
Best Practices for Setting Up a Real Estate Chatbot
Most real estate chatbots are digital receptionists running on scripts that a summer intern could write. They fail because they are built on the assumption that user queries are clean and the underlying property data is structured. Both assumptions are wrong. The Multiple Listing Service is not a single, clean database. It is a federated mess of inconsistent schemas, and user input is a chaotic stream of typos, slang, and ambiguity. Getting this right means building a defensive system, not an optimistic one.
Isolate Your Data Layer Immediately
Connecting your chatbot’s logic directly to a live MLS feed is architectural malpractice. These APIs are notoriously sluggish, have draconian rate limits, and often return data that requires heavy sanitization. The slightest latency spike in the data source will render your bot unresponsive, leading to user abandonment. You will spend your nights debugging timeouts instead of improving your conversational logic.
The only viable strategy is to build an abstraction layer. This is a separate service that polls the MLS, ingests the raw data, and then forces it into a standardized, predictable schema that you control. This service is responsible for stripping out bad HTML from listing descriptions, normalizing location data, and caching property images. Your chatbot queries this clean, fast, internal API, not the source. This completely decouples your bot’s performance from the reliability of a dozen different third-party providers.
Think of it less as a data pipe and more as a refinery. Crude data goes in, and standardized, high-performance fuel comes out. Without the refinery, you’re just pumping sludge into your engine.
Stop Obsessing Over Generic NLP
Dropping a generic natural language processing library into your project and expecting it to understand real estate nuance is a recipe for failure. A standard model knows what a “kitchen” is, but it has no concept of a “chef’s kitchen” with “Sub-Zero appliances” as a high-value feature. Users don’t say, “I am searching for a property with three bedrooms.” They say, “need a 3br” or “3 bed 2 ba house.”
Focus maniacally on entity extraction before you even think about intent. Your primary goal is to strip specific, valuable tokens from the user’s input. These are your core entities:
- Location: City, ZIP code, neighborhood, school district.
- Property Specs: Bedrooms, bathrooms, square footage.
- Price: Min price, max price.
