
The pitch for no-code in real estate is always the same. It promises to democratize development, allowing brokerages to stitch together complex workflows without writing a single line of code. They sell a drag-and-drop utopia where a marketing coordinator can integrate the MLS feed with the CRM before lunch. This is a dangerous fantasy built on a misunderstanding of the industry’s core technical problem: the data is an absolute mess.
Real estate data isn’t clean. It isn’t standardized. It’s a chaotic soup of competing standards, inconsistent field names, and data entry errors from a thousand different sources. Believing a visual workflow builder can tame this beast without creating a brittle, unmaintainable tangle of logic is a fast path to production failure.
The Initial Appeal is the Trap
I get the attraction. Someone sees a demo connecting a web form to Mailchimp and the gears start turning. They think, “We can use this to sync new listings to our agent roster.” The first few connections are simple and they work. It provides a dopamine hit of instant gratification that bypasses the typical development cycle. This initial success is the bait.
These platforms excel at simple, one-way data pushes. A new lead from Zillow gets injected into Follow Up Boss. A signed document in DocuSign triggers a notification in Slack. These are linear, low-stakes operations. The problem starts when the business begins to view this tool as the central nervous system for all operations, especially those requiring bidirectional syncs or complex data transformations. They get hooked on the perceived speed, ignoring the technical debt accumulating with every new workflow.
Where the Abstraction Collapses
The primary failure point for no-code in real estate is data normalization. The Real Estate Standards Organization (RESO) provides a Data Dictionary, but its adoption is inconsistent. A single brokerage might pull data from three different Multiple Listing Services (MLS). One MLS might label a property status as “Active,” another uses “A,” and a third might have five variations like “Active-Contingent” or “Active-Kick Out.”
A no-code tool attempts to solve this with visual conditional logic. You end up with a sprawling diagram of branching paths, filters, and formatters for every possible input variation. After handling just two MLS feeds, the workflow is already difficult to read. Add a third, and it becomes a nightmare to debug. When a fourth MLS is onboarded, nobody on the team wants to touch the thing. Trying to build a reliable data processing engine this way is like trying to build a transmission out of Legos. The pieces fit, but it will grenade itself under the first real load.
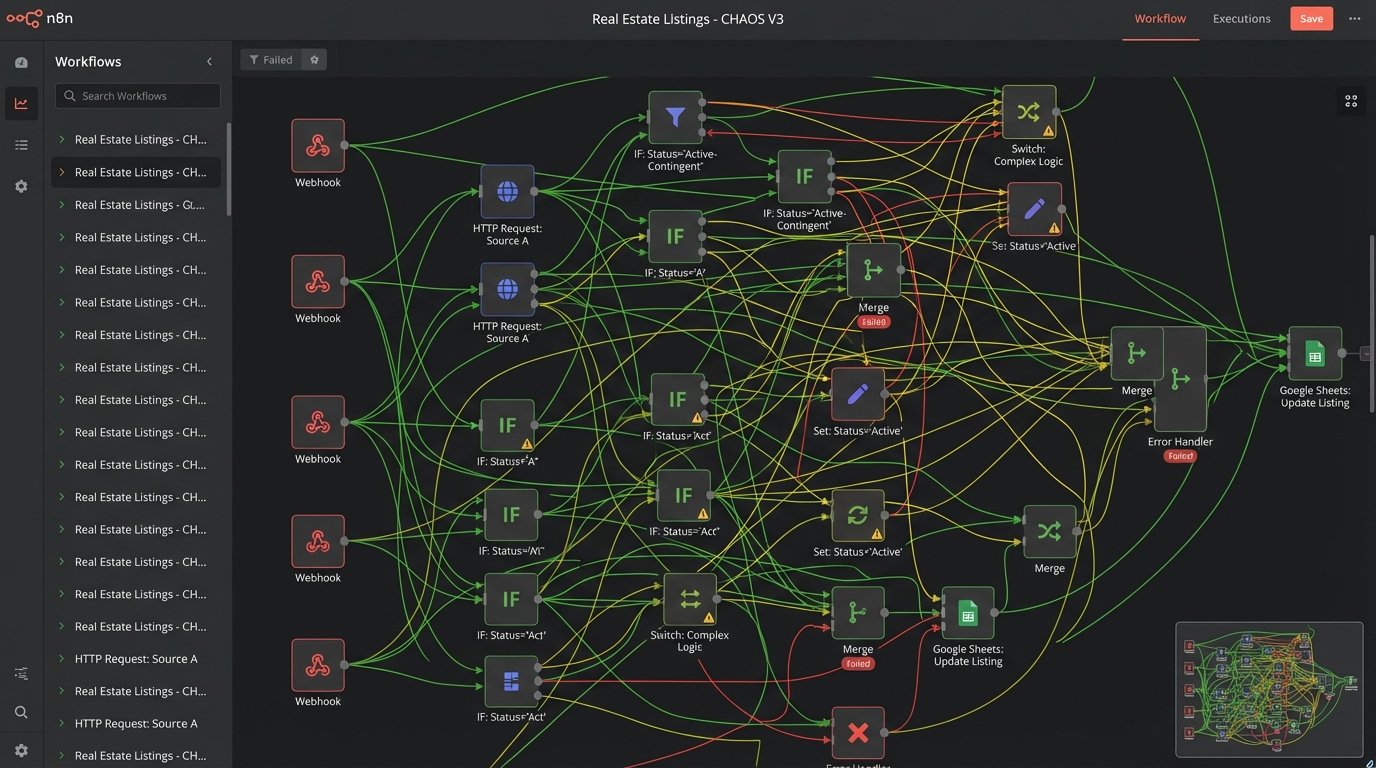
This visual mess is not just an aesthetic problem. It’s a maintenance black hole. When a workflow fails because a new status like “Active-Lease” appears, you have to visually trace every path to find the break. There’s no clean, searchable code. There’s just a web of boxes and arrows that documents its own complexity poorly.
