a spoken response. Each component was chosen for a specific function, with the understanding that the entire chain is only as fast as its slowest link.
The core components of the stack included:
- Voice Gateway: We used Twilio Programmable Voice to grab the inbound calls from their SIP trunk. This gave us a programmable entry point and spared us the headache of messing with their on-premise PBX hardware.
- Speech-to-Text (STT): Google’s Speech-to-Text API was our initial choice, specifically for its model adaptation features. We knew we’d need to train it on logistics-specific jargon like “bill of lading” and alphanumeric tracking numbers.
- Natural Language Understanding (NLU): Google Dialogflow served as the brain. Its job was to perform two critical tasks. It had to classify the caller’s intent (e.g., `check_status`, `request_pod`, `escalate_to_human`) and extract the necessary entities (`tracking_number`, `customer_id`).
- Integration Service: A Python Flask application was built to act as the central nervous system. It received the webhook from Dialogflow, parsed the extracted entities, and then constructed the appropriate query against the client’s internal TMS API.
- Text-to-Speech (TTS): We chose Amazon Polly for the voice synthesis. Its neural voices sounded less robotic, which was a small but important factor in preventing callers from immediately demanding a human agent.
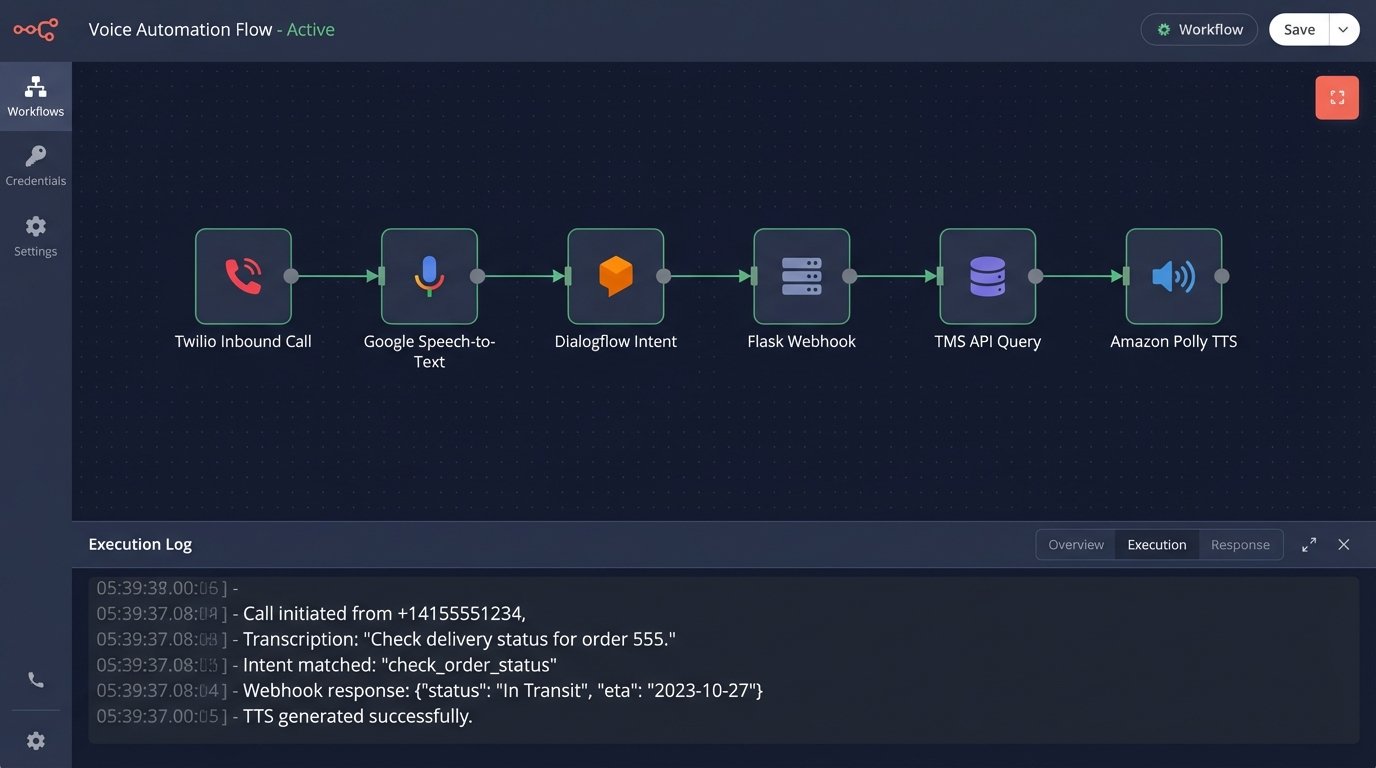
Orchestrating the Call Flow
The logic flow is straightforward on paper but gets complicated in practice. An inbound call hits Twilio, which begins streaming the audio to our STT service in real time. The transcribed text is fed to Dialogflow. If Dialogflow identifies an intent with high confidence and extracts all required entities, it fires a webhook to our Flask application.