- Features: Pool, garage, fenced yard, fireplace.
Use a tool like Rasa or even Dialogflow, but dedicate 80% of your initial effort to defining these entities and providing exhaustive training data, including all the slang and abbreviations real people use. A bot that can reliably extract “Austin,” “3 bed,” and “pool” from a messy sentence is more valuable than one that can wax philosophical about the user’s “intent” but returns zero relevant listings.
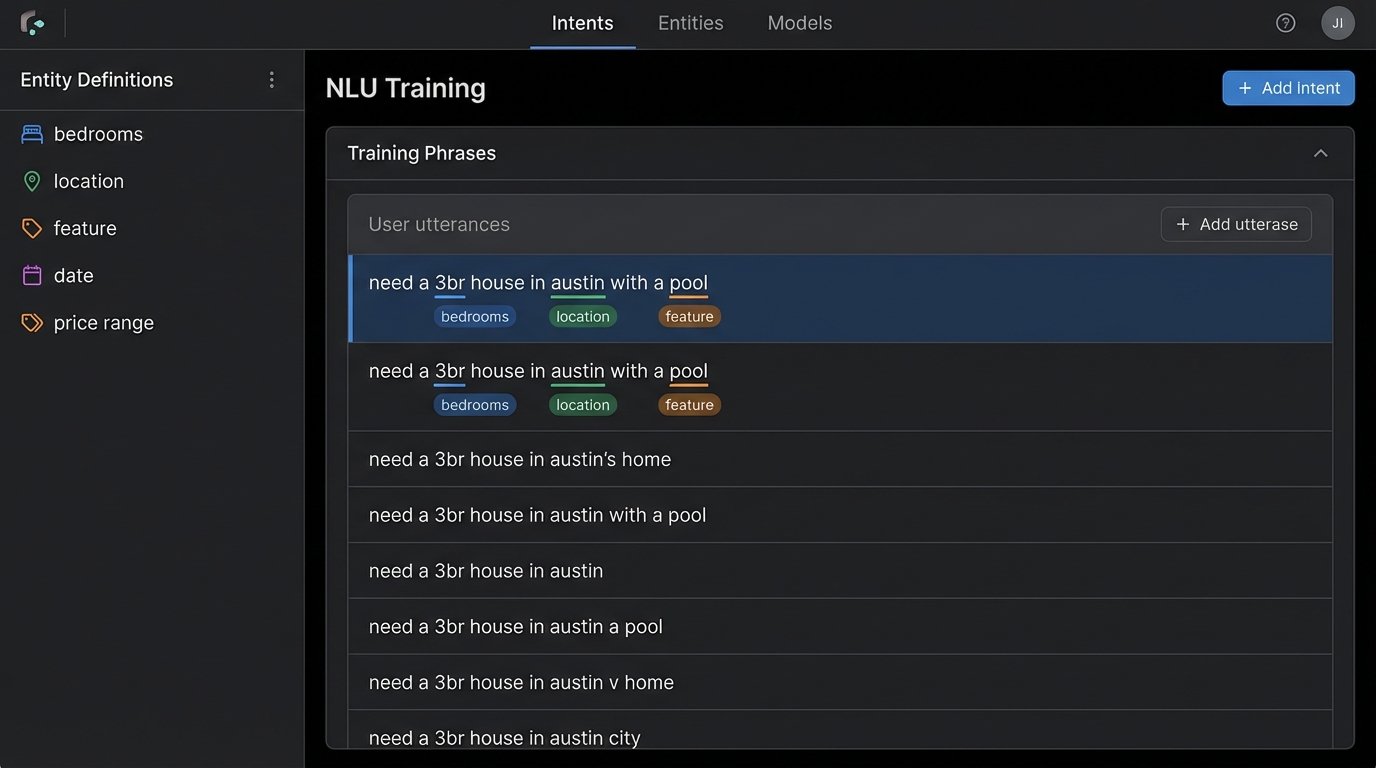
Get the entities right, and the intent becomes trivially simple: `find_property`. Everything else is a distraction.
State Management Determines Conversation Quality
A stateless chatbot is functionally useless for any query more complex than a single turn. Real estate searches are inherently conversational and multi-turn. A user clarifies, refines, and adjusts their criteria. Without state, the bot forces the user to repeat their entire request with every single modification.
User: “Show me houses in 78704.”
Bot: [Shows results]
User: “Ok, what about ones with a pool?”
Stateless Bot: “I can help with that. What area are you interested in?”
This is an instant conversation killer. You must maintain the conversational context. A simple key-value store like Redis is perfect for this. On the first query, you generate a session ID and store a JSON object containing the extracted entities. With each subsequent message, you retrieve that session object, update it with new entities, and then execute the new search.
A minimal state object might look like this:
{
"session_id": "a1b2c3d4-e5f6-7890-g1h2-i3j4k5l6m7n8",
"created_at": "2023-10-27T10:00:00Z",
"last_updated": "2023-10-27T10:02:14Z",
"search_criteria": {
"locations": ["78704"],
"bedrooms": { "min": 3 },
"bathrooms": null,
"features": ["pool"],
"price": { "max": 950000 }
},
"last_results_count": 4,
"conversation_turn": 2
}
This state object is your conversation’s short-term memory. It allows the bot to handle refinements like “only under $950k” by simply updating one key in the JSON instead of starting from scratch. It’s not fancy, but it works.
Engineer the Human Hand-Off Protocol
Your bot will eventually fail to understand a user. This is not a possibility. It is a certainty. The difference between a professional system and an amateur one is in how gracefully it handles this failure. The goal is not to prevent failure but to manage it. You need a clear, programmatic trigger for escalating the conversation to a human agent.
