Every integration project starts with a clean diagram and a promise of seamless data flow. The project ends with a frantic Slack message about duplicate records in production. The gap between those two points is filled with unhandled exceptions, undocumented API behaviors, and a fundamental misunderstanding of what it takes to bridge two independent systems. These are the mistakes that turn a simple integration into a technical debt sinkhole.
1. Blindly Trusting the API Documentation
API documentation is marketing material written by people who often do not maintain the production service. It describes the “happy path,” where every request is perfect and every response is a 200 OK. Your perfect logic will shatter the first time you encounter a 502 Bad Gateway response that the documentation completely ignores. The listed rate limits might be from two versions ago, and the example objects often omit the null fields that will break your data parser.
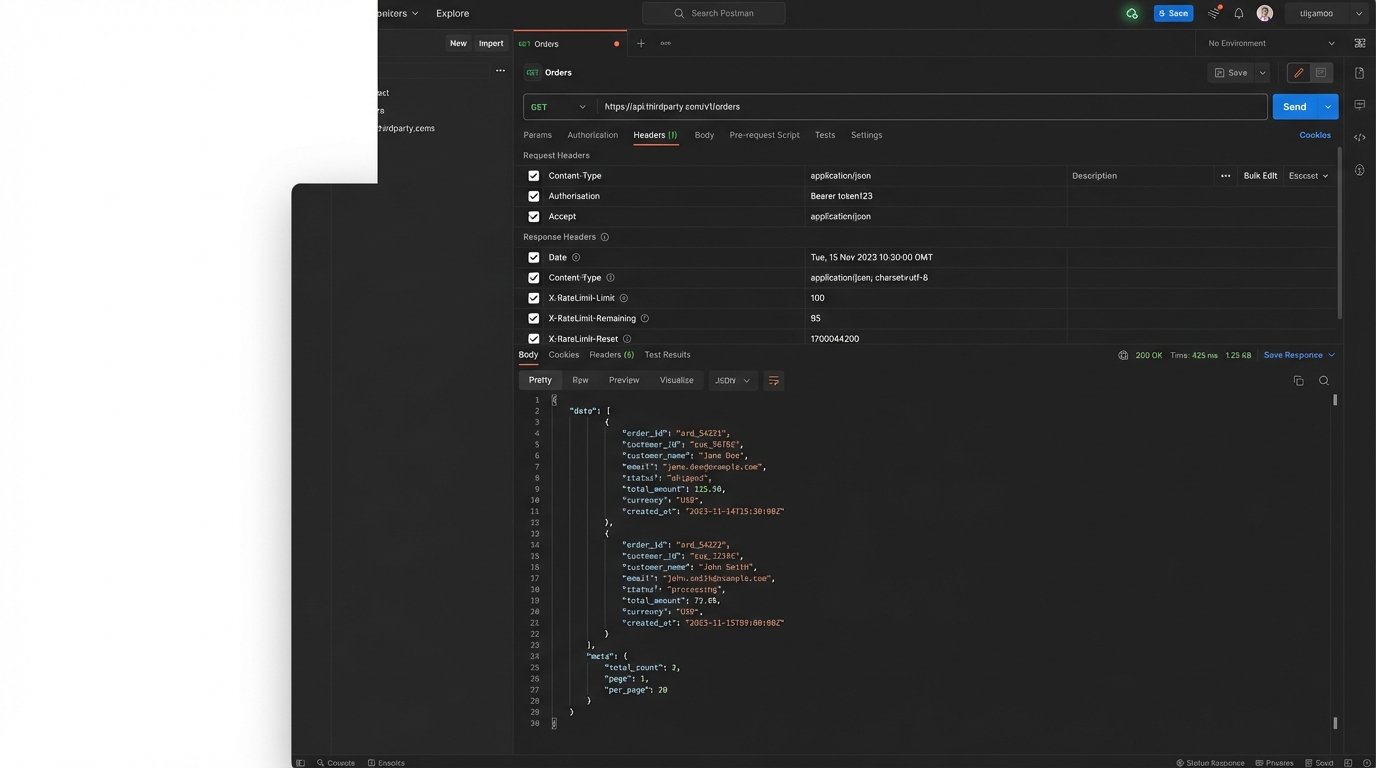
Stop writing code based on a PDF. Before a single line is written, you must probe the API directly. Use a tool like Postman or Insomnia to manually construct and send requests. Test the authentication mechanism. Intentionally send malformed data to see what a 400 Bad Request actually looks like. Check the response headers for undocumented rate limit information like X-RateLimit-Remaining. This is not optional reconnaissance; it’s a mandatory system check.
