
Your Dashboard is Red Again. It’s Not The Code.
The pipeline failed. The report is empty. Management wants answers you don’t have. The root cause is rarely a complex algorithm or a logic bug. It’s almost always a brittle connection to a data source that someone set up six months ago with blind optimism. We build these complex automation structures on top of APIs and databases as if they are solid bedrock, but they’re more like a patchwork of rickety rope bridges over a canyon.
Let’s gut the common failure points. These are the mistakes that get you paged at 3 AM. Avoid them and you might actually get some sleep.
Mistake 1: Treating API Rate Limits as Suggestions
Every junior developer hits this wall. They write a loop to pull 10,000 records, fire it off, and get back a flood of 429 Too Many Requests errors. Rate limits aren’t a friendly suggestion from the API provider. They are a hard gate enforced to protect their infrastructure from your enthusiasm. Ignoring them means your IP gets throttled, or worse, temporarily banned.
Thinking you can just add a time.sleep(1) in your loop is naive. A fixed delay doesn’t account for network latency or periods of high server load on the provider’s end. The correct approach is to implement an exponential backoff strategy with jitter. This logic-checks the response headers for retry information and progressively increases the wait time after each failure, preventing a thundering herd problem where all your failed requests retry at the same instant.
Implementing Exponential Backoff
You don’t need a heavy library for this. The logic is simple enough to write yourself. The goal is to retry a failed request, but to wait longer each time you fail. Adding a small, random “jitter” value prevents multiple instances of your script from retrying in perfect sync and hammering the server all at once again.
Here’s a raw Python example using the popular requests library. Notice it checks for specific status codes that are worth retrying, not just any failure.
import requests
import time
import random
def get_with_backoff(url, headers, max_retries=5):
"""
Makes a GET request with exponential backoff.
"""
base_wait = 1 # seconds
for attempt in range(max_retries):
try:
response = requests.get(url, headers=headers)
# Retry on server-side errors and rate limiting
if response.status_code in [429, 500, 502, 503, 504]:
wait_time = base_wait * (2 ** attempt) + random.uniform(0, 1)
print(f"Request failed with status {response.status_code}. Retrying in {wait_time:.2f} seconds...")
time.sleep(wait_time)
continue
response.raise_for_status() # Raise HTTPError for other bad responses (4xx)
return response
except requests.exceptions.RequestException as e:
if attempt == max_retries - 1:
print(f"Max retries reached. Request failed: {e}")
raise
wait_time = base_wait * (2 ** attempt) + random.uniform(0, 1)
print(f"Request failed with exception {e}. Retrying in {wait_time:.2f} seconds...")
time.sleep(wait_time)
raise Exception("Max retries exceeded")
# Usage
# api_url = "https://api.example.com/data"
# api_headers = {"Authorization": "Bearer YOUR_TOKEN"}
# data = get_with_backoff(api_url, api_headers)
Stop brute-forcing connections. Build them to be polite and persistent.
