
The sales pitch for chatbots is always the same: 24/7 customer support that cuts operational costs. The reality is that most are just interactive FAQ documents. They crumble the moment a user asks a state-dependent question. “What’s the status of my order?” or “Can I get a copy of my last invoice?” sends the bot into its pre-programmed apology loop, frustrating the user and creating a support ticket for a human to handle the next morning. This defeats the entire purpose.
This failure isn’t a fault of the AI’s language model. It’s an architectural flaw. The chatbot is a disconnected island, completely ignorant of the backend systems that hold the actual answers. To fix this, you have to build a bridge from the bot’s intent recognition engine to your core business logic. Anything less is just a digital receptionist that can only say, “Sorry, everyone’s gone home.”
Diagnosing the Disconnect: Intent vs. Information
A user typing “Where is order 12345?” isn’t just making small talk. They are issuing a command with three distinct parts: the intent (query order status), the primary entity (order), and the specific identifier (12345). A standard chatbot can typically identify the intent. It sees the word “order” and matches it to a pre-defined flow. The problem is that it has nowhere to go with the identifier. The bot has no access to the order management system (OMS) where order 12345 actually lives.
Solving this requires more than better NLP training. It requires a fundamental shift from a content-retrieval model to a data-execution model. The chatbot must be given the authority and the technical pathway to not just find information, but to execute queries against live production systems. This means treating the chatbot as a first-class application front-end, with all the security and integration headaches that implies.
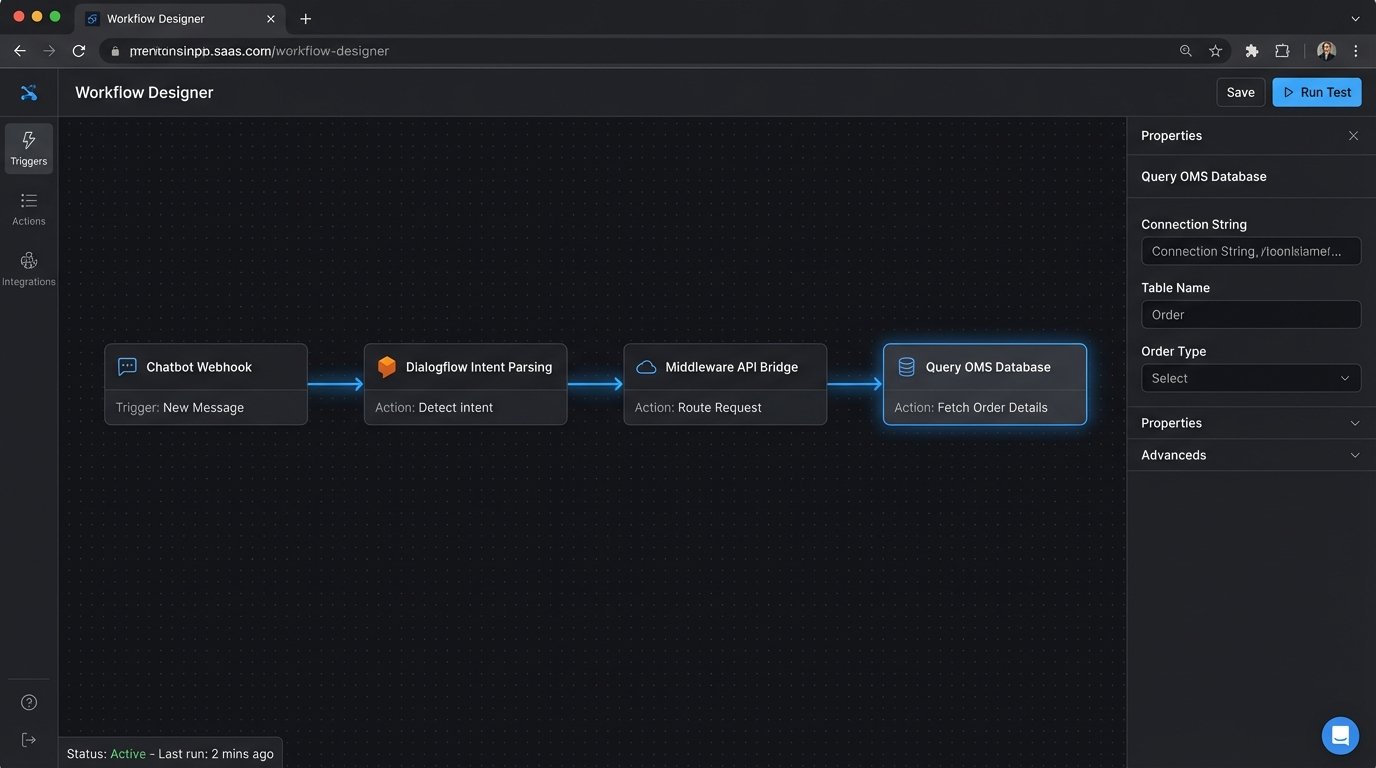
The Architectural Fix: A Three-Layer System
A resilient, state-aware chatbot architecture is not a single product. It is a system composed of three distinct layers that must work in sequence. Failure to properly isolate these layers results in a brittle, unmaintainable mess.
