
Best Practices for Communicating Protocols with Automation Tools
Automation breaks not because the code is wrong, but because the protocol assumptions were wrong. The gap between the API’s documentation and its real-world behavior is where production incidents are born. We are not just sending data. We are engaging in a defensive contract negotiation between machines, and the goal is to build a system that doesn’t page you at 3 AM when a third party decides to add a new, undocumented field to a JSON payload.
Effective protocol communication is about anticipating failure. It demands a paranoid mindset where you treat every external endpoint as unreliable and every payload as potentially hostile until proven otherwise. The following practices are not suggestions. They are the hard-learned guardrails that separate a brittle script from a resilient automation platform.
1. Schema Enforcement is Non-Negotiable
Receiving a dynamic JSON payload from an API and immediately trying to access keys is a rookie mistake. It assumes the remote server will always honor a contract it may have never formally agreed to. The automation logic is then forced to perform constant null checks and type verifications, polluting the core code with defensive boilerplate. This approach is fragile and leads directly to `KeyError` or `TypeError` exceptions in production.
The correct method is to validate the payload against a strict schema definition before your business logic ever touches it. Tools like JSON Schema allow you to define the expected structure, data types, required fields, and even value constraints of an incoming payload. Your code ingests the raw data, forces it through the schema validator, and only proceeds if the contract is met. If validation fails, the process stops immediately and logs a structured error detailing the exact contract violation.
This front-loads your error handling. You catch the deviation at the boundary of your system, not deep inside a processing function three calls down the stack. Consider this simple schema for a user object.
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "User",
"description": "A user profile from the external service",
"type": "object",
"properties": {
"userId": {
"description": "The unique identifier for the user",
"type": "integer"
},
"email": {
"description": "User's email address",
"type": "string",
"format": "email"
},
"status": {
"description": "Account status",
"type": "string",
"enum": ["active", "suspended", "pending_verification"]
}
},
"required": ["userId", "email", "status"]
}
This isn’t just documentation. It’s executable code that prevents a malformed user object from ever entering your workflow. Your automation logic should never have to guess the data type.
2. Idempotency Keys Are Your Safeguard Against Network Chaos
Network connections flicker. A POST request to create a resource might time out, leaving your client in a state of uncertainty. Did the request reach the server? Did the server process it but fail to send a response? Running the automation again risks creating a duplicate resource, which can range from an annoyance to a critical billing error. This is a classic distributed systems problem that many APIs solve with idempotency keys.
The mechanism is straightforward. For any state-changing request (POST, PUT, PATCH), the client generates a unique identifier, often a UUID, and includes it in a header like `Idempotency-Key: your-unique-uuid-here`. The first time the server sees this key, it processes the request and stores the result mapped to that key. If it sees the exact same key again within a certain time window, it bypasses the processing logic and simply returns the stored result from the first request. This guarantees that a duplicate network call does not result in a duplicate action.
Checking an API’s documentation for idempotency support should be one of your first steps. If it’s not supported, you are now responsible for building your own state-tracking system to prevent duplicate operations. This is a massive engineering tax that involves maintaining a database of transaction IDs and logic-checking against it before every call. This is the difference between a clean retry loop and a duplicate billing incident.
