
Stop Calling Them Assistants. They’re Liability Engines.
The marketing departments are working overtime. Every new real estate tech platform now boasts an “AI assistant,” a chatbot designed to engage leads and answer questions 24/7. The pitch is seductive: automate client communication, qualify buyers at scale, and free up agents to close deals. The reality is that we are deploying unauditable black boxes into one of the most litigious and regulated industries in the country.
This conversation is not about sentience or some dystopian future. It is about present-day system architecture, data provenance, and the legal tripwires we are ignoring for the sake of speed. We’re handing generative language models the keys to client interaction without first checking if they know how to drive. The ethical problem is not that the AI might become biased; it’s that we are building it from biased parts and giving it no brakes.
The Data Ingestion Problem is a Legal Problem
Every AI model is a reflection of the data it consumed. In real estate, that data is a toxic stew of MLS feeds, outdated property descriptions, public records with known inaccuracies, and scraped forum comments. We ingest this unstructured mess, tokenize it, and feed it into a model, expecting legally compliant output. The system has no concept of the Fair Housing Act. It only understands statistical relationships between words.
An AI might learn from a decade of old listings that phrases like “quiet neighborhood” or “great for families” correlate highly with successful sales. The model doesn’t know these are coded terms that can lead to steering claims. It just identifies a pattern and replicates it to satisfy a user’s prompt. You are asking a language model to act as a fiduciary after feeding it a diet of decades-old marketing copy.
This is a data integrity failure before it’s an ethical one.
Generative Models and the Hallucination Liability
Older chatbots were simple, deterministic systems. They operated on keyword matching and decision trees. If a user typed “property taxes,” the bot would return a pre-written, agent-approved block of text. The output was predictable and auditable. You could look at the logs and see exactly why it gave a specific answer. This is not how generative AI works.
Large Language Models (LLMs) are probabilistic. They generate responses word by word, calculating the most likely next word based on the input prompt and its training data. This process can lead to “hallucinations,” where the model states a falsehood with complete confidence. It might confidently declare a 15-year-old roof is “brand new” because it conflated data from an old listing with a new query. It might invent HOA amenities that don’t exist.
Who is liable when a buyer makes a decision based on this false information? The agent. The brokerage. You cannot defend your case by saying “the AI made it up.” The output of the tool is legally indistinguishable from the speech of the agent who deployed it. The lack of explainability means you can’t even produce a coherent log to show a regulator how the error occurred.
Code Is Not a Shield for Fair Housing Violations
The biggest disconnect is between the engineering task and the legal reality. We can build a profile of a potential buyer based on their queries, saved properties, and stated preferences. This is standard practice for personalization. The goal is to surface relevant listings faster. But in real estate, the line between personalization and discriminatory steering is razor-thin and aggressively enforced.
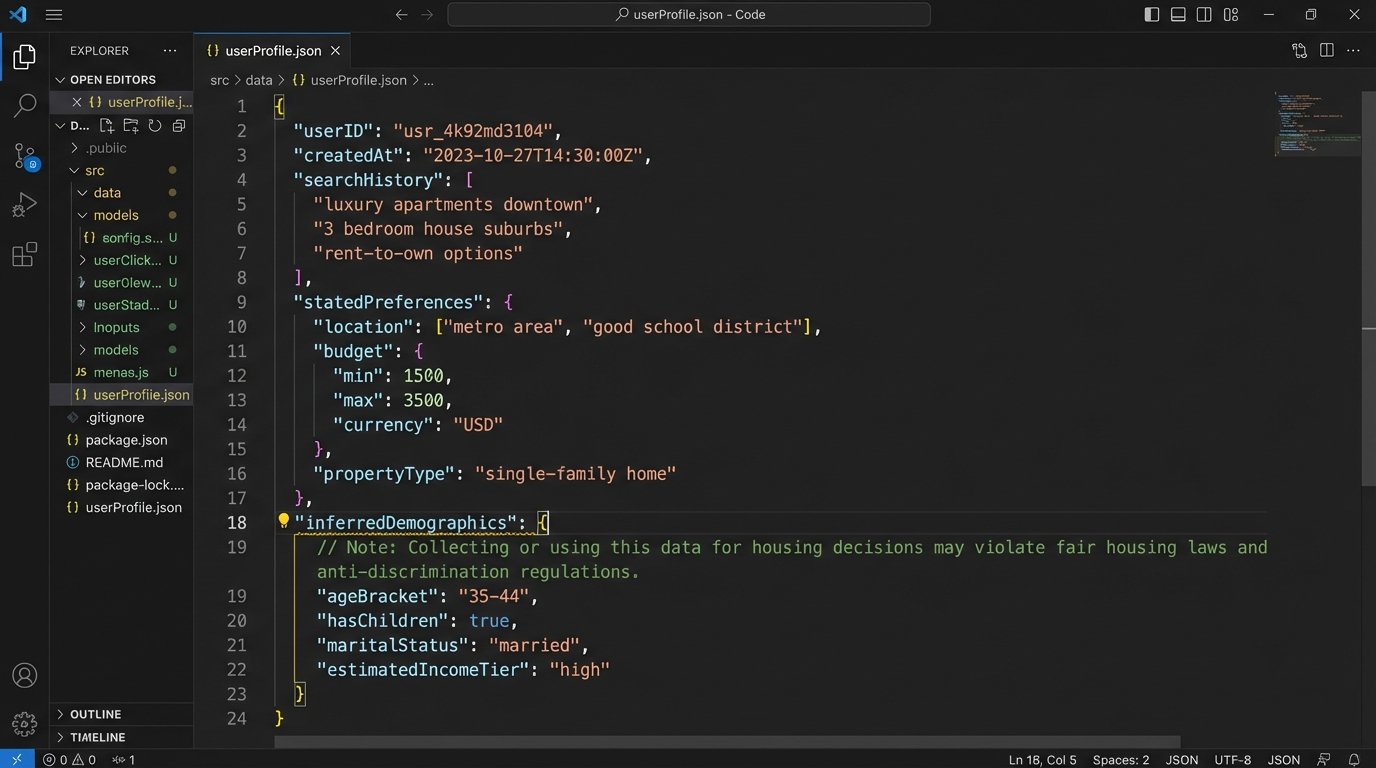
Consider a simplified user profile object:
{
"userID": "9a8b7c6d",
"searchHistory": ["downtown condo", "2-bedroom apartment", "properties near City Park"],
"savedProperties": [12345, 67890],
"statedPreferences": {
"priceMax": 500000,
"bedrooms": 2,
"keywords": ["modern kitchen", "good schools", "safe neighborhood"]
},
"inferredDemographics": { // This is the danger zone
"ageBracket": "30-40",
"hasChildren": "probable"
}
}