- Layer 1: The NLP Front Door. This is your chatbot platform (like Google Dialogflow, Microsoft Bot Framework, Rasa). Its sole job is to ingest raw user text, recognize the intent, and extract key entities. It should do no business logic. It is a translation service, converting unstructured human language into a structured JSON object.
- Layer 2: The Middleware Bridge. This is the core of the solution. It’s a dedicated API service that sits between the NLP layer and your internal systems. This bridge receives the structured intent from the chatbot, performs authentication checks, and then makes the necessary calls to backend services. It is the central nervous system of the operation.
- Layer 3: The Internal Systems of Record. These are your existing databases, CRMs, ERPs, and OMSs. They should not be modified to accommodate the chatbot. The middleware bridge must adapt to their existing APIs, not the other way around.
This decoupled structure means you can swap out the chatbot platform without having to rewrite all your business logic. Your internal systems remain untouched and secure behind the middleware. It’s the only sane way to build this.
Building the Middleware Bridge: The Engine Room
The middleware is where the real work happens. This is typically a lightweight web service built with something like Node.js/Express or Python/Flask. Its primary function is to act as a secure proxy and data transformer. When the NLP layer sends a request like {"intent": "getOrderStatus", "orderId": "12345"}, the middleware takes over.
First, it must logic-check the request. Does it contain the required entities? Is the orderId a valid format? This initial validation prevents garbage requests from ever hitting your internal systems. Any failure here should return a specific error message to the user, like “I need a valid order number to look that up.” This is far more useful than a generic “I don’t understand.”
Handling Authentication and Authorization
Before querying any system, the bridge must know who is asking. For public-facing bots, this can be tricky. You can’t just trust a user-provided email address. A common pattern is to implement a temporary, secure tokenization flow. The bot might ask for an email address, and the middleware then triggers a service to email a single-use link to that user. When the user clicks the link, a short-lived JSON Web Token (JWT) is set in their session, authenticating them for the duration of the chat.
This flow is clunky, but it is necessary. Bypassing authentication to get account-specific data is not a shortcut. It is a security incident waiting to happen. The middleware must be the gatekeeper that forces this check on every sensitive request.
Calling the Backend: The Data Retrieval
Once validated and authenticated, the middleware’s job is to call the appropriate internal API endpoint. This means your internal systems need to have APIs. If they don’t, building them is step zero, and that project is a different kind of monster. The middleware must be resilient to API failures. A backend service timing out should not crash the entire chatbot.
Implementing proper error handling and retry logic here is critical. The bridge must distinguish between a 404 Not Found (the order doesn’t exist) and a 503 Service Unavailable (the OMS is down). Each scenario requires a different, carefully worded response to be sent back to the user. This is where you see the difference between a toy and a production-grade tool.
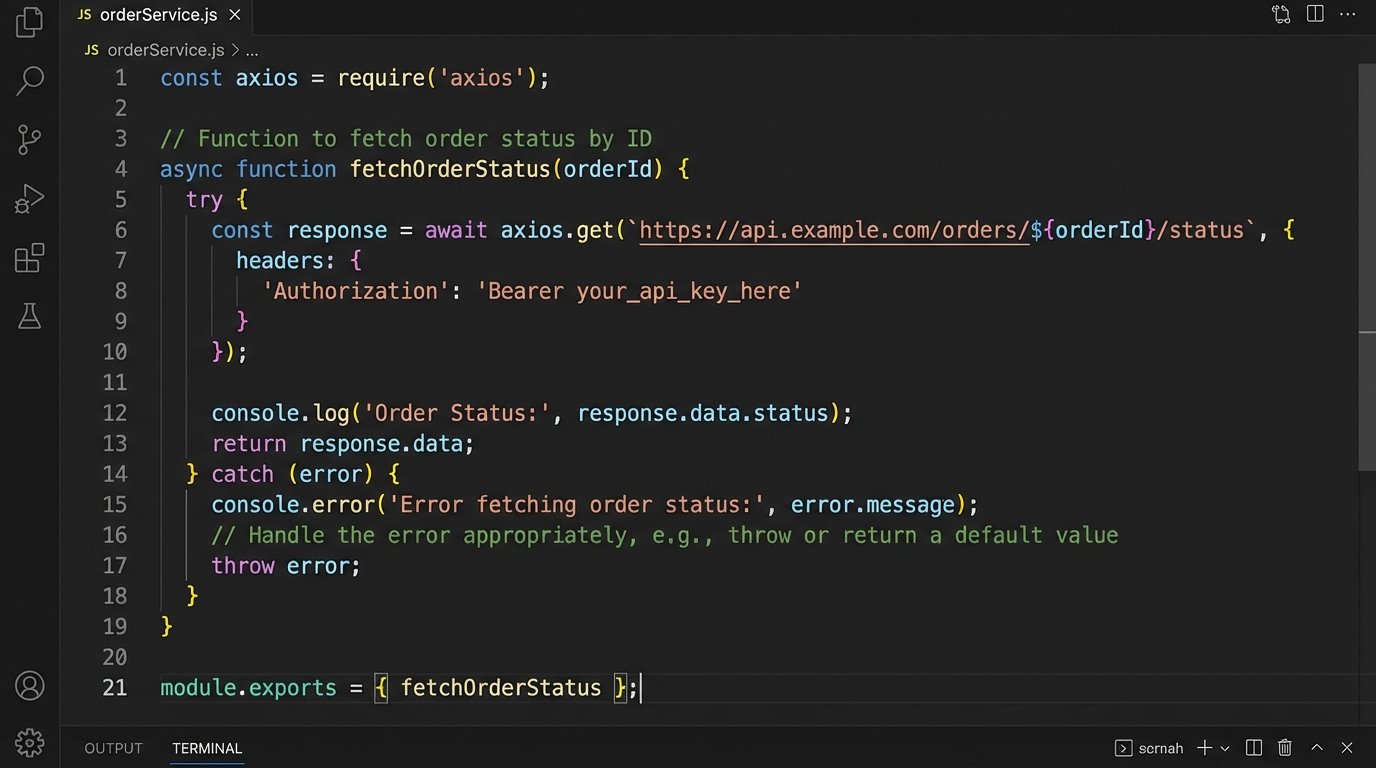
Here’s a crude example of what a retrieval function inside a Node.js middleware service might look like using axios. It’s simplified, but it shows the core sequence: call, process, handle errors.