This Flask app is the real workhorse. It contains the business logic to sanitize the extracted tracking number, authenticate against the TMS API, and pull the relevant shipment data. It then formats a human-readable response string and passes it to the TTS service, which generates the audio that Twilio plays back to the caller. If at any point the confidence score is too low or the caller says “agent”, the logic immediately bridges the call to the dispatch hunt group.
Here is a simplified look at the webhook handler logic within the Flask service. It shows how we map a detected intent to a specific function that handles the TMS lookup.
from flask import Flask, request, jsonify
app = Flask(__name__)
def handle_status_check(tracking_number):
# This function contains the logic to query the TMS API
# It returns a string like "Your shipment is currently in transit in Dallas."
response_text = query_tms_by_tracking(tracking_number)
return response_text
def handle_pod_request(tracking_number):
# Logic to fetch Proof of Delivery and email it
response_text = "I've sent the proof of delivery to the email on file."
return response_text
@app.route('/webhook', methods=['POST'])
def dialogflow_webhook():
req = request.get_json(silent=True, force=True)
intent = req.get('queryResult').get('intent').get('displayName')
params = req.get('queryResult').get('parameters')
if intent == 'check_status':
tracking_num = params.get('tracking_number')
fulfillment_text = handle_status_check(tracking_num)
elif intent == 'request_pod':
tracking_num = params.get('tracking_number')
fulfillment_text = handle_pod_request(tracking_num)
else:
fulfillment_text = "I'm not sure how to handle that. Let me get an agent."
return jsonify({'fulfillmentText': fulfillment_text})
if __name__ == '__main__':
app.run(debug=True)
This structure kept the intent routing clean and made it easy to add new automated tasks later without rewriting the core application.
Hurdles and Forced Corrections
The initial deployment was not smooth. Our biggest challenge was STT accuracy. Standard transcription models choked on the mix of letters and numbers in tracking codes and mangled industry acronyms. We had to spend two weeks building a custom vocabulary model, feeding it thousands of examples of our client’s specific jargon. This was a slow, manual process of tuning and testing.
The second major problem was latency. The full round trip from the caller speaking to hearing a response was initially over four seconds. This is an eternity on a phone call. We were trying to shove a firehose of API calls through the needle of an acceptable response time. The fix involved adding a caching layer with Redis for frequently requested, non-volatile data and forcing the internal dev team to create a new bulk endpoint for the TMS instead of us making multiple, chatty API calls per request.
Finally, we had to perfect the fallback logic. A failed automation that dumps a caller back into a generic queue is useless. We configured the system to pass the entire call transcript and the NLU’s best guess of intent to the agent’s screen when a transfer occurred. This meant the agent saw “Caller asked for status on PRO #12345, system failed to find it” before they even said hello. No more asking the customer to repeat themselves.

