
The standard architecture for a “multilingual” AI assistant is a brittle lie. It’s almost always a monolingual English core with a translation API bolted onto the front and back ends. The user’s input gets translated to English, processed by the core logic, and the English response gets translated back into the user’s language. This is not a multilingual system. It’s a game of telephone with an API key.
This approach injects two points of failure and significant latency before your actual logic even fires. You’re at the mercy of the translation service’s accuracy, its rate limits, and its monthly bill.
The Translation Layer Fallacy
The core defect of the translation-sandwich model is semantic corruption. Nuance, intent, and cultural context are the first casualties. An idiom in Spanish gets flattened into a literal, nonsensical phrase in English. The LLM then receives this mangled input and dutifully generates a response to a question nobody actually asked. The system then translates this perfectly logical but contextually wrong answer back into broken Spanish.
You have now successfully confused the user in their own language.
Consider the data structures. A simple entity like a date, `10/11/12`, is ambiguous without a locale. A translation API might pass the string through literally, leaving your English-centric backend to guess if it’s October 11th or November 10th. A financial amount like `1.234,56` will break parsers expecting a period as the decimal separator. The translation layer does not and cannot solve data localization. It just passes the grenade down the line.
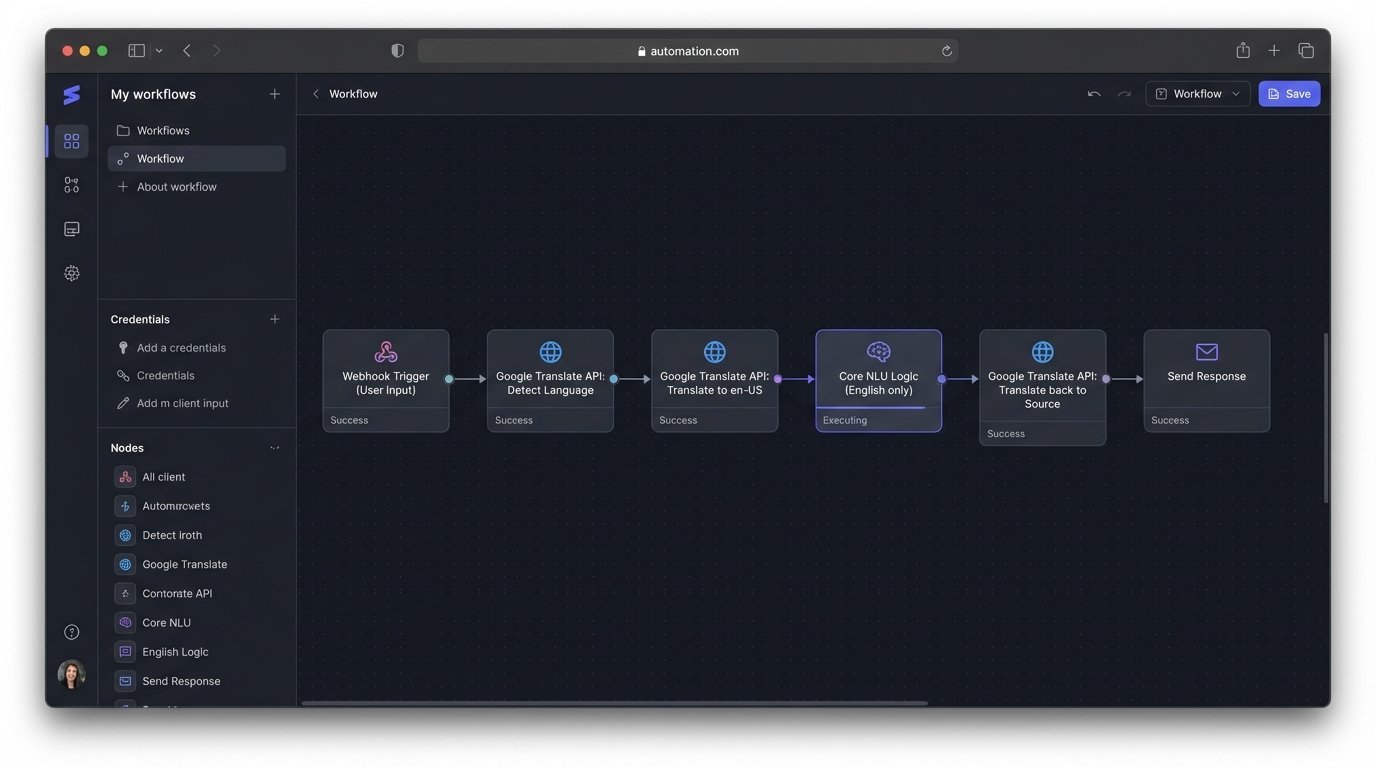
Debugging this chain is a nightmare. The user reports a bad answer. Is the error in the initial translation? Is your NLU misinterpreting the translated garbage? Is the LLM hallucinating? Or did the final translation back to the source language introduce the error? You have to instrument and log at four distinct points for a single user turn, burning through log storage and sanity.