Mistake 2: Blind Faith in API Documentation
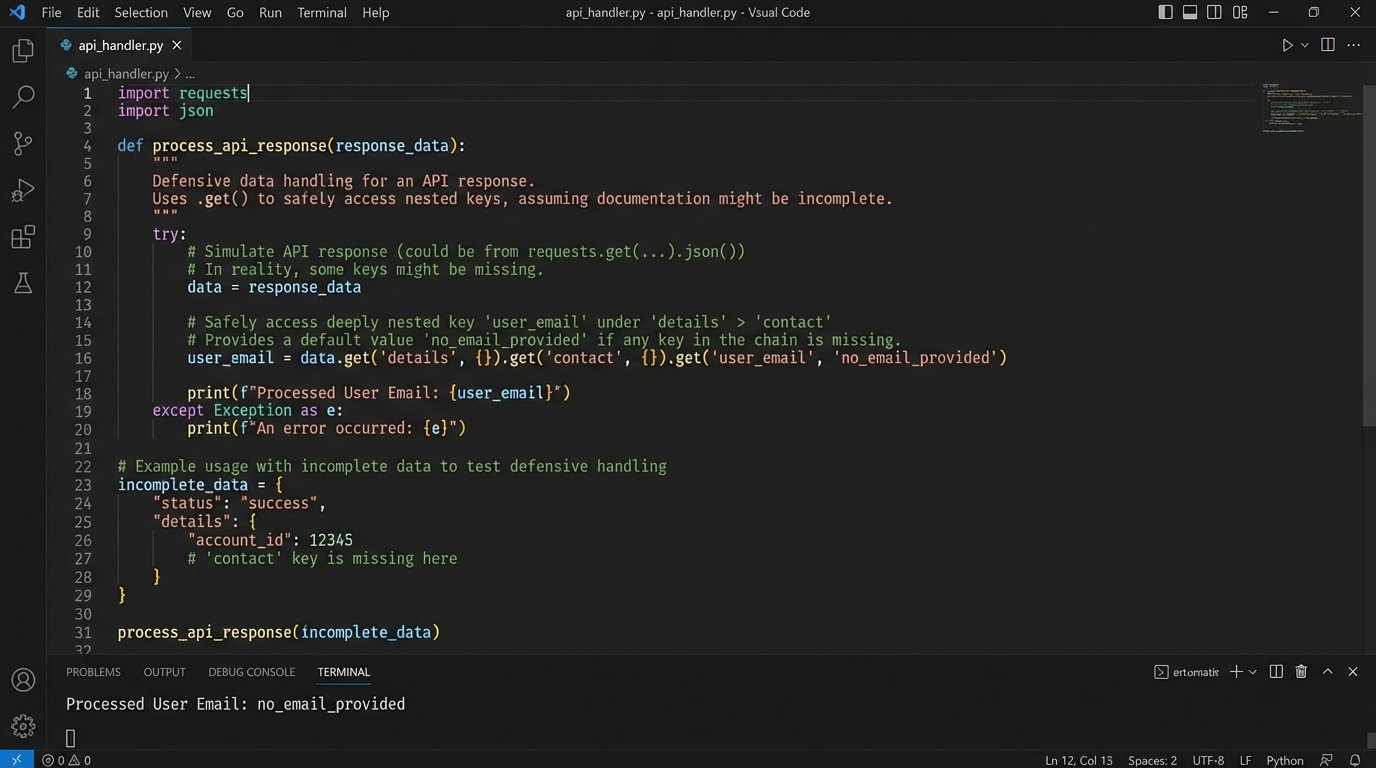
API documentation is a marketing asset written by one team and implemented by another, often five years ago. It lies. Not always maliciously, but through neglect. Endpoints get deprecated, fields change data types, and required parameters become optional without a single update to the docs. Your code’s single source of truth is not the documentation. It is the actual JSON response you get from the server.
Never write code that assumes a key will exist in a response. Every access to a nested dictionary key should be guarded. Use methods like Python’s .get() with a default value, or write a dedicated data validation layer that strips the response down and maps it to a known, stable internal model. If the API suddenly starts sending a string where you expect an integer for `user_id`, your code should flag it as a data quality issue, not crash with a TypeError.
This approach forces you to be deliberate about the data you consume. It also insulates the rest of your system from upstream chaos when the API provider deploys a breaking change on a Friday afternoon.
You build a shield between their unpredictable output and your stable system.
Mistake 3: The Myth of the Static Schema
Data schemas are not fixed. They drift over time. The source system gets a feature update, and suddenly a new column appears in the database table you’re polling. A marketing team adds a new UTM parameter, and now a field in your analytics payload has a much longer string length than you provisioned for in your data warehouse. This “schema drift” is a primary cause of silent data corruption and pipeline failures.
Assuming a schema is static is a bet you will eventually lose. Your ingestion process must have schema validation built-in. For JSON payloads, tools like Pydantic in Python or JSON Schema are non-negotiable. They allow you to define a strict contract for incoming data. If a payload arrives that doesn’t match the contract, you reject it and log an alert. This stops bad data at the door instead of letting it contaminate your entire dataset.