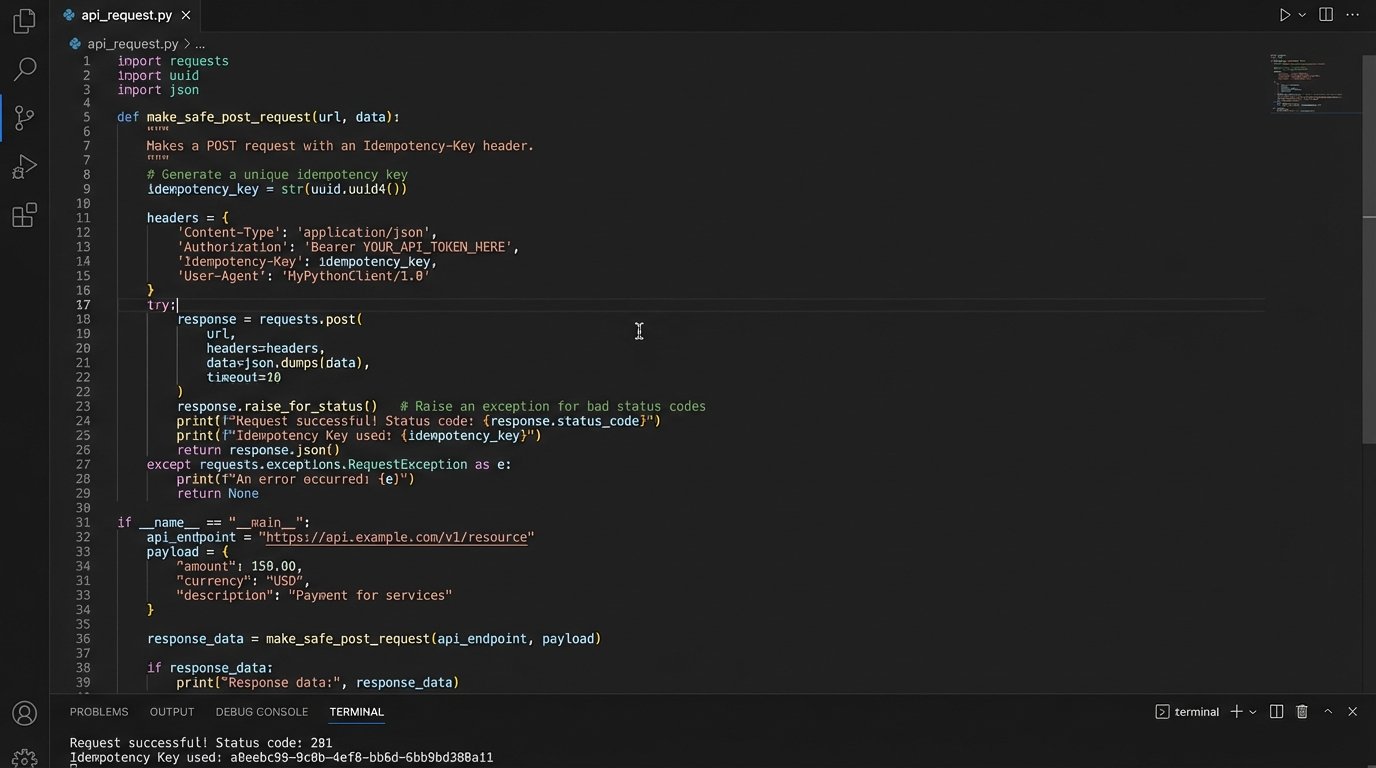
3. Log the Full Request and Response Body
A log entry that just says “API call failed with status 500” is functionally useless for debugging. It tells you that something broke, but provides zero context about why. Was your request malformed? Did you send an invalid authentication token? Did the server itself encounter an unhandled exception? You have no way of knowing without the full context of the transaction.
Your logging standard for any external API call must include the full HTTP request and response. This means capturing:
- The target URL and HTTP method.
- All request headers, especially `Authorization` and `Content-Type`.
- The full request body.
- The HTTP status code of the response.
- All response headers.
- The full response body.
Yes, this creates more log data. Storage is cheap. Your time spent trying to reproduce an intermittent production failure is not. The only caveat is security. You must implement a mechanism to scrub sensitive data like API keys, passwords, and personally identifiable information (PII) from the logs before they are written to disk. The goal is to have enough information to perfectly replay a failed request in a development environment. Anything less is just guesswork.
4. Decouple Protocol Handling From Business Logic
Your core automation workflow should not be concerned with the specifics of HTTP. It should not be littered with retry logic for 503 errors, JSON parsing `try-except` blocks, or rate limit backoff timers. Mixing this low-level protocol management with high-level business logic creates code that is difficult to read, impossible to test, and a nightmare to maintain.