Results: Measurable Impact on Operations
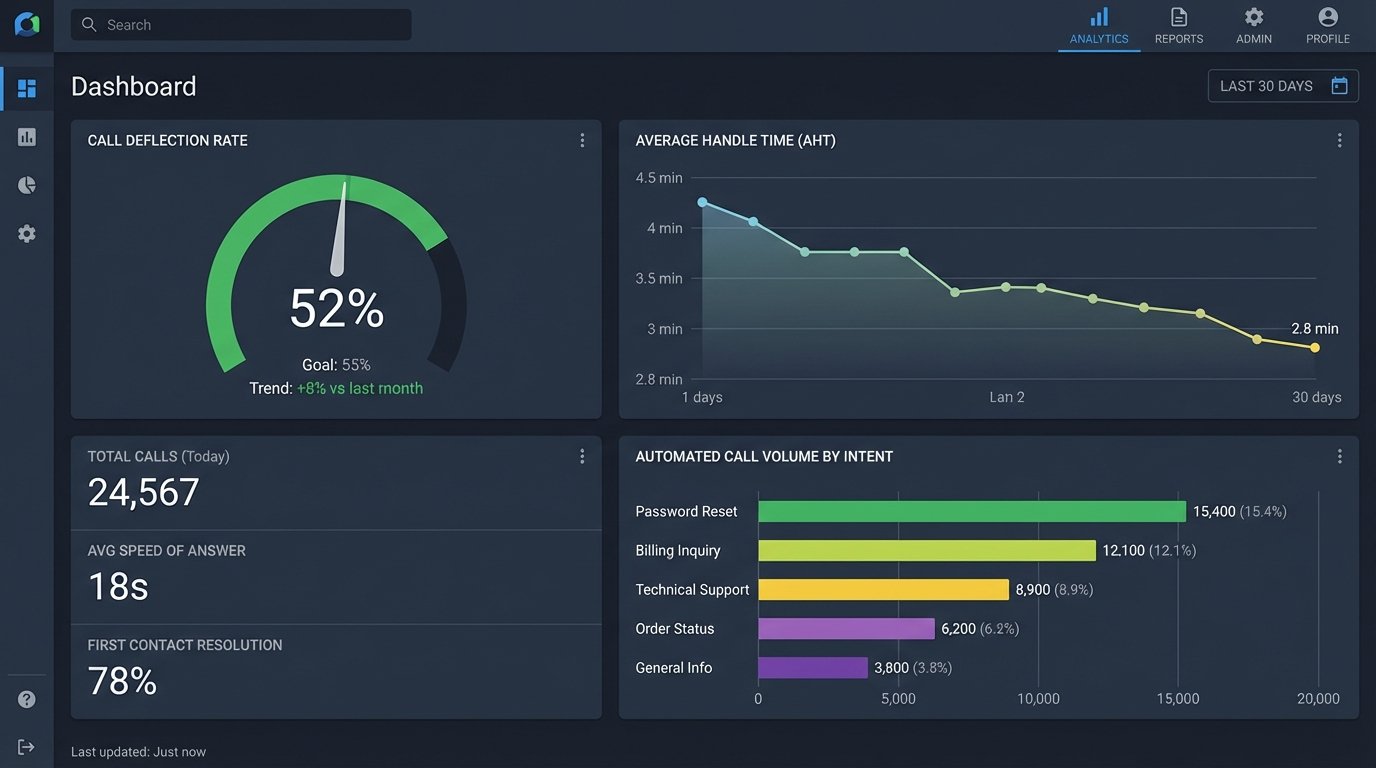
The system’s performance was tracked against two primary Key Performance Indicators. The first was the Call Deflection Rate, the percentage of inbound calls fully handled by the automation. The second was the impact on Average Handle Time for the calls that still required a human dispatcher.
Within the first month of full operation, we achieved a 31% call deflection rate. After three months of continuous tuning of the NLU intents and STT model, that number stabilized at 52%. More than half of all inbound status check calls were being resolved without ever reaching a human agent. This was a direct and immediate reduction in the workload of the dispatch team.
The impact on the remaining calls was just as significant. Because the automated system filtered out the simple, repetitive queries, the calls that reached the dispatchers were, by definition, more complex. Despite this, the Average Handle Time for human agents dropped from 4.5 minutes to 2.8 minutes. This was a direct result of the screen-pop context transfer. Agents spent less time on discovery and more time on problem-solving.
Financially, the return on investment was calculated based on salary savings versus API and development costs. The client was able to reallocate two full-time dispatchers to proactive roles, focusing on customer relationship management for their top-tier accounts, rather than hiring more staff to handle increasing call volume. The entire project paid for itself in under seven months.
Beyond the Numbers
One of the most valuable outcomes was the reduction in data entry errors. The automated system either found the correct shipment in the TMS or it failed cleanly. There was no “fat-fingering” a tracking number or mishearing an address. This improved data integrity within their core system, a benefit the client hadn’t even considered initially.
The project served as a hard lesson in the realities of voice automation. The technology is powerful, but it is not a plug-and-play solution. The real cost isn’t the API fees. It’s the painstaking work of model tuning, latency optimization, and designing intelligent failure paths. Without that, you’re just building a more expensive version of the dumb IVR you replaced.