Defining a Data Contract
A data contract is just a formal definition of expected data structure and types. Using a tool like Pydantic, you define it as a class. It self-documents the expected structure and automatically handles the validation and type coercion. If validation fails, it raises a clear exception that tells you exactly which field was wrong and why.
- Enforce Data Types: An `order_id` must be an integer, not `“N/A”`.
- Check for Required Fields: A `transaction_timestamp` cannot be missing.
- Validate Formats: An `email` field must look like an email address.
This isn’t about being rigid. It’s about being intentional. When the schema does need to change, you update your contract first, then deploy the code. It turns an unexpected failure into a planned migration.
Mistake 4: Defaulting to a Full Refresh
The laziest way to sync data is to drop the destination table and pull everything from the source again. This “full refresh” approach is a wallet-drainer and a performance killer. It consumes massive amounts of API credits, puts unnecessary load on the source system, and scales horribly. Pulling 50 million rows from an analytics API every hour because you couldn’t be bothered to track state is just bad engineering.
The professional approach is an incremental load. You find a reliable “watermark” in the source data, typically a `last_modified_timestamp` or an auto-incrementing ID. In each run, you query the source for records where the watermark is greater than the maximum value from your last successful run. This reduces your query from “give me everything” to “give me what’s new since 10:05 AM.”
This process is far more efficient but introduces new problems, mainly handling deleted records. If a record is deleted in the source, an incremental pull won’t know about it. This requires a separate process, a “soft delete” flag in the source, or a periodic reconciliation job that compares record sets. There is no perfect solution here, only a choice of complexities.
Choosing an incremental strategy is choosing to treat the source system with respect.
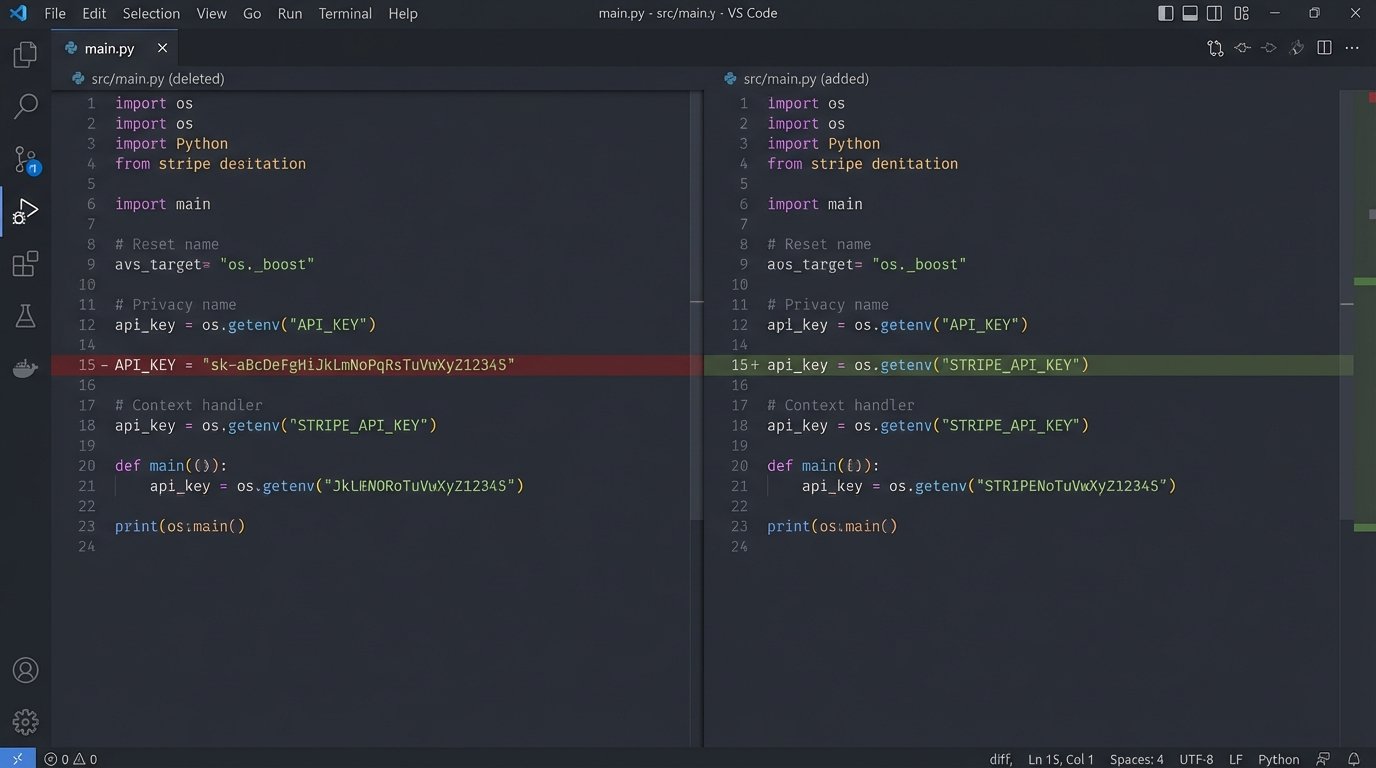
Mistake 5: Hardcoding Secrets and Configuration
