
Most real estate teams think “automation” is a drip campaign that sends a canned birthday email. That isn’t automation. It’s a scheduled task, a glorified cron job that provides the illusion of activity. True automation isn’t about scheduling emails. It’s about building an event-driven architecture that eliminates the human middleware currently holding your brokerage together with manual data entry and duct tape.
The core failure is systemic. Your team operates on a dozen disconnected platforms. The MLS has the property data. Your CRM has the client data. Your marketing platform has lead engagement data. Your transaction coordinator works out of a completely separate system. Getting these systems to speak to each other is the actual job of half your administrative staff.
Scaling by hiring more people to copy and paste information between these silos is a death sentence. You’re not scaling the business. You’re scaling the payroll and the potential for human error. Every new hire is another potential point of failure in a brittle, manual process.
The Architectural Mess We Call a “Tech Stack”
The standard real estate tech stack is a collection of independent, walled-off systems bought on the promise of solving one specific problem. You have a lead-gen tool that captures names, a CRM that stores them, and an email tool that messages them. The only thing bridging these systems is a person, likely overworked, manually exporting a CSV from one and importing it into another. This is madness.
This fragmented approach creates data latency and integrity issues. A lead comes in from Zillow. Someone on your team has to manually create that contact in the CRM. Then they have to manually link a property search to their profile. If the client calls and wants to see a new listing, that information has to be manually updated. The delay between the event and the data update creates a window for failure.
Your business logic is trapped in the heads of your agents and admins. It’s not codified. What happens when a listing’s status changes from “Active” to “Pending” in the MLS? A series of manual tasks fires off. Someone has to update the CRM, notify the marketing team to pull the ads, tell the transaction coordinator to start the next workflow, and update the client. This entire chain is dependent on a person remembering to do it.
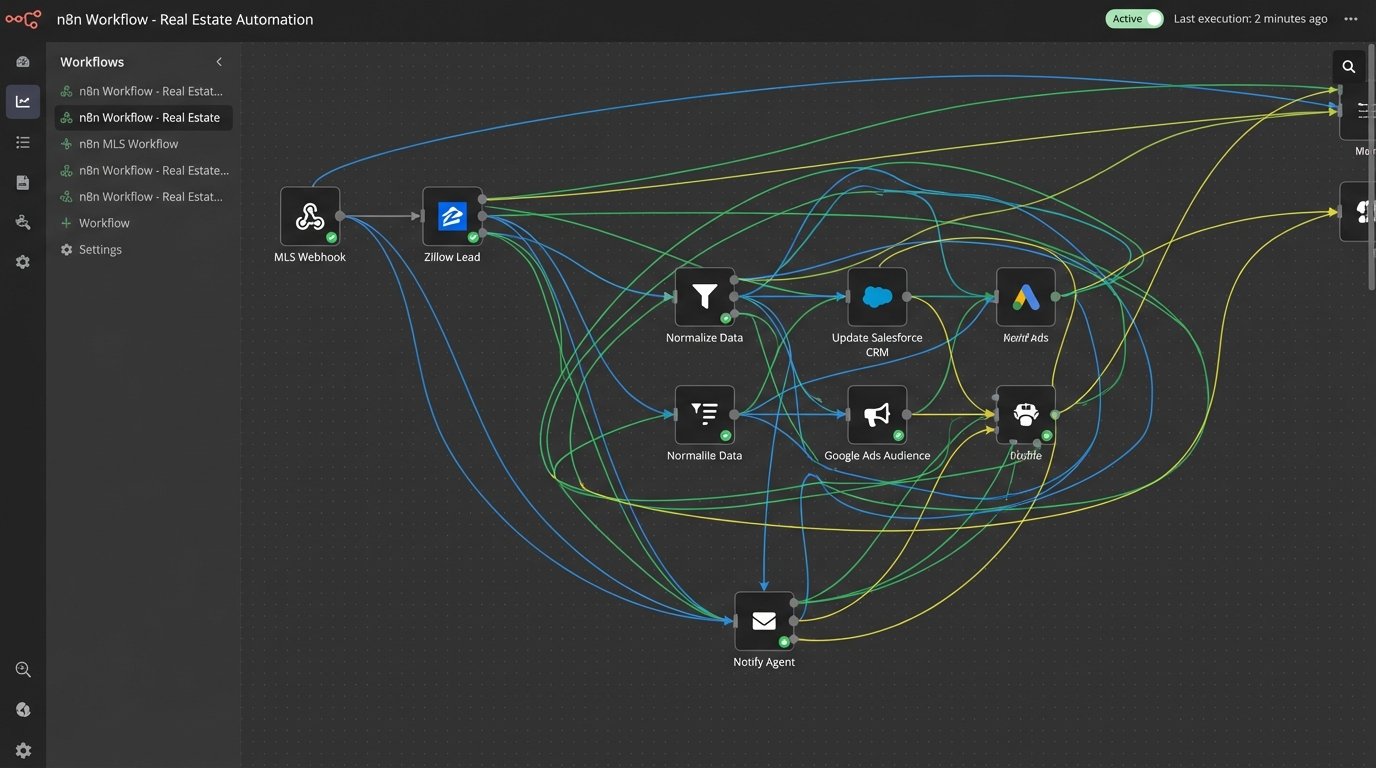
This is the architectural equivalent of a spaghetti junction. Data flows are chaotic, undocumented, and impossible to debug when something breaks. Scaling this model means adding more cars to the traffic jam. It doesn’t work.
