
Scaling a Virtual Brokerage is an Exercise in Containing Chaos
Scaling a virtual brokerage isn’t about adding more agent licenses. It’s about preventing your transaction pipeline from seizing up under the weight of its own success. Most platforms are cobbled together with off-the-shelf SaaS and brittle integrations. This works for fifty agents. It collapses at five hundred.
The core failure isn’t the tools. It’s the architectural assumptions made early on. We’re going to gut the most common failure points before they take your production environment down on the first day of the month, which is always when things break.
Mistake 1: Treating External APIs as Internal Services
Your brokerage runs on external APIs. MLS data feeds, e-signature platforms, CRMs, and compliance software are all points of failure you don’t control. A naive implementation fires direct, synchronous calls to these services for every user action. This is slow, unreliable, and a fantastic way to hit rate limits you didn’t know existed.
A user refreshing their dashboard shouldn’t trigger a dozen fresh calls to the MLS provider. You end up with a sluggish interface and a bill for API overages. You must implement a caching layer. For data that changes infrequently, like property details or agent profiles, a simple Redis cache with a reasonable TTL can absorb 90% of the read load. It’s not complex, but it’s constantly overlooked.
Relying on polling for status updates is another amateur move. Constantly asking DocuSign “is it signed yet?” is inefficient. You need to architect for webhooks. When a document is signed, DocuSign should tell you. This forces an asynchronous, event-driven mindset that is critical for scaling. Your system reacts to events instead of burning cycles checking for them.
Build circuit breakers into your API clients from day one. When an API inevitably starts throwing 500 errors, your service needs to stop hitting it. A simple pattern is to open the circuit after five consecutive failures, wait for a minute, then try a single request to see if the service has recovered. Without this, your own application logs will fill with useless noise and your services will waste resources trying to connect to a dead endpoint.
Mistake 2: The Monolithic Transaction Coordinator
The temptation is to build one giant service that does everything. It handles agent onboarding, manages transaction documents, checks for compliance, calculates commissions, and integrates with accounting. This monolithic architecture is easy to start with. It becomes an operational nightmare to maintain.
A bug in the PDF parsing logic for a new disclosure form can bring down commission calculations for the entire brokerage. Deploying a simple change to a compliance rule requires a full regression test of the entire monolith. This is how your development velocity grinds to a halt. You spend all your time managing the complexity you created.
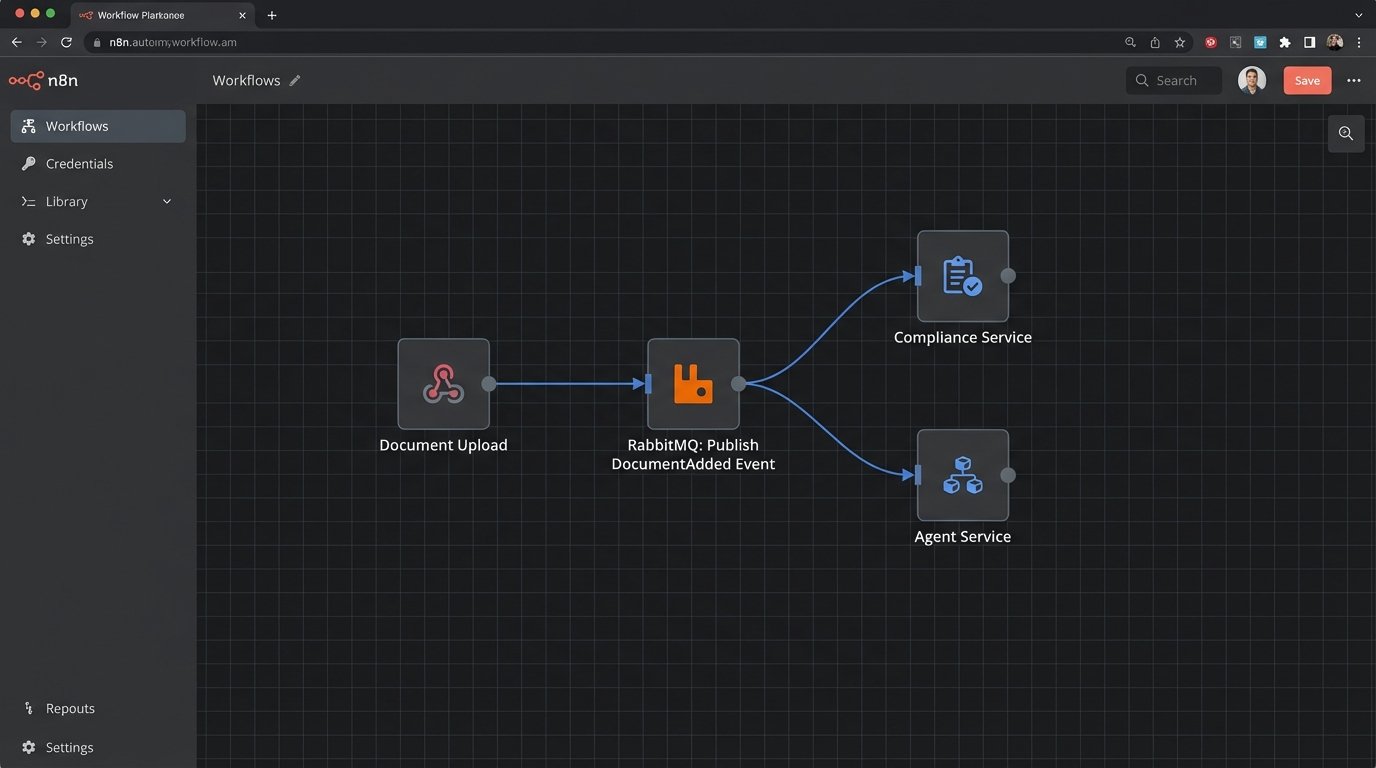
The correct approach is to break this down. You need a Document Service, a Compliance Service, a Commission Service, and an Agent Service. They communicate over a message bus like RabbitMQ or Kafka. When a new document is uploaded to the Document Service, it publishes a `DocumentAdded` event. The Compliance Service listens for that event and runs its checks. This decouples your systems.