Checking an API key into a Git repository is the modern equivalent of writing your password on a sticky note and putting it on your monitor. It’s a matter of when, not if, it will be compromised. Hardcoding credentials, endpoints, or any other configuration directly into your script creates a brittle and insecure system. When an API key needs to be rotated, you have to find every instance, change it, and redeploy. It’s a recipe for failure.
All configuration should be externalized. At a minimum, use environment variables. For anything more serious, a dedicated secrets management tool like HashiCorp Vault, AWS Secrets Manager, or Google Secret Manager is the correct tool for the job. Your application gets credentials at runtime by authenticating with the secrets manager, not by reading them from a plain text file.
Hardcoding secrets is like shoving a firehose through a needle. You are forcing a high-risk, dynamic value into a static, low-security context. It’s a structural mismatch that is guaranteed to cause a rupture.
Separate your code (the logic) from your configuration (the environment). It’s the most fundamental rule of building maintainable software.
Mistake 6: Forgetting Idempotency
Imagine your script pulls 1,000 orders, successfully inserts 500 into your database, and then crashes due to a network blip. What happens when you re-run it? If you’re not careful, it will pull the same 1,000 orders and insert the first 500 again, creating duplicates. This lack of idempotency turns a simple retry into a data corruption event.
An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application. In data integration, this means your “write” logic must be ableto handle being fed the same record more than once. The standard way to achieve this is an “upsert” operation: insert a new record if it doesn’t exist, or update the existing record if it does. This requires a unique business key (like an `order_id` or a compound key of `user_id` and `product_id`) to identify records.
If the target system doesn’t support native upsert commands, you have to build the logic yourself:
- Generate a unique hash or key for the incoming record.
- Check if a record with that key already exists in the destination.
- If it exists, run an `UPDATE` statement.
- If it does not exist, run an `INSERT` statement.
Building for idempotency is building for reality. Networks fail, servers restart, and jobs get re-run.