Moving from Scheduled Tasks to Event-Driven Logic
The alternative is to re-architect your operations around a central hub or an event bus. Instead of people watching for changes, you build systems that listen for them. An event is any meaningful action: a new lead is captured, a property status changes, a contract is signed, a client opens an email. Each event triggers a predefined, automated workflow.
Consider a price change on an active listing. In a manual setup, an agent gets an email and then has to remember to update marketing materials, social media posts, and notify a list of interested buyers. In an event-driven model, the moment the MLS API reports a price change, a webhook fires. This single event can trigger multiple concurrent actions without any human intervention.
- A function is triggered to update the property’s price on your company website.
- Another service pulls a list of contacts from the CRM who have saved that property and sends them a targeted notification.
- The marketing system is signaled to update the ad copy on Google and Facebook campaigns to reflect the new price.
- A task is automatically created in your transaction management system for the agent to follow up.
This isn’t a simple Zapier connection. This is about building a nervous system for your business. The “single source of truth” ceases to be a fantasy whispered about at tech conferences and becomes a functional reality. The MLS is the source for property data. The CRM is the source for contact data. Everything else reads from these sources and reacts to changes. You stop having five different versions of a client’s phone number.
The Problem of Inconsistent Data Payloads
Connecting to these systems is the first hurdle. The real work is in data normalization. An address from a web lead form looks nothing like an address from the MLS, which looks nothing like the address format required by your direct mail provider. You have to build transformation layers to clean and standardize data as it moves between systems.
Forcing raw, unvalidated data from one system into another is like trying to shove a firehose through a needle. It’s messy and something will break. Your automation needs to be defensive. It must logic-check incoming data, strip useless characters, standardize formats, and handle exceptions when a payload is incomplete or malformed.
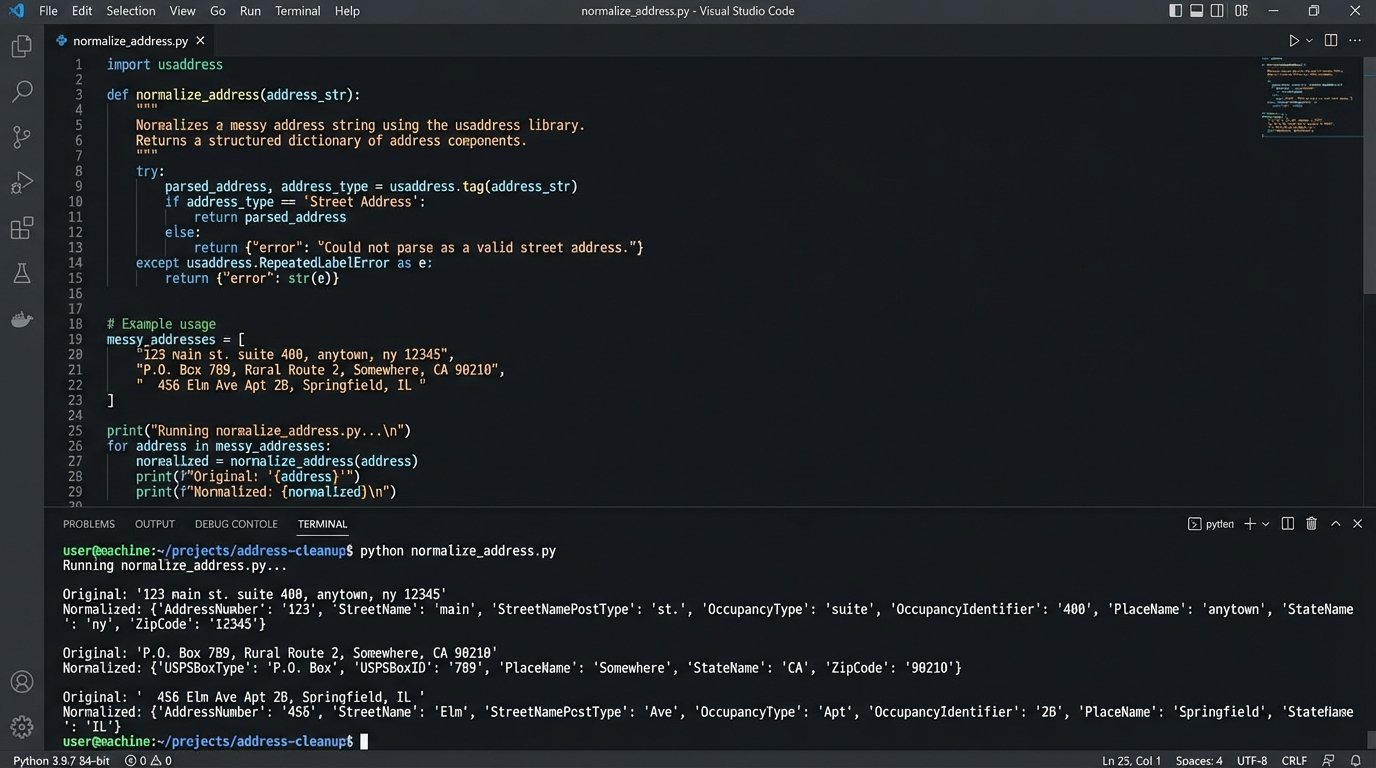
Here is a trivial example in Python for parsing a garbage address string into a structured format. This is the kind of utility function that becomes essential when you’re processing lead data from multiple online sources with zero input validation.