This entire setup is a technical debt magnet.
A Fork in the Road: Silos or a Monolith
Getting this right means gutting the translation layer and architecting for language from the foundation. This leaves two primary paths, neither of which is cheap or easy.
The first option is the siloed approach: deploying and maintaining a completely separate, fine-tuned model for each target language. A German-language bot runs on a model fine-tuned exclusively on German support conversations. A Japanese bot runs on a Japanese model. This gives you maximum accuracy and cultural resonance for each market. Your German entity extractors will correctly parse German addresses, and your Japanese bot will understand the appropriate levels of politeness.
The cost is operational agony. You are now responsible for N separate deployment pipelines, N monitoring dashboards, and N fine-tuning datasets. A logic update to your core `reset_password` intent must be propagated, tested, and deployed across every single language silo. It multiplies infrastructure and headcount.
The second option is the multilingual monolith. You use a single, massive foundational model trained on a multilingual corpus, like GPT-4 or Gemini. In theory, this model understands multiple languages natively. You feed it Spanish, it gives you Spanish back. No external translation hops. This simplifies the architecture down to a single endpoint and a single model to manage.
This path is a wallet-drainer. The inference costs for these flagship models are substantial, and performance can be uneven. Many are heavily English-weighted, meaning their proficiency in languages like Thai or Hungarian might be brittle. You’re also handing over control. If the model’s German output suddenly degrades after a provider-side update, your options are to file a support ticket and wait.
Engineering Beyond Translation
A functional multilingual system requires you to think about intent management differently. You cannot have language-specific intents like `check_order_status_EN` and `check_order_status_DE`. You need a single, canonical intent, `order.status.check`, mapped to training phrases from all supported languages. The NLU layer’s job is to correctly map a user’s utterance, regardless of language, to that one canonical intent.
This forces a separation of language processing from business logic. The code that queries the order database doesn’t care if the user asked in Portuguese or Korean. It only cares that it received the `order.status.check` intent and a validated `order_id` entity.
Structuring Multilingual Responses
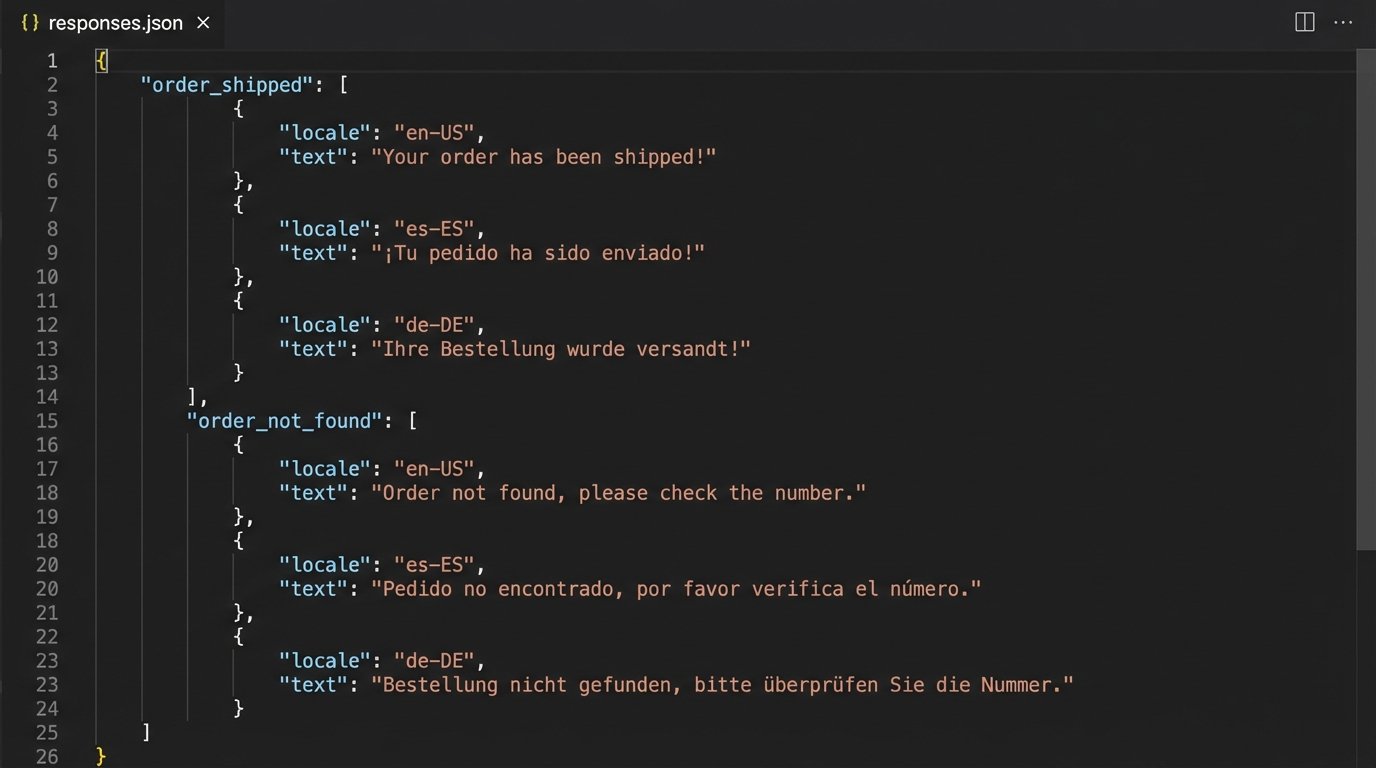