Code Handles Variation with Precision
Compare that visual spaghetti to a simple Python dictionary used for normalization. We can map dozens of input variations to a clean, standardized output in a way that is immediately readable and easy to update. This is not complex code. It’s a basic data structure that is infinitely more scalable than a visual logic tree.
def normalize_property_status(raw_status):
"""Normalizes status from various MLS sources to a standard set."""
status_map = {
# Standard Active Statuses
'active': 'Active',
'a': 'Active',
'act': 'Active',
# Contingent Statuses
'active contingent': 'Contingent',
'ac': 'Contingent',
'contingent': 'Contingent',
'active-kick out': 'Contingent',
# Pending Statuses
'pending': 'Pending',
'p': 'Pending',
'under contract': 'Pending',
# Default for unknown statuses
'default': 'Unknown'
}
# Strip whitespace and convert to lower case for a reliable lookup
lookup_key = str(raw_status).lower().strip()
return status_map.get(lookup_key, status_map['default'])
# Example Usage
print(normalize_property_status(' active ')) # Output: Active
print(normalize_property_status('P')) # Output: Pending
print(normalize_property_status('Active-Kick Out')) # Output: Contingent
print(normalize_property_status('For Rent')) # Output: Unknown
The code is self-documenting. The logic is centralized. Adding a new mapping takes seconds and carries almost zero risk of breaking an unrelated logic path. This is the kind of surgical precision required to handle the grit of real-world real estate data. No-code platforms simply cannot offer this level of clarity and control.
The Hidden Tax of No-Code Platforms
Beyond the logic limitations, no-code tools impose a hidden tax on performance, observability, and budget. These platforms are black boxes. When a workflow executes, you have little to no visibility into the underlying operations. This creates serious, practical problems in production environments.
API Call Bloat
No-code connectors are notoriously inefficient. To provide a user-friendly interface, they make assumptions and perform extra background steps. A simple “update a contact record” action might look like one step in the UI. Under the hood, the platform could be making four or five API calls: one to authenticate, one to fetch the record’s schema, one to get the record itself, one to validate the update, and a final one to post the change. We once diagnosed a workflow that was hitting Salesforce API rate limits constantly. The no-code tool was using 10 API calls to perform a task our own script could accomplish in two. When you’re processing thousands of listings a day, this inefficiency becomes a system-killer.