The solution is architectural. Build a dedicated API client or connector layer that acts as a boundary. This layer’s sole responsibility is to manage the messy reality of network communication. It handles authentication, builds the requests, parses responses, enforces schemas, and implements retry strategies. This layer then presents a clean, simple interface to the rest of your application. For example, instead of making a raw HTTP call, your business logic calls a function like `api_client.get_user(user_id=123)`. That function either returns a clean, validated data object or raises a specific, typed exception like `UserNotFoundException` or `ApiRateLimitExceededException`.
Treating an external API as a black box is like trying to wire a server rack blindfolded. You might get power, but you will probably fry something expensive. This abstraction allows you to mock the entire API for unit testing and isolates all the protocol-specific code in one place. Your business logic should not know what HTTP is.
5. Explicitly Version Your API Calls
Relying on an API’s default or “latest” version is a ticking time bomb. The provider can roll out a “non-breaking” change, like adding a new optional field or slightly restructuring a nested object, that your automation’s parser was not built to handle. Suddenly, your script, which was working perfectly an hour ago, starts failing for no apparent reason. You didn’t change your code, but the contract you were relying on was silently altered.
Reputable APIs offer versioning, typically through a URL path (`/api/v2/resource`) or a custom request header (`Accept: application/vnd.company.v2+json`). Your automation must explicitly request a specific, stable version in every single call. This pins your code to a known, documented contract. When the API provider releases v3, your v2 calls continue to work unchanged. This gives your team the breathing room to analyze the v3 changes, adapt the code, and cut over on your own schedule, not during an emergency patch. Failing to version-pin is choosing to let a third party dictate your deployment schedule.
6. Use Webhooks Instead of Constant Polling
Polling is a crude and inefficient method of checking for updates. It involves your system repeatedly asking an API, “Is there anything new yet?” This generates a high volume of useless network traffic, burns through your API rate limit, and introduces latency between when an event occurs and when your system detects it. It is the technical equivalent of repeatedly hitting refresh on a web page.
Webhooks provide a superior, event-driven alternative. Instead of you calling the API, the API calls you. You provide the external service with a URL, your webhook endpoint, and subscribe to specific events. When one of those events occurs, the service immediately sends an HTTP POST request to your endpoint with a payload describing the event. This is more efficient, provides real-time updates, and is far more scalable.
Implementing a webhook receiver requires some infrastructure. You need a publicly accessible endpoint, a robust mechanism for validating the incoming request’s signature to prevent spoofing, and a queue to buffer incoming events so you do not drop data during a traffic spike. Here is a trivial example using Flask to show the signature validation concept.
import hmac
import hashlib
from flask import Flask, request, abort
app = Flask(__name__)
WEBHOOK_SECRET = 'your_shared_secret_here'
@app.route('/webhook-receiver', methods=['POST'])
def handle_webhook():
signature_header = request.headers.get('X-Webhook-Signature')
if not signature_header:
abort(400, 'Signature header is missing.')
# Recalculate the signature based on the request body and secret
payload_body = request.get_data()
digest = hmac.new(WEBHOOK_SECRET.encode('utf-8'),
msg=payload_body,
digestmod=hashlib.sha256).hexdigest()
# Compare signatures
if not hmac.compare_digest(digest, signature_header):
abort(403, 'Invalid signature.')
# Signature is valid, queue the payload for processing
print("Received valid webhook:", request.json)
return ('', 204)
if __name__ == '__main__':
app.run(port=5000)
Polling is banging on the door. Webhooks are a doorbell.
7. Actively Simulate Failure Modes in Staging
Testing your automation against a perfectly functioning staging API is a recipe for overconfidence. Production environments are chaotic. APIs experience outages, return malformed data, or suffer from performance degradation. Your automation must be built to survive these conditions. The only way to validate its resilience is to simulate these failures before they happen in production.
