
Stop Calling It AI. It’s A Data Problem.
The term “AI” gets thrown around in real estate tech until it means nothing. Most platforms claiming artificial intelligence are just wrapping a basic scikit-learn model around a CSV file and calling it revolutionary. The real work, the part that actually generates alpha, isn’t the model. It’s the brutal, thankless job of data aggregation and sanitation that happens before a single prediction is ever made. Waiting for the perfect, off-the-shelf AI tool is a losing strategy. The advantage goes to the teams who build the data plumbing now.
Your competition isn’t building a better neural network. They are building a better data pipeline.
The fragmented Hellscape of Real Estate Data
Every major real estate operation runs on a disastrously fragmented data architecture. The core listing data comes from one of hundreds of local MLS boards, each with its own bizarre schema, custom fields, and update frequency. You pull that data via a RESO Web API if you’re lucky, or you’re stuck screen-scraping some archaic RETS feed that looks like it was designed in 1998. Then you have to join that with property tax data from county assessor APIs, which are often poorly documented, rate-limited, and spit out XML.
You need flood zone data from FEMA, school district ratings from a third-party service, and permit history from municipal databases that might not even have an API. Each source is a new integration headache. Each requires its own parser, its own error handling logic, and its own normalization routine to force it into a usable structure. This is the ground truth of real estate data science.
A pretty dashboard showing “market trends” is useless if the underlying data is a toxic sludge of mismatched identifiers and un-validated inputs.
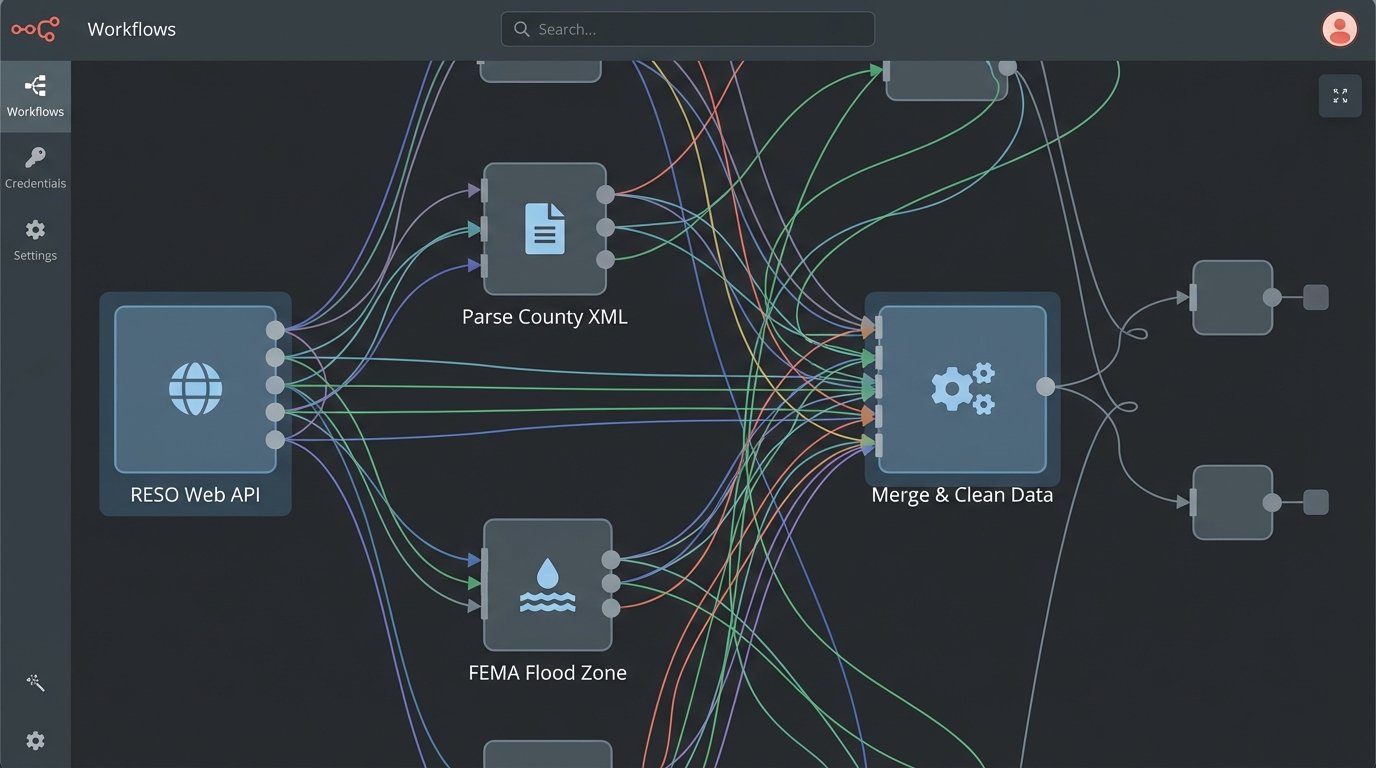
Building the Unsexy Foundation
Early adoption isn’t about buying a subscription to the latest “AI-powered CMA generator.” It’s about allocating engineering resources to build a centralized, canonical data store for your target markets. This means writing the Python scripts to poll 20 different sources, developing the logic to deduplicate properties that appear in multiple feeds with slightly different addresses, and versioning the data so you can track changes over time. It’s about building a system that can logic-check incoming data for sanity. Is a property listed with 97 bathrooms and a sale price of $50? Your system needs to flag that automatically, not pollute your valuation models.
This is a data engineering problem first and a machine learning problem second. The teams that build this foundation now will have a proprietary data asset that is impossible for a new competitor to replicate quickly. They can buy the same modeling tools you can. They cannot instantly replicate five years of painstakingly aggregated and cleaned historical data.