const axios = require('axios');
const OMS_API_ENDPOINT = process.env.OMS_API_ENDPOINT;
const API_KEY = process.env.OMS_API_KEY;
async function fetchOrderStatus(orderId) {
if (!/^[0-9]{5,10}$/.test(orderId)) {
// Basic format validation
return { status: 'error', message: 'Invalid order number format.' };
}
try {
const response = await axios.get(`${OMS_API_ENDPOINT}/orders/${orderId}`, {
headers: { 'X-API-Key': API_KEY }
});
if (response.status === 200) {
// Strip unnecessary data before returning
const { status, trackingNumber, estimatedDelivery } = response.data;
return { status: 'success', data: { status, trackingNumber, estimatedDelivery } };
}
} catch (error) {
if (error.response && error.response.status === 404) {
return { status: 'not_found', message: `I couldn't find an order with the number ${orderId}.` };
} else {
// Log the full error for debugging
console.error('OMS API failure:', error.message);
return { status: 'system_error', message: 'Sorry, I'm having trouble connecting to our order system right now.' };
}
}
}
Notice the function doesn’t just pass back the raw API response. It strips the payload down to only the fields the user needs. Shoving a firehose of raw JSON through the narrow pipe of a chat interface is a classic mistake. It’s slow and creates more work for the final response generation step.
Response Generation: From JSON to Human
The final step is translating the structured data from the middleware back into a natural language response. This logic can live either in the middleware itself or in the chatbot platform, depending on the platform’s capabilities. The middleware returns a payload like {"status": "success", "data": {"status": "Shipped", "trackingNumber": "1Z9999W99999999999", "estimatedDelivery": "2023-10-28"}}.
A response generator then maps this to a human-readable string: “Okay, I’ve found order {orderId}. It has shipped. Your tracking number is {trackingNumber}, and it’s expected to arrive by {estimatedDelivery}.”
Managing Conversation State
More complex interactions require state management. What if the user just says “Where’s my stuff?” without an order number? The bot must be able to ask a clarifying question (“What’s your order number?”) and remember the original intent (“getOrderStatus”). When the user provides the number in their next turn, the bot must resume the original flow, not start a new one.
This is managed by passing a conversation context object back and forth between the chatbot platform and the middleware. When the middleware needs more information, it sends a response back to the bot that includes a prompt for the user and a context flag, like {"prompt": "What is your order number?", "context": "awaiting_order_id_for_status_check"}. The bot platform displays the prompt and holds onto that context. The user’s next message is then processed with that context in mind.

The Real Cost: Maintenance and Monitoring
Standing up this architecture is only half the battle. Now you own a distributed system with multiple points of failure. The internal OMS API might change without warning, breaking your middleware contract. The chatbot platform might deprecate an API you rely on. The security tokens might have an improper expiration configuration.
Rigorous logging and monitoring are not optional. You need dashboards that track intent recognition failures, API error rates from the middleware, and latency for each step of the process. Without this, you are flying blind. When a user says the bot “isn’t working,” you need a trail of logs to follow to see exactly where the chain broke. This operational overhead is the hidden price of a truly helpful chatbot, and it is a wallet-drainer if you are not prepared for it.