You need to verify the actual contract, not the advertised one.
Validate the Endpoint Manually
A simple curl command is often enough to expose discrepancies between the documentation and reality. You can check headers, response times, and the raw payload before committing to a specific parsing strategy. Look for things the documentation never mentions, like character encoding or pagination tokens that are structured differently than described.
# Check headers and response for a paginated resource
curl -i -X GET "https://api.thirdparty.com/v1/orders?limit=1" \
-H "Authorization: Bearer YOUR_API_KEY"
This simple check can save you hours of debugging a library that assumes the API behaves as advertised.
2. Ignoring Rate Limits and Throttling
Rate limits are not a negotiation. When a third-party API says you get 100 requests per minute, they are not giving you a friendly guideline. They are telling you that on request 101, you will get a 429 Too Many Requests response, and your automation will stop dead. Many junior engineers build an integration that works perfectly for a single record, only to watch it collapse under a minor production load that triggers the rate limit within seconds.
The solution requires building a system that respects these limits from the start. This means implementing a queuing mechanism or, at a minimum, a robust retry strategy with exponential backoff and jitter. Exponential backoff increases the wait time between retries after each failure. Jitter adds a small, random amount of time to that backoff, preventing multiple instances of your service from retrying in perfect sync and hammering the API all at once after a failure.
Failing to plan for this is planning for your service to fail.
Implement a Retry with Exponential Backoff
Your HTTP client needs to be smarter than a simple loop. It must handle transient errors like 429 or 503 by waiting and trying again. The wait time should not be fixed. A basic implementation in Python shows how to exponentially increase the delay, preventing a failing service from DDoSing its own dependency.
import requests
import time
def request_with_backoff(url, headers, max_retries=5):
delay = 1 # Start with a 1-second delay
for i in range(max_retries):
try:
response = requests.get(url, headers=headers)
if response.status_code == 429:
print(f"Rate limit hit. Retrying in {delay} seconds...")
time.sleep(delay)
delay *= 2 # Double the delay for the next potential retry
continue
response.raise_for_status() # Raise HTTPError for other bad responses (4xx or 5xx)
return response
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}. Retrying in {delay} seconds...")
time.sleep(delay)
delay *= 2
raise Exception("Max retries exceeded")
Without this logic, your integration is brittle and will fold under pressure.
3. Fumbling Data Transformation
No two systems store data in the same way. The source system’s `customer_id` is an integer, but the destination system expects a string called `externalClientId`. Your integration code becomes the translator. A common mistake is to litter this transformation logic throughout the application. You end up with a dozen different places that convert integers to strings or remap field names, creating a maintenance disaster when one of the APIs inevitably changes its schema.
Data transformation must be centralized. Create a dedicated module or service whose only job is to convert an object from System A’s format to System B’s format. This layer validates incoming data, handles nulls gracefully, sets default values, and logs any data that cannot be cleanly mapped. This approach isolates the messy work of data mapping into one place, making it easy to test and update. Trying to map inconsistent data structures on the fly is like forcing a firehose of water through the eye of a needle. It’s messy and something is going to break.
Your integration’s reliability depends entirely on its ability to handle bad data.