The resulting asset is the moat. The AI is just the cannon you put on the castle wall.
Beyond AVMs: Predictive Analytics on Unstructured Data
Automated Valuation Models (AVMs) are the most obvious application. But a robust data pipeline opens up far more interesting possibilities. Think about predictive market analysis. The sale price of a home is a lagging indicator. The real leading indicators are buried in unstructured text data. Planning commission meeting minutes, new construction permit applications, local news articles about a major employer moving in or out, even sentiment analysis on community social media groups.
To tap into this, you need an NLP pipeline. This involves scraping these sources, stripping out the boilerplate HTML, and feeding the raw text into classification and named-entity recognition (NER) models. The goal is to automatically tag documents with topics like “zoning variance approved,” “new infrastructure project,” or “commercial redevelopment.” You can train a model to extract key entities like addresses, developer names, and project budgets. This isn’t magic. It requires tedious work of labeling training data and fine-tuning models like BERT for your specific domain.
Trying to process this volume of text manually is like trying to shove a firehose of information through the keyhole of a human analyst. You need automated systems to filter the noise and surface the signals.
A Conceptual Data Pipeline
Building a proprietary AVM is a clear example of where early adoption pays off. A third-party AVM API gives you a single number with zero transparency. Building your own forces you to control the inputs and understand the model’s biases. The process requires a strict, sequential flow of data processing that highlights the engineering challenge.
The code to orchestrate this isn’t complex, but it’s unforgiving. A failure at any step poisons everything downstream. Here’s a stripped-down conceptual look at what such a pipeline might involve, using Python for orchestration.
class PropertyDataPipeline:
def __init__(self, property_id):
self.property_id = property_id
self.raw_data = {}
self.cleaned_data = {}
self.features = {}
def fetch_mls_data(self, api_client):
# Connect to RESO Web API, handle pagination and rate limits
# Throws ConnectionError on failure
self.raw_data['mls'] = api_client.get_listing(self.property_id)
print(f"MLS data fetched for {self.property_id}")
def fetch_tax_data(self, county_api_client):
# Connect to county assessor's XML or JSON endpoint
# Often requires parsing non-standard address formats
address = self.raw_data.get('mls', {}).get('FullAddress')
if address:
self.raw_data['tax'] = county_api_client.get_assessment(address)
print(f"Tax data fetched for {self.property_id}")
else:
raise ValueError("Missing address from MLS data.")