This isn’t a free lunch. You trade the simplicity of a single codebase for the complexity of a distributed system. You now have to worry about message delivery guarantees and monitoring multiple services. But this is the only way to scale your team and your platform. Different teams can own different services, deploying independently without fear of breaking the entire Rube Goldberg machine.
Mistake 3: Naive Data Synchronization and the Dual-Write Problem
Your data lives in multiple places. An agent’s contact information is in your CRM, your transaction management system, and maybe your marketing automation tool. The most common mistake is to try and keep them in sync with dual writes. When a user updates an agent’s phone number, the application code first writes to the primary database, then makes an API call to update the CRM.
This works until the CRM API call fails. Now your internal system has the new phone number, but the CRM has the old one. Your data is inconsistent. Hunting down these silent data corruption issues is a special kind of hell. You can’t trust your own data anymore.
The solution is to establish a single source of truth (SSOT) for each piece of data and use an event-driven pattern. The Agent Service is the SSOT for agent data. When an agent’s profile is updated, that service writes the change to its own database and then publishes an `AgentProfileUpdated` event onto the message bus. Downstream systems, like the CRM connector, subscribe to this event and update their own records accordingly.
This approach introduces eventual consistency. The CRM might be a few seconds behind the main application. You have to design for this. It also means you need a robust dead-letter queue and retry mechanism for when a downstream service is down and can’t process an event. Shoving a firehose through a needle is the perfect description for trying to force real-time consistency across distributed systems; you just blow out the needle. You have to buffer the flow.
Mistake 4: Hardcoding Business Logic
Commission plans and compliance checklists are not static. They change based on agent performance, team structures, state laws, and the whims of leadership. Hardcoding this logic directly into your application code is a recipe for disaster. Every time a commission split changes, a developer has to change the code, get it reviewed, and push a new deployment.
This turns your engineering team into a bottleneck for business operations. The Head of Finance should not have to file a Jira ticket to add a new transaction fee. You must abstract this logic out of the core application. A rules engine is the classic solution. You define the rules in a separate system, and the application simply feeds it data and gets a result.
You don’t need a heavy, enterprise-grade rules engine to start. The logic can be stored as structured JSON or YAML in a database. This file can be edited through a simple admin interface by a non-technical user. The application code just fetches the current ruleset, executes it against the transaction data, and gets the calculated commission.