import usaddress
def normalize_address(address_string):
"""
Parses a free-form address string and attempts to return a
standardized dictionary. Returns None if parsing fails.
"""
try:
# The library throws an exception for unparseable strings
parsed_address = usaddress.tag(address_string)
# Reconstruct into a cleaner, predictable format
# This logic would be far more complex in production
address_map = parsed_address[0]
street = f"{address_map.get('AddressNumber', '')} {address_map.get('StreetName', '')} {address_map.get('StreetNamePostType', '')}".strip()
city = address_map.get('PlaceName', '')
state = address_map.get('StateName', '')
zip_code = address_map.get('ZipCode', '')
if not all([street, city, state, zip_code]):
# Basic validation failed, reject it
return None
return {
"street_address": street,
"city": city,
"state": state,
"zip_code": zip_code
}
except usaddress.RepeatedLabelError:
# The parser failed, return nothing
return None
# --- Example Usage ---
messy_address_1 = "123 main st, anytown, ca 90210"
messy_address_2 = "456 Oak Avenue, Springfield" # Missing state/zip
clean_address_1 = normalize_address(messy_address_1)
# Result: {'street_address': '123 main st', 'city': 'anytown', 'state': 'ca', 'zip_code': '90210'}
clean_address_2 = normalize_address(messy_address_2)
# Result: None
This simple function demonstrates the principle. Before any address data gets written to your CRM, it’s forced through a cleaning and validation process. This stops garbage data from polluting your single source of truth. Every single data point needs this level of scrutiny.
Building the Foundation: APIs, Webhooks, and a Central Datastore
The technical foundation for this requires three components. First, access to APIs for all your critical systems. If your CRM provider doesn’t have a well-documented API, you need a new CRM provider. You cannot build automation on top of a closed box. You need programmatic access to create, read, update, and delete records.
Second, you must prioritize webhooks over API polling. Polling is inefficient. It means asking a server “anything new?” every sixty seconds. It’s a resource drain and prone to hitting rate limits. Webhooks are the opposite. The external system tells you when something new happens. This is the core of an event-driven model. The MLS should notify your system via a webhook when a listing status changes. You shouldn’t have to ask it constantly.
Many MLS providers offer RETS or RESO Web API access. Getting this feed is non-negotiable. It’s the firehose of property data that powers the entire operation. Without it, you are flying blind, relying on agents to manually report changes.