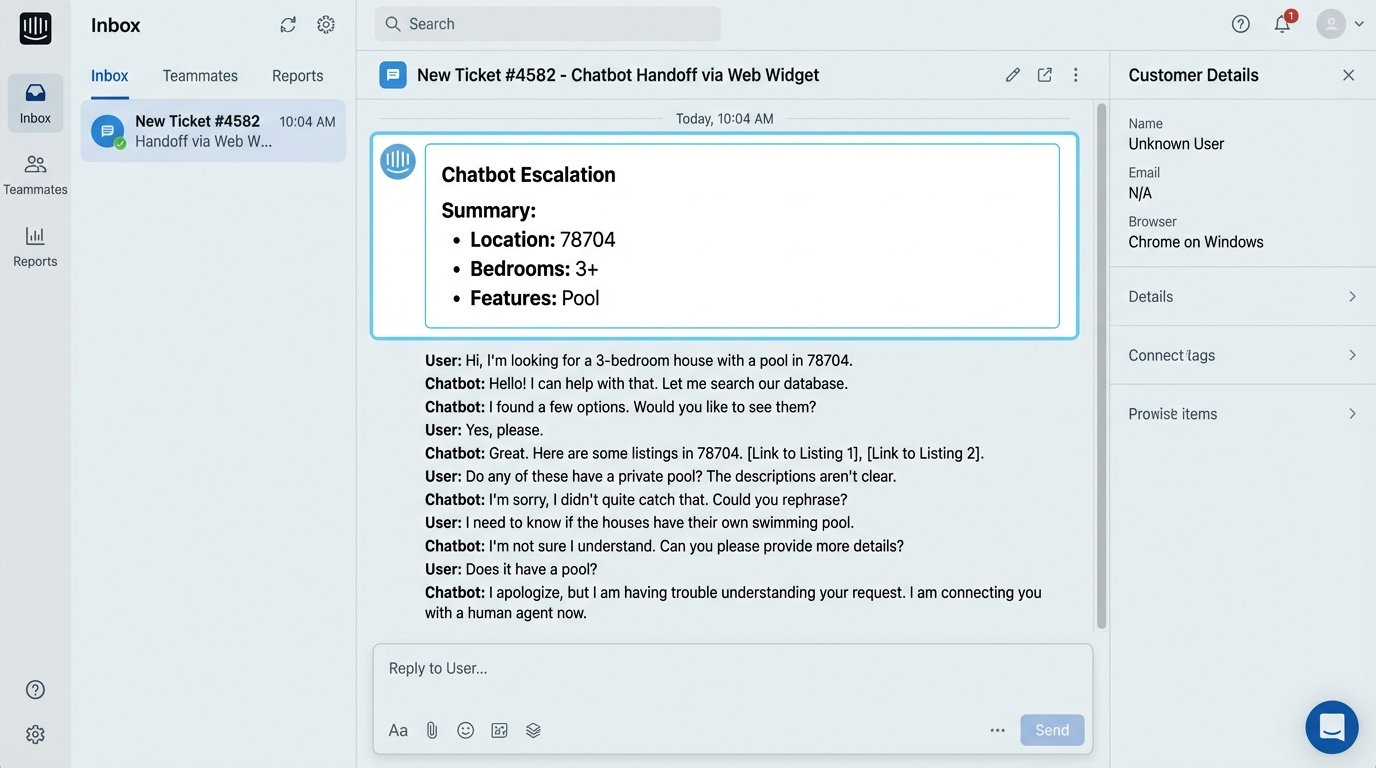
Do not rely on the user typing “help” or “agent.” Create automated triggers. A good starting point is the “three-strikes” rule: if the bot fails to parse the user’s intent three consecutive times, it triggers the hand-off. The key is to make this hand-off intelligent. Simply alerting an agent that “a user wants to chat” is lazy and ineffective.
The hand-off payload must include the entire conversation context. Inject the session ID, the full chat transcript, and the final known state object (the user’s search criteria) directly into the agent’s CRM or live chat software. The agent should see a summary: “Incoming chat from User #123. They are looking for a 3+ bedroom house with a pool in ZIP 78704. Here is the conversation.” This arms the agent to take over seamlessly instead of forcing the frustrated user to repeat everything for a third time.
Your Logs Are for Debugging, Not Vanity Metrics
Stop tracking metrics like “total conversations” or “messages sent.” These are useless for engineering and exist only to populate marketing dashboards. Your logs need to be a diagnostic tool for identifying where the bot is breaking down. Your focus should be on logging failures, not successes.
Your primary log events should include:
- Unparsed Intents: Every single time a user says something your NLP model cannot classify, log the raw input. This text is your goldmine. A weekly review of these logs tells you exactly what training phrases you need to add to your model.
- API Errors: Log every failed call to your internal data API or any third-party enrichment services. Are you getting rate-limited? Is a specific endpoint timing out? This is your early warning system for infrastructure problems.
- Zero-Result Queries: Log the search criteria for every query that returns zero properties. A high number of these might indicate a flaw in your search logic, stale data in your cache, or users searching for criteria your inventory can’t satisfy. This is a business intelligence problem disguised as a technical one.
These logs tell you what to fix. Vanity metrics just tell you the system is running. There’s a big difference.
Enrich Your Data to Add Actual Value
Access to the MLS is a commodity. A bot that just parrots listing data is not a significant advantage. The real value comes from enriching that core data with external information sources. This transforms your bot from a simple search tool into a decision-making assistant. Don’t just show a property. Show its context.