def clean_and_merge_data(self):
# The core ETL nightmare lives here.
# Force data types, handle nulls, normalize field names.
mls_record = self.raw_data.get('mls', {})
tax_record = self.raw_data.get('tax', {})
# Example: Mismatched date formats
listing_date_str = mls_record.get('ListingDate')
# ... logic to parse 'YYYY-MM-DDTHH:MM:SSZ' ...
# Example: Conflicting values
mls_sqft = int(mls_record.get('LivingArea', 0))
tax_sqft = int(tax_record.get('CalculatedSqFt', 0))
# Logic to reconcile differences, maybe default to tax data
self.cleaned_data['square_feet'] = tax_sqft if tax_sqft > 0 else mls_sqft
self.cleaned_data['bedrooms'] = int(mls_record.get('BedroomsTotal', 0))
self.cleaned_data['bathrooms'] = float(mls_record.get('BathroomsTotal', 0.0))
self.cleaned_data['last_sale_price'] = float(tax_record.get('LastSalePrice', 0.0))
print(f"Data cleaned and merged for {self.property_id}")
def generate_features(self):
# Create model-ready features from cleaned data.
# This is where domain expertise is injected.
if self.cleaned_data:
self.features['price_per_sqft'] = self.cleaned_data['last_sale_price'] / self.cleaned_data['square_feet'] if self.cleaned_data['square_feet'] > 0 else 0
self.features['baths_to_beds_ratio'] = self.cleaned_data['bathrooms'] / self.cleaned_data['bedrooms'] if self.cleaned_data['bedrooms'] > 0 else 0
# ... add dozens more features ...
print(f"Features generated for {self.property_id}")
def run_pipeline(self, mls_client, tax_client):
try:
self.fetch_mls_data(mls_client)
self.fetch_tax_data(tax_client)
self.clean_and_merge_data()
self.generate_features()
return self.features
except Exception as e:
print(f"Pipeline failed for {self.property_id}: {e}")
return None
This is a gross simplification. A production system needs robust logging, retry mechanisms for failed API calls, and a validation layer to quarantine bad data. But it illustrates the point: the value is created in the `clean_and_merge_data` method, not in the final `model.predict()` call.
The Economic Case: Cost of Delay vs. Cost of Build
The pushback is always about cost. Building this infrastructure is not cheap. It requires dedicated data engineers, cloud infrastructure for storage and compute, and API subscription fees. The alternative, however, is strategic oblivion. While your firm waits for the market to produce a perfect, all-in-one solution, your more aggressive competitors are building a proprietary data asset one API at a time.
By the time a viable off-the-shelf product does appear, your competitors will have years of clean, historical data to train their own models, giving them a massive accuracy advantage. They can spot sub-market trends weeks or months before you can because their systems are already wired into the raw data feeds. They will be able to ask more sophisticated questions of their data because they control the entire stack.
Delaying this build-out is a bet that no one else is doing it either. That is a bad bet.