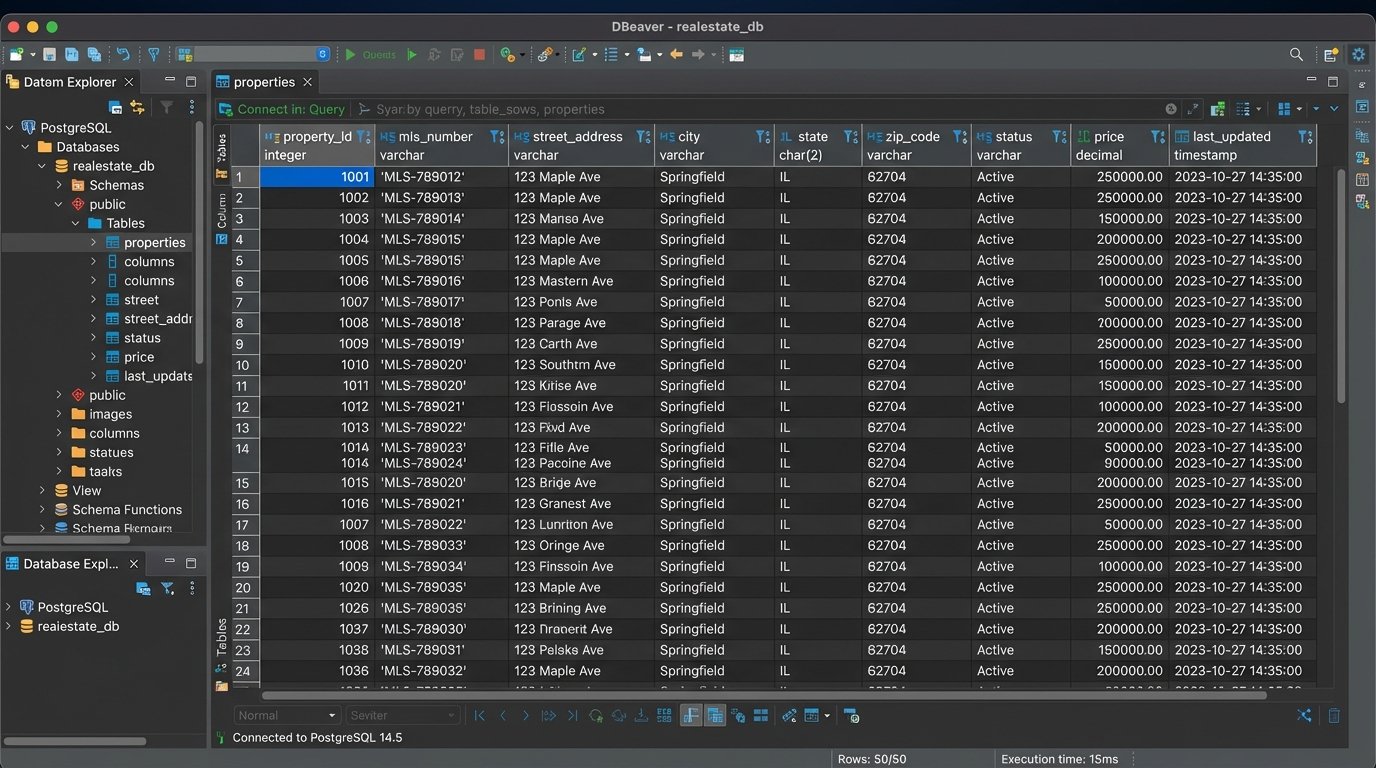
Third, you need a central datastore that you control. This could be a simple PostgreSQL database or a more complex data warehouse. Its job is to hold the clean, normalized version of your core business objects: contacts, properties, and transactions. Your CRM might be the system of record for contacts, but your internal database holds the version that has been validated, enriched, and standardized. This database becomes the hub from which all other systems draw their data.
This Is Not Free or Easy
Building this infrastructure is a serious engineering effort. It is not a weekend project with a no-code tool. You need developers who understand data architecture, API integrations, and error handling. This is a wallet-drainer upfront. You are trading manual labor costs spread out over years for a significant capital investment in technology and talent right now.
The system will also break. An API endpoint you rely on will be deprecated. A third-party service will have an outage. Your data transformation logic will encounter an edge case it wasn’t designed for. This requires ongoing maintenance. You aren’t just building a thing. You are building a system that needs to be monitored, patched, and upgraded.
The payoff is not “efficiency.” The payoff is deterministic scaling. When you want to expand to a new market, you don’t just hire 20 more agents and 5 more admins to handle the paperwork. You connect the new MLS feed to your existing data processing pipeline, provision accounts in the CRM, and the system absorbs the new workload. You scale your capacity without scaling your chaos.
Stop looking for the next all-in-one software. It doesn’t exist. The solution is to own your data pipeline. Build a system that allows you to plug in best-in-class tools for each job, all orchestrated by a central logic core that you control. This is how you escape the cycle of manual work and build a business that can actually grow.