4. Having No Idempotency Strategy
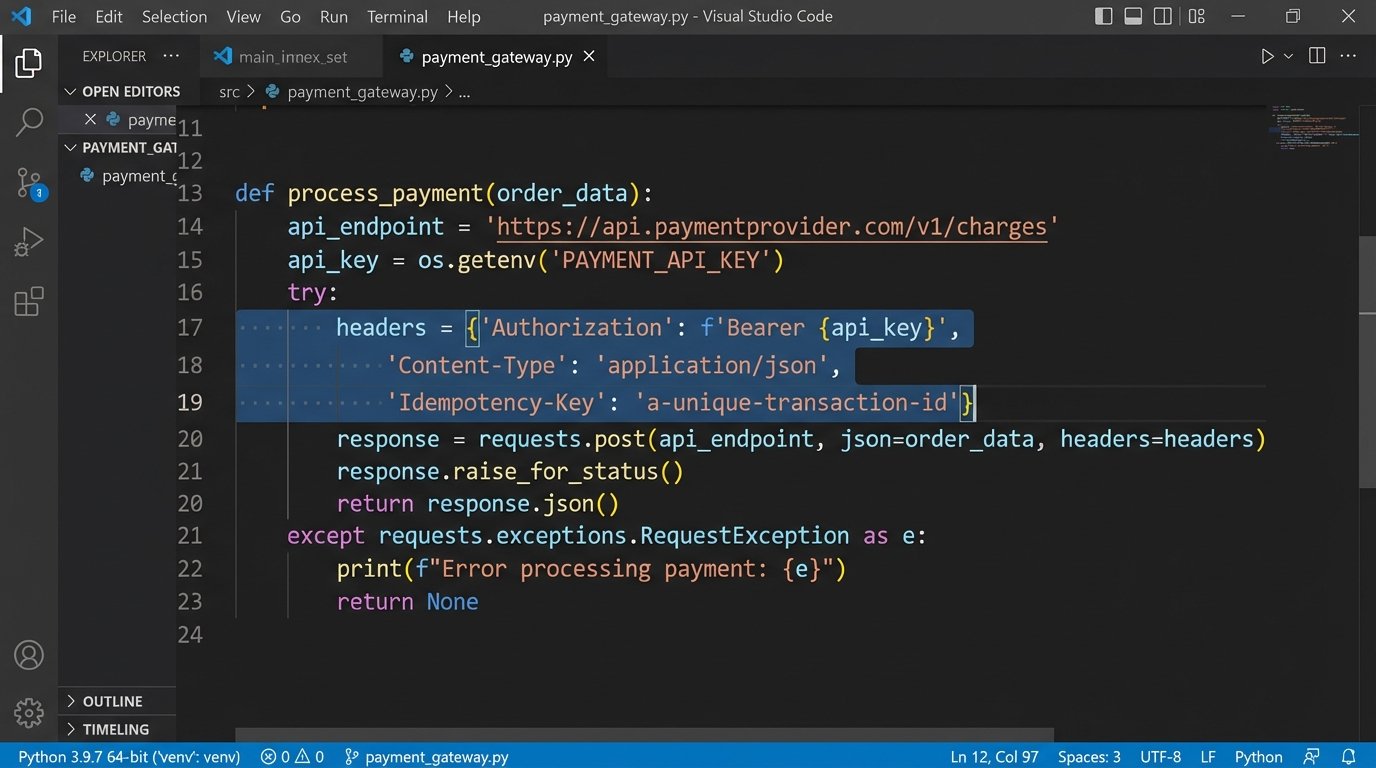
Imagine your script to process a payment successfully sends the request to the payment gateway, but your own network connection drops before you get the “success” response. Your error handling logic kicks in and dutifully retries the request. The customer has now been charged twice. This is a failure of idempotency. An idempotent operation is one that can be performed multiple times with the same result as if it were performed only once.
Many modern APIs support idempotency by allowing you to pass a unique key in the request header, like Idempotency-Key: some-unique-value. The API server stores this key and the result of the first request. If it sees another request with the same key, it simply returns the stored result without re-processing the transaction. If the target API does not support this, you must build it yourself by maintaining a cache (using something like Redis) of processed transaction IDs to check against before sending a request.
Skipping this step is a direct path to data corruption.
5. Neglecting Granular Error Handling and Logging
A generic catch (Exception e) block is useless. It tells you that something failed, but provides no path to a solution. Effective error handling requires differentiating between error types. A network timeout (a transient error) should be retried. A 401 Unauthorized (a permanent error) should never be retried; it indicates a configuration problem that requires human intervention and should trigger an immediate alert.
Your logs must contain enough context to reproduce the failure. This means logging the full request body (with sensitive data like passwords or tokens redacted), the endpoint URL, and the exact response received from the server. Without this information, you are flying blind during an outage. Structured logging in a format like JSON is critical. It allows you to easily search and filter logs in a tool like Splunk or Datadog to find all failed requests for a specific customer or endpoint.
If you can’t debug it from the logs, your logging is insufficient.
6. Hardcoding Credentials and Endpoints
Checking API keys, tokens, or even environment-specific URLs into source control is a rookie mistake with severe consequences. It is a security risk and a maintenance nightmare. When an API key needs to be rotated or the staging environment URL changes, you should not have to redeploy your application. This is a simple configuration change, and your architecture should treat it as such.
Configuration must be externalized. Use environment variables or a dedicated secrets management service like AWS Secrets Manager or HashiCorp Vault. Your application should read its configuration at startup. This decouples the code from the environment it runs in, allowing the same application artifact to be promoted from development to staging to production without any code changes.
import os
# Read configuration from environment variables, not hardcoded strings
API_KEY = os.environ.get("THIRD_PARTY_API_KEY")
API_BASE_URL = os.environ.get("THIRD_PARTY_API_URL", "https://api.default.com")
if not API_KEY:
raise ValueError("API key is not configured in environment variables.")