Static responses must be managed outside the model. Instead of hardcoding “Your order has shipped” into your application logic, you fetch a response string from a content management system or a simple key-value store based on the detected locale.
A simple JSON structure for this is often sufficient. The application logic requests the `response.order_shipped` key and provides the `de-DE` locale, and the CMS returns the correct German string.
{
"responses": {
"order_shipped": [
{
"locale": "en-US",
"text": "Your order #{order_id} has shipped. It should arrive by {delivery_date}."
},
{
"locale": "es-ES",
"text": "Tu pedido #{order_id} ha sido enviado. Debería llegar antes del {delivery_date}."
},
{
"locale": "de-DE",
"text": "Ihre Bestellung #{order_id} wurde versandt. Sie sollte bis zum {delivery_date} ankommen."
}
],
"order_not_found": [
{
"locale": "en-US",
"text": "Sorry, I couldn't find order number #{order_id}."
},
{
"locale": "es-ES",
"text": "Lo siento, no pude encontrar el pedido número #{order_id}."
},
{
"locale": "de-DE",
"text": "Entschuldigung, ich konnte die Bestellnummer #{order_id} nicht finden."
}
]
}
}
This keeps application code clean of linguistic specifics and allows non-engineers to manage and add translations without requiring a new code deployment. It’s a basic principle, but it’s frequently ignored when teams are rushing to tack on another language.
The Unspoken Data Problem
Building a robust system, especially with the siloed fine-tuning approach, depends entirely on the quality of your data pipeline. You need clean, domain-specific, parallel corpora. This means sets of data where utterance `A` in English has a direct and accurate equivalent `B` in German. This data is not easy to acquire. Scraping it is unreliable, and buying it is expensive.
Trying to fine-tune a model on unvetted, multilingual web-scraped data is like trying to build a cleanroom with mud bricks. You will spend more time identifying and stripping out the noise, biases, and outright junk from your training set than you will on the modeling itself. The model will simply learn to replicate the low-quality patterns you fed it.
A proper pipeline involves sourcing, cleaning, human validation, and continuous augmentation. It’s a significant, ongoing effort that most project plans conveniently omit.

The choice is not about which translation API is fastest. That is the wrong question. The real work is in deciding whether to stomach the operational complexity of language-specific models or the cost and opacity of a massive multilingual one. Both require a fundamental architectural commitment to handling linguistic diversity at the core, not as an afterthought.
Stop gluing translation APIs to your bots. Build for linguistic diversity from the core, or prepare to explain broken conversations to your global customers.