Mistake 7: No Monitoring on the Connection Itself
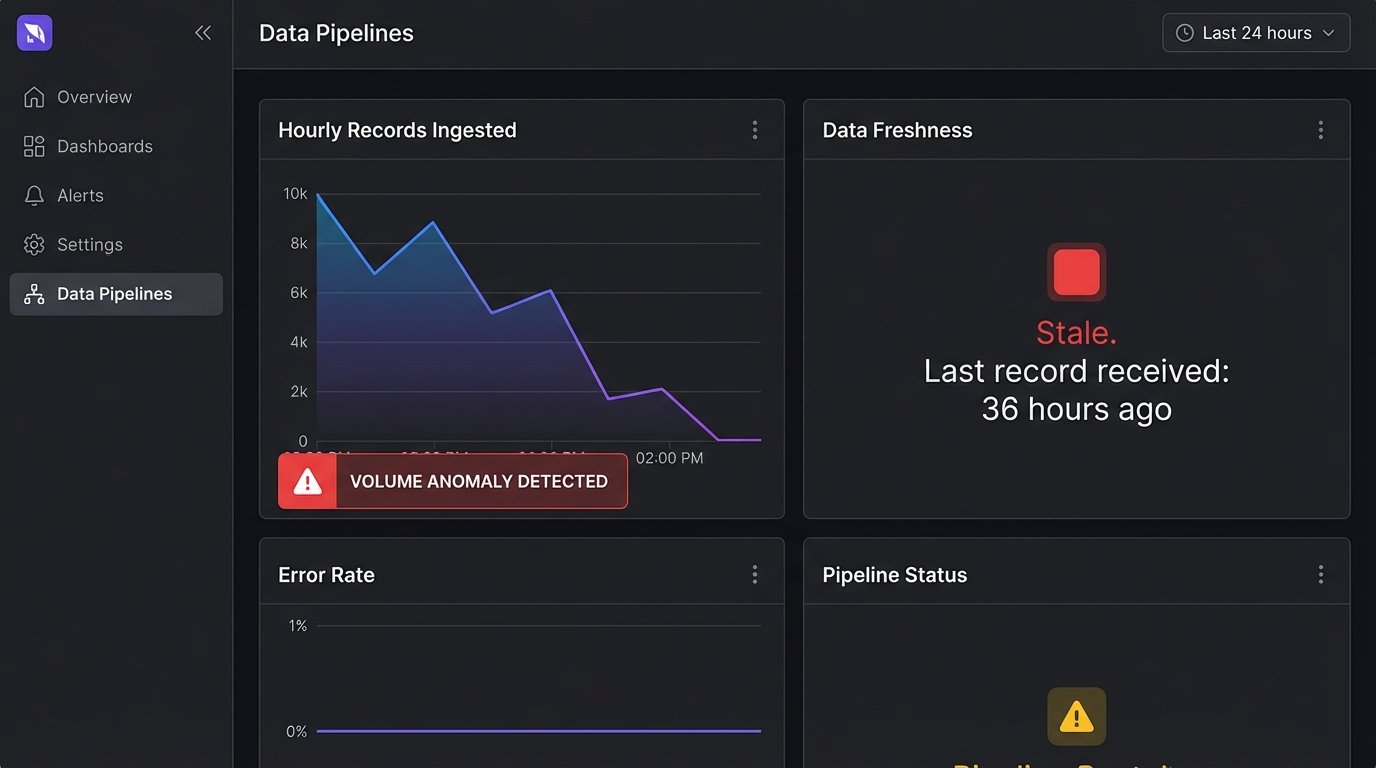
Most monitoring focuses on the application: CPU, memory, error rates. But few people put monitors on the data connections themselves. A pipeline can be “running successfully” for days, processing zero records, because the source API key expired or a firewall rule changed. This silent failure is insidious. No data is often worse than bad data because it doesn’t trigger alarms.
Your connections need health checks. This goes beyond simple error logging.
- Data Freshness Checks: Set an alert if the latest `created_at` timestamp in your destination table is more than X hours old. This catches stalled pipelines.
- Volume Anomaly Detection: Set an alert if the number of records processed in a run drops by more than 90% or increases by 500% compared to the daily average. This catches source-side issues or major schema changes.
- Authentication Probes: Run a small, cheap “canary” request against the API every few minutes just to validate that your credentials are still valid.
Don’t wait for a business user to tell you the Q3 revenue report is empty. Your system should know it failed long before that.
Your automation is only as strong as its weakest connection. Build for the failures you know are coming, not for a perfect-world scenario that only exists in the documentation.