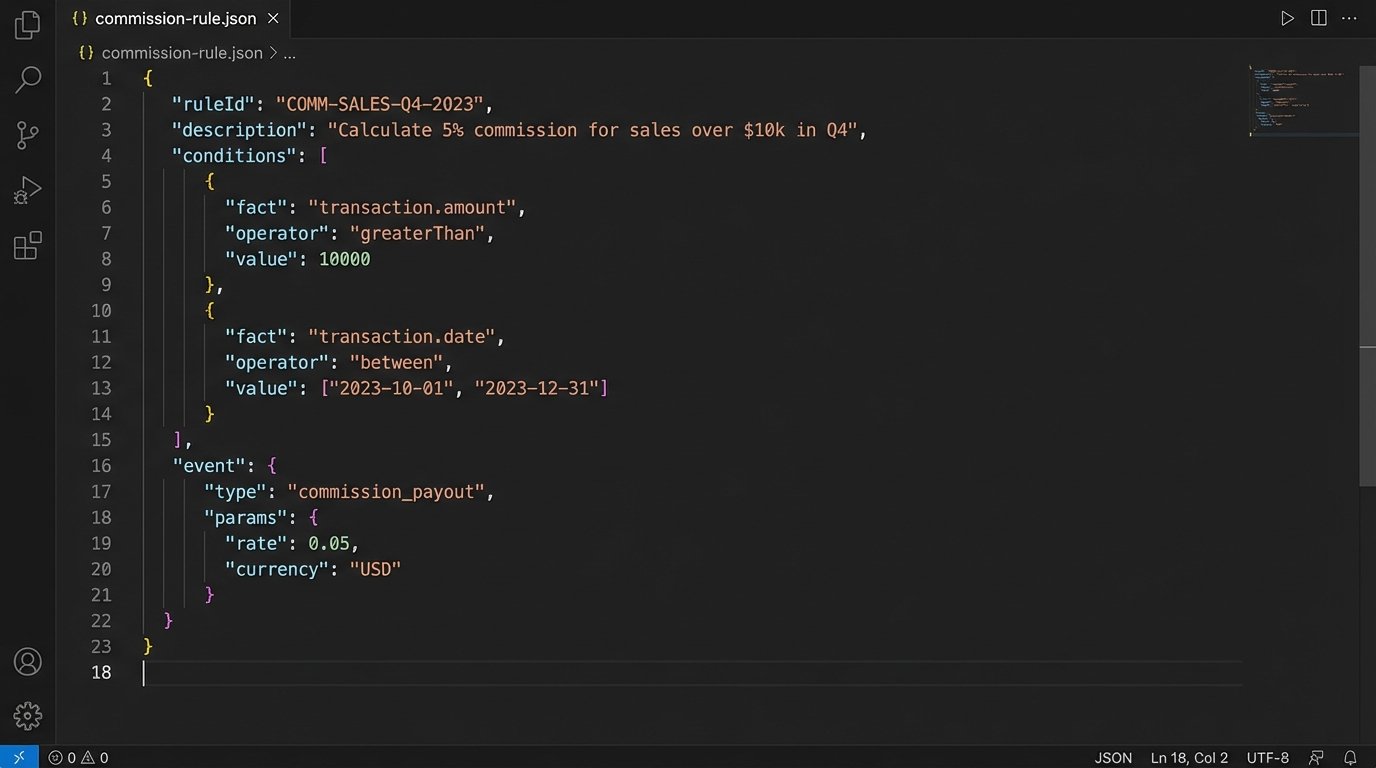
Here is a simplified JSON structure for a commission rule. It defines conditions and an outcome. The application just needs to be a dumb interpreter of this structure.
{
"ruleId": "split-tier-1",
"description": "Standard 80/20 split for agents with less than $5M annual volume",
"conditions": {
"all": [
{
"fact": "agent.annualVolume",
"operator": "lessThan",
"value": 5000000
},
{
"fact": "transaction.type",
"operator": "equal",
"value": "sale"
}
]
},
"event": {
"type": "calculateSplit",
"params": {
"agentSplit": 0.80,
"brokerageSplit": 0.20
}
}
}
This approach separates the “what” from the “how”. The operations team defines “what” the rule is. The engineering team builds the system that knows “how” to execute it. This is a critical separation of concerns for any business that needs to adapt quickly.
Mistake 5: Manual Provisioning and Deprovisioning
Every time an agent joins, someone on your team follows a checklist to create their accounts in a dozen different systems. Email, CRM, MLS access, transaction management, Slack, and so on. When an agent leaves, the same process happens in reverse. This manual work is slow, error-prone, and a massive security hole. Former agents with lingering access to sensitive data are a liability.
This process has to be automated. At a minimum, you should have a set of scripts that can be triggered to perform these actions. The ideal state is to have a central identity provider (IdP) like Okta or Azure AD. Your HR system should be the trigger. A new hire in the HR system automatically kicks off the provisioning workflow in the IdP, which then uses protocols like SCIM to create accounts in downstream applications.
Deprovisioning is even more important. When an agent is terminated in the HR system, the workflow should immediately disable all their access. Not at the end of the day. Immediately. This requires that all your critical systems support single sign-on (SSO) and SCIM. When you are choosing new SaaS tools, this capability should be a non-negotiable requirement.
The upfront cost and complexity of setting up a proper IAM system seems high. But the cost of a single data breach caused by a disgruntled former agent with access to your CRM is much higher. It’s an investment in operational sanity and security.