Code that is tied to a specific environment is inherently broken.
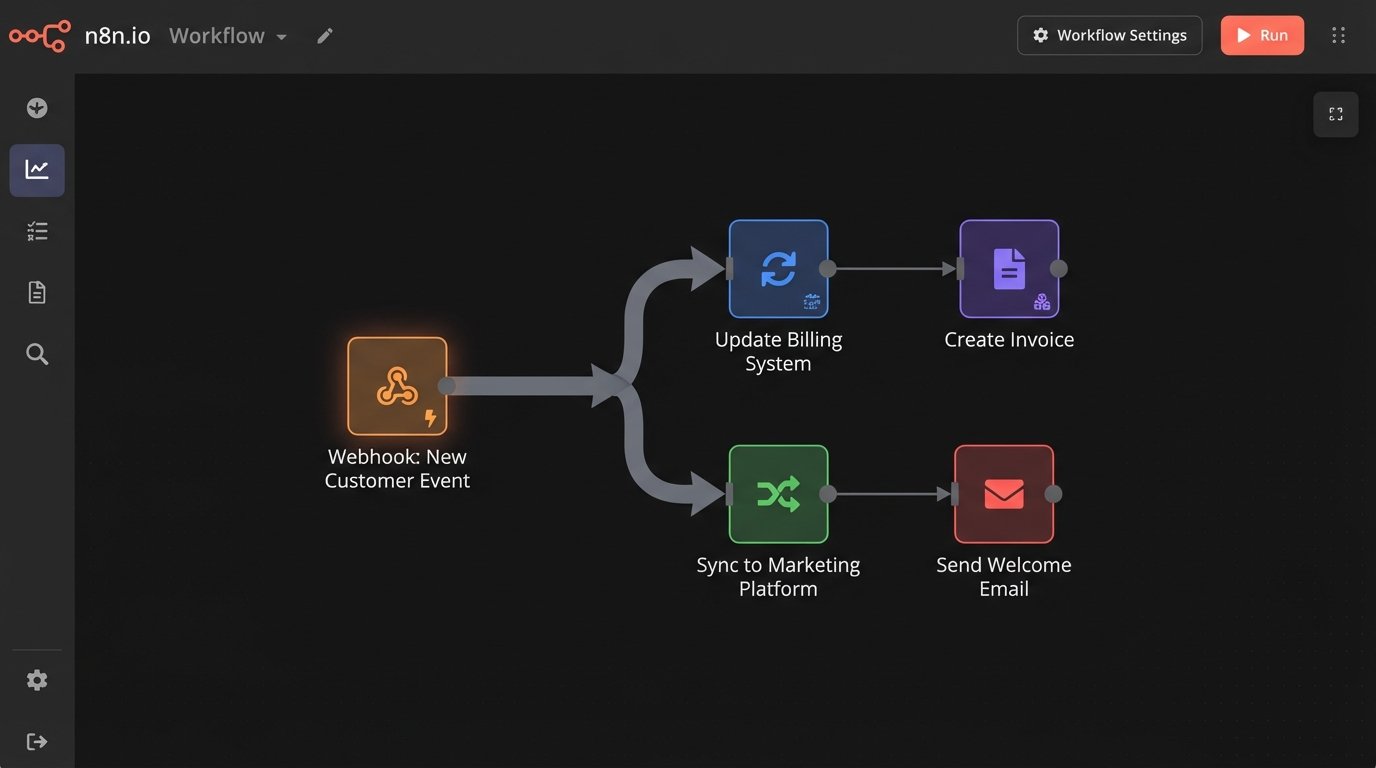
7. Building a Point-to-Point Spaghetti Monster
Your first integration connects your CRM to your billing system. Then marketing needs CRM data, so you build another direct link. Then support needs billing data, so you build a third. You now have a tightly coupled mess. When the CRM’s API changes, two separate integrations break. This point-to-point architecture does not scale. It creates a brittle web where a failure in one system can cascade and take down others.
A better approach for complex environments is to use a central event bus or message queue. Instead of System A calling System B directly, System A publishes a generic “customer created” event to a central topic. The billing system and the marketing system both subscribe to this topic and react accordingly. This decouples the systems. If the marketing integration fails, it has no impact on the billing integration. Adding a new system is as simple as creating a new subscriber; the core CRM publisher does not need to change at all.
This architecture is more work upfront, but it is the only way to build a maintainable and scalable integration ecosystem.