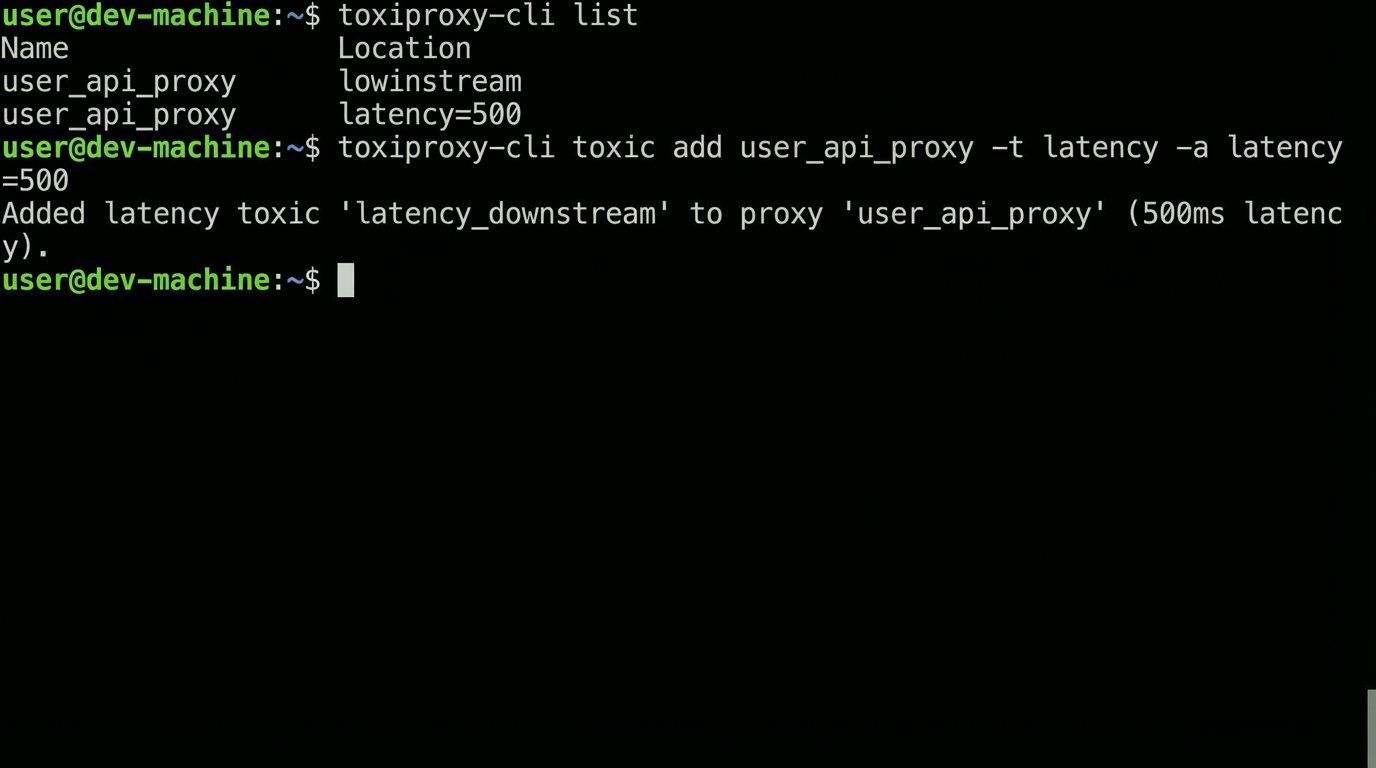
Integrate failure injection into your testing process. Use tools like `toxiproxy` to sit between your application and the API endpoint, allowing you to programmatically introduce problems. Configure it to inject high latency, randomly drop connections, or return HTTP 503 errors on a percentage of requests. Send malformed JSON payloads or empty response bodies. This is how you pressure-test your retry logic, your circuit breaker patterns, and your dead-letter queueing.
You want to discover how your system behaves under duress in a controlled environment, not during a high-stakes production outage. If your automation crumbles when the API response time increases by 500 milliseconds, you need to know that long before your customers do.
The protocol is the contract between your automation and the outside world. Your code must act as a ruthless contract lawyer, validating every clause and preparing for every possible breach. This discipline to build defensively at the protocol level is the boring, invisible foundation that allows clever automation to run reliably without constant human intervention.