Mistake 6: Ignoring the Need for an Audit Log
When a commission payment is wrong or a critical document is missing, the first question is “who did what, and when?” Without a detailed, immutable audit log, you have no answer. An audit log is not the same as your application’s debug logs. It’s a structured, permanent record of significant business events.
Every state-changing action in your system should generate an audit entry. `User X updated commission on Transaction Y from A to B at Timestamp Z.` This data should not be stored in your primary application database where it can be tampered with. It should be streamed to a separate, secure data store, like a dedicated logging service or a blockchain-style immutable ledger if you need to be paranoid.
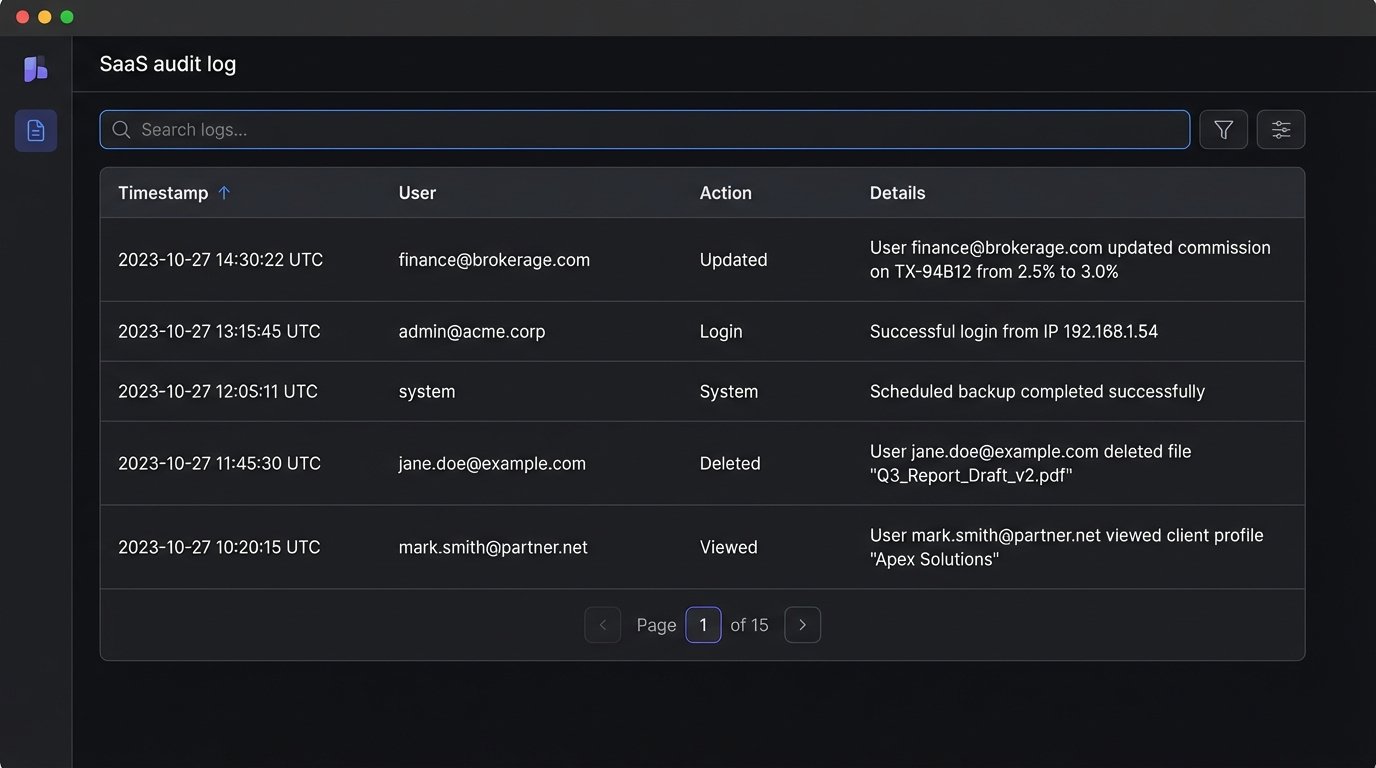
This log is not just for forensics. It’s a business intelligence goldmine. You can analyze it to find process bottlenecks or identify users who may need more training. A good audit log is a feature, not just a technical chore. When you are asked to prove compliance to a regulator, a searchable, coherent audit log is your best defense.
Building a scalable brokerage is less about brilliant innovation and more about disciplined avoidance of these common, unforced errors. The goal is not a system that never fails. It’s a system that fails in predictable, isolated, and recoverable ways. That is the difference between a platform that grows and one that collapses.