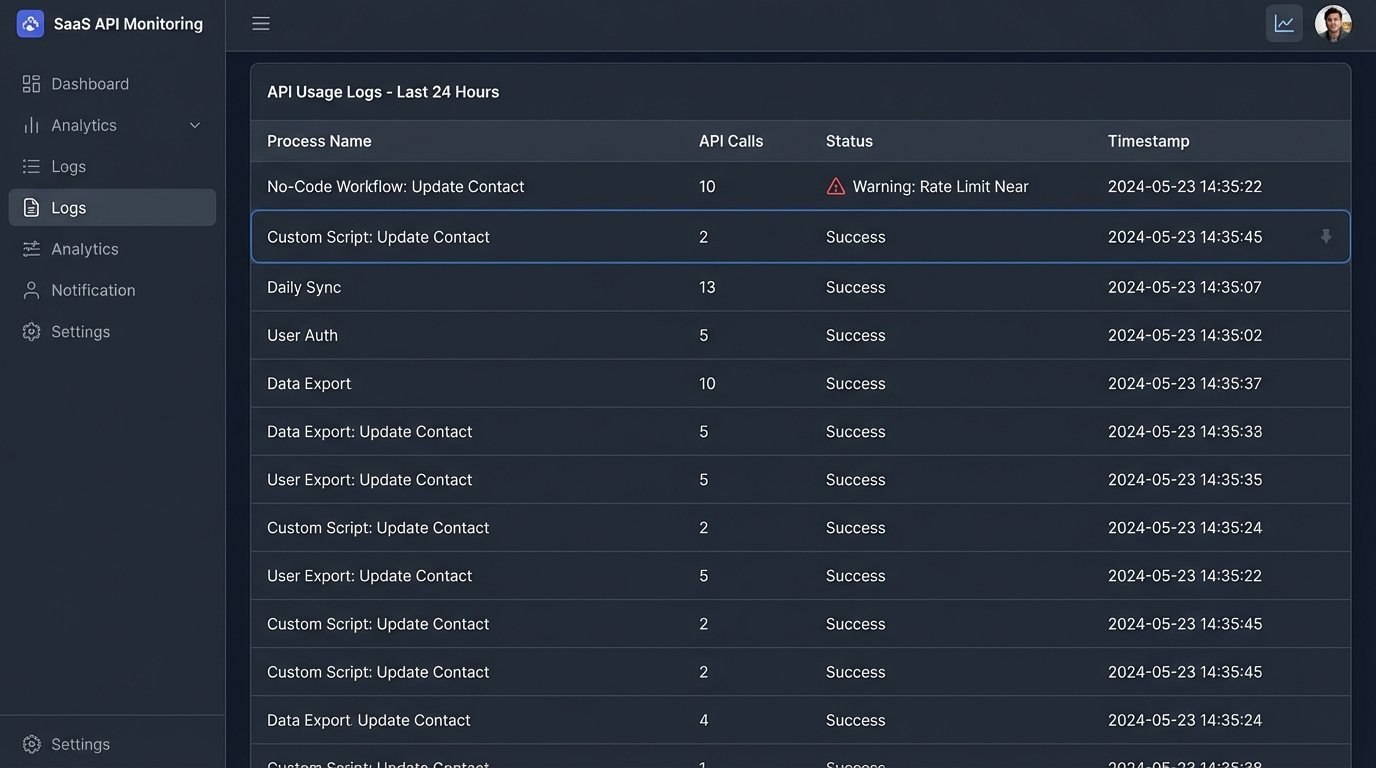
Debugging by Guesswork
When a scripted integration fails, you have logs. You have stack traces. You can inspect the exact payload sent and the raw error response received from the API. This is fundamental to troubleshooting. In a no-code world, the error message is often a uselessly generic “Step 3: Update Record Failed.” You can’t see the payload. You can’t see the HTTP status code. You’re left guessing. Was it a malformed field? A permissions issue? A temporary network blip? You’re debugging blind, and that’s an unacceptable risk for any core business process.
The Wallet-Drainer Scaling Model
The pricing models are designed to get you in cheap and make it painful to leave. They charge per “task,” “operation,” or “run.” At low volumes, the cost seems negligible. As your brokerage grows and transaction volume scales, these costs compound exponentially. A workflow that cost 50 dollars a month can easily swell to 5,000 dollars a month. By that point, your most critical business processes are built on the platform. Migrating away is no longer a simple project, it’s a full-scale digital transformation that requires rewriting every piece of logic from scratch. You are completely locked in.
A Hybrid Architecture That Actually Works
The solution is not to ban no-code tools entirely. They have a place. The key is to enforce strict architectural boundaries. We must separate the chaotic, high-stakes work of core data processing from the simple, linear tasks at the edge of the business.
We build a defensible architecture that treats no-code as a consumer of clean data, not the processor of raw data.
- The Code-First Core: All mission-critical data integrations, transformations, and synchronizations are built with code. This “core engine” is the single source of truth. It’s responsible for ingesting raw data from every MLS, county record source, and third-party API. It normalizes, validates, and cleanses this data before storing it in a central database. This engine lives in a proper development environment with version control, automated testing, and detailed logging.