You should be pulling from other APIs to layer additional data on top of your listings:
- Google Maps API: Calculate commute times to a user-specified workplace. “Show me homes with a commute under 30 minutes to downtown.”
- School Rating APIs: Pull in scores for nearby elementary, middle, and high schools.
- Walk Score API: Provide a score for a property’s proximity to restaurants, parks, and shops.
- Local Crime Data: Integrate with public data sources to provide neighborhood safety statistics.
This enrichment process is where your data abstraction layer pays for itself again. The enrichment logic lives there, not in the bot. When a user queries for a property, your internal API returns a single, rich JSON object that already contains the core MLS data combined with school ratings, a walk score, and any other data you’ve integrated.
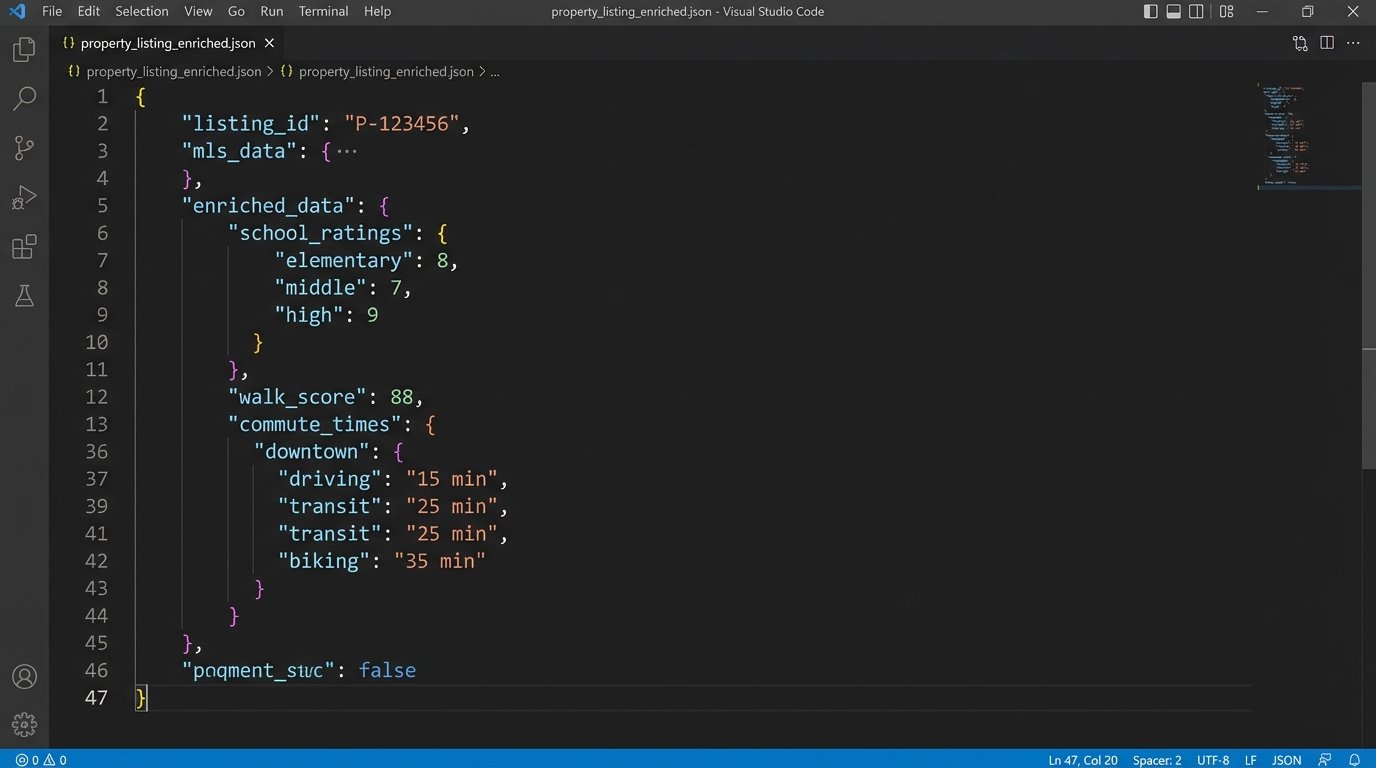
Be warned, this is a wallet-drainer. These APIs are not free. Caching is critical. You must design a caching strategy that stores these enriched property profiles to avoid making duplicate API calls for the same listing. A property’s school district doesn’t change every five minutes. Cache it aggressively.