The model might correlate the “good schools” keyword and the inferred presence of children with historical data showing that families with those attributes bought homes in a specific suburban school district. So, it prioritizes showing listings from that district. The system isn’t programmed to be biased against other areas. It is programmed to find the path of least resistance to a match based on the data it was given. The result, however, is a potential Fair Housing Act violation by steering a user toward one neighborhood and away from another based on familial status.
You can’t A/B test your way out of a federal investigation.
A More Defensible Architecture: Grounding and Gating
Chasing the dream of a fully autonomous, human-like conversational AI in this industry is a fool’s errand. A more mature, defensible architecture sacrifices conversational flair for factual accuracy and legal compliance. This means abandoning the free-wheeling generative approach for a more constrained system.
The first component is Retrieval-Augmented Generation (RAG). Instead of letting the LLM answer questions from its vast, messy training data, you force it to retrieve information from a curated, up-to-date knowledge base first. This knowledge base should contain only current MLS data, disclosure documents, and brokerage-approved marketing language. The AI is not allowed to answer a question unless it can find the source material in this vetted vector database. It can’t just invent an answer about the age of the HVAC system; it must pull that specific data point from the current listing.
The second component is a logic gate on the output. Before the AI’s generated response is sent to the user, it must pass through a validation layer. This layer uses a combination of pattern matching and simpler AI models to scan the response for red flags. Does it contain sensitive keywords related to protected classes? Does it make a definitive statement about the property’s condition or future value? If a red flag is triggered, the system can either block the response, substitute it with a pre-canned compliant answer, or flag it for immediate human agent review.
This approach is slower. It requires significant upfront work in building and maintaining the knowledge base. It is the opposite of the plug-and-play solutions being sold today. It is also the only way to build these tools without accepting massive, open-ended legal risk.
Governance is Not an Optional Add-On
The systems we build are direct extensions of the agent’s license. The idea that you can just connect a third-party API and absolve yourself of responsibility for its output is absurd. True data governance in this context means treating the AI’s knowledge base like a legal document. It requires a rigorous process for data hygiene.
This means stripping personally identifiable information (PII) from any data used for training or fine-tuning. It means building classifiers to scan old property descriptions for potentially problematic language and purging it before it ever reaches the model. It requires a clear chain of custody for every piece of data the AI is allowed to access. It’s about building a clean room for your data, not just pointing a firehose at the entire internet.
Most platforms ignore this. It’s expensive, and it slows down product development. It is also the single most important factor in determining whether your “AI assistant” is a useful tool or an engine for generating lawsuits.

The Human in the Loop is Not a Bug, It’s the Feature
We need to reframe our objective. The goal is not to replace the agent with a perfect chatbot. The goal is to build tools that augment the agent’s ability to perform their job in a compliant and effective way. These systems should be designed to handle the 80% of repetitive, low-risk queries while aggressively flagging the 20% that require nuanced, professional judgment.
An AI can schedule a showing. It can tell a user the square footage of a property by pulling from the MLS. It should not be giving advice about neighborhood character, opining on the quality of a school district, or interpreting the legalese of an inspection report. That is the agent’s job. That is what the license is for.
The ethical failure is in the framing. Vendors are selling “autonomy” and “automation.” What we should be building is “leverage” and “oversight.” The agent is the final checkpoint. Any system that tries to bypass that checkpoint is not just unethical; it’s a malpractice machine waiting to be switched on.