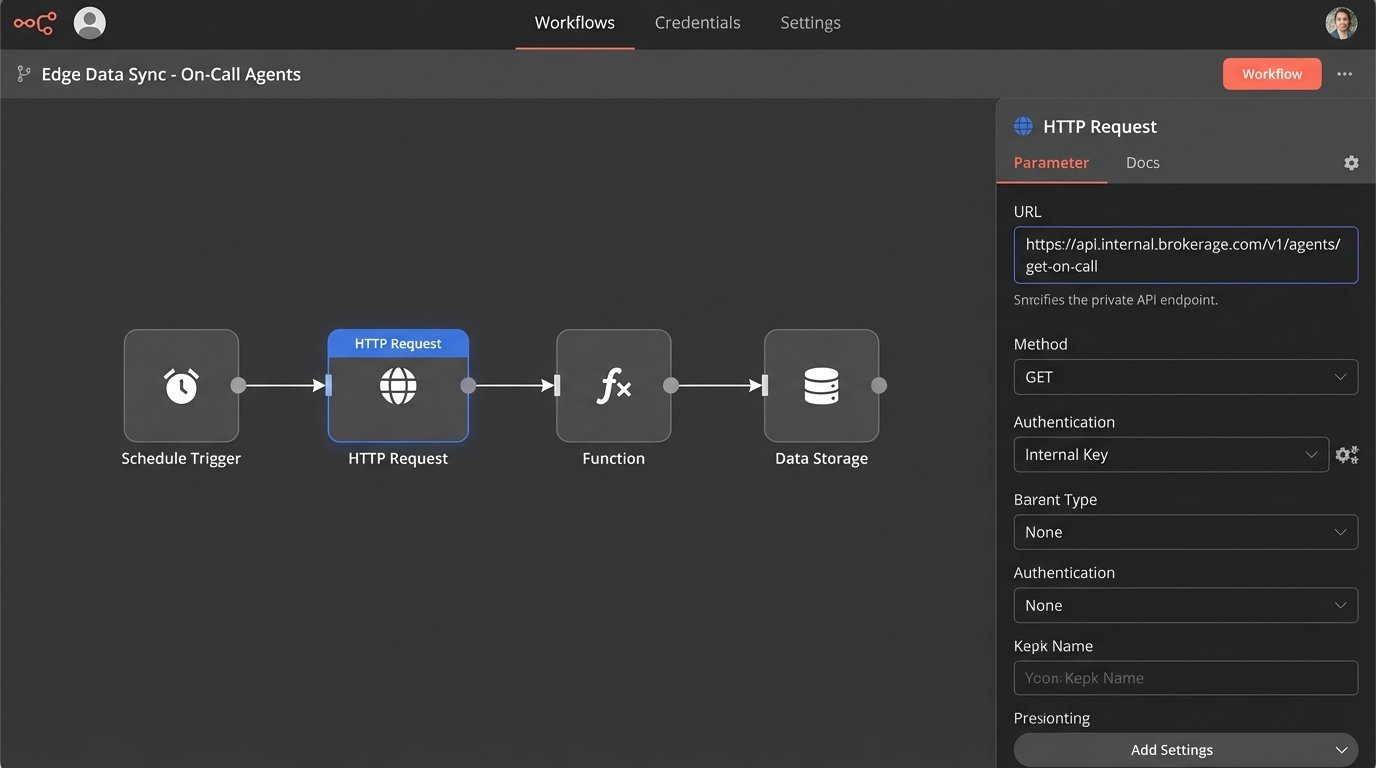
- The API Bridge: The core engine does not talk directly to end-user applications. Instead, it exposes a set of clean, stable, internal APIs. These endpoints provide predictable, standardized data. For example, instead of letting a no-code tool connect directly to an MLS feed, we provide an internal `/listings/{listingId}` endpoint that always returns a perfectly formatted JSON object, regardless of the original data source.
- No-Code at the Edge: With this architecture in place, we can safely let the business use no-code tools. Their workflows no longer connect to the messy, unreliable external sources. They connect to our stable internal APIs. A marketing person can now build a workflow that says, “When a new lead is created in our CRM, call our internal `/agents/get-on-call` endpoint to find the right agent, then assign the lead.” The complex logic is handled by the core; the no-code tool just orchestrates the final, simple steps.
Our Job is to Manage Technical Risk
The push for no-code is a push for expediency over stability. As engineers and architects, our job is to inject the necessary friction to prevent short-term shortcuts from becoming long-term disasters. It’s about building systems that are observable, maintainable, and resilient. A system that doesn’t collapse because an MLS provider decided to change `ListingPrice` to `ListPrice` without notice.
No-code tools are not a replacement for development. They are a limited tool for a specific subset of problems. In real estate, where the primary challenge is wrestling with chaotic data, relying on these tools for core processes is architectural malpractice. The real competitive advantage is built by mastering that data chaos with robust, maintainable code, not by pretending it can be solved with a drag-and-drop interface.