Operationalizing the Output
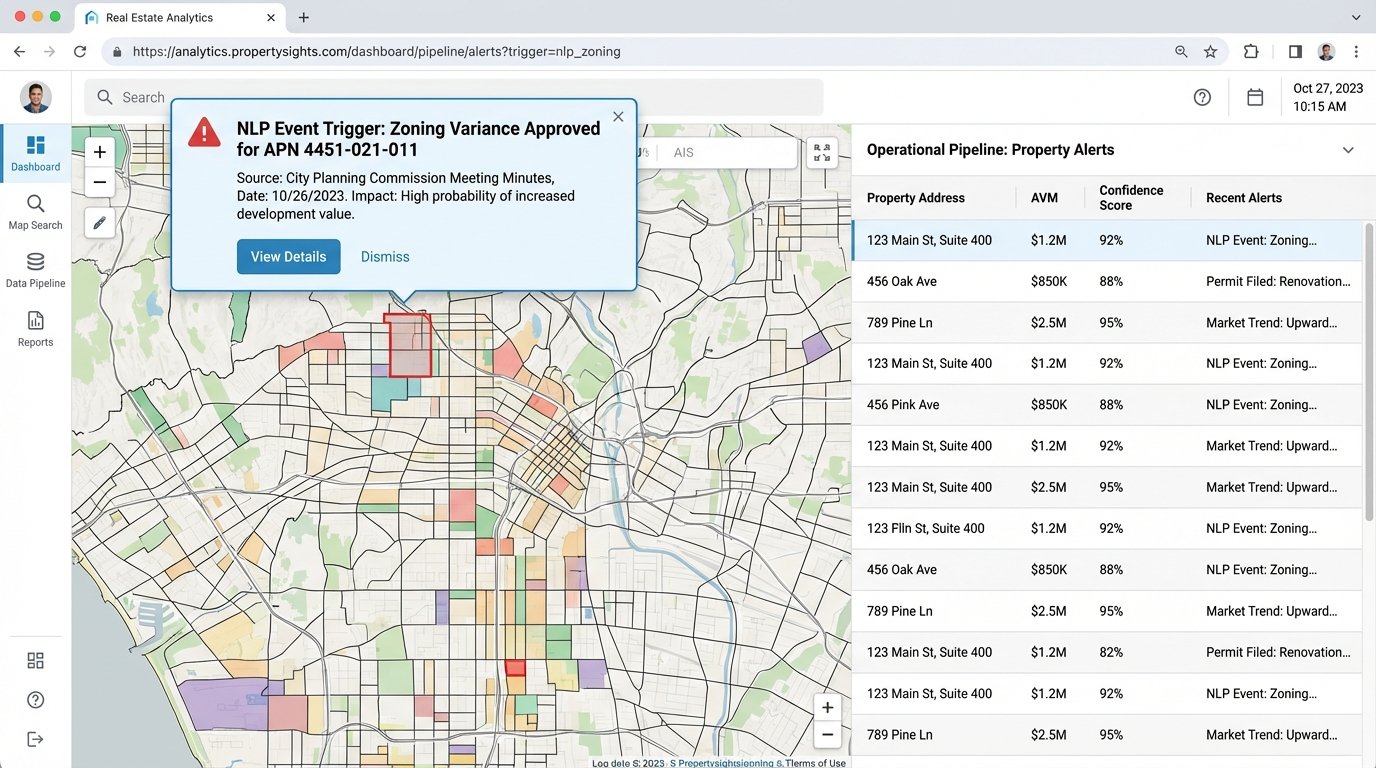
A data asset is only valuable if it gets used to force decisions. The output of these pipelines cannot live in a database that only engineers can query. It needs to be pushed into the tools that agents and analysts use every day. This means building internal APIs to serve model predictions to your CRM, creating automated alerting systems for market events, and generating visualizations that make complex trends obvious at a glance.
For example, when the NLP pipeline detects that a major zoning variance has been approved for a specific parcel, that event should trigger an automated workflow. An alert could be sent to agents specializing in that neighborhood. The parcel could be flagged in your internal mapping tools. The expected value uplift could be automatically factored into valuation models for adjacent properties. This closes the loop between data collection and business action.
Without this final step of operational integration, all you have is an expensive science project.
The Mandate is Clear
The conversation about AI in real estate needs a hard reset. Forget the marketing hype and focus on the fundamental engineering challenge. The strategic advantage over the next decade will not go to the company that buys the best AI tool. It will go to the company that builds the best data backbone.
Start now. Allocate the budget for one data engineer and a cloud account. Pick one market and one data source. Start pulling the data, cleaning it, and storing it. It will be slow, expensive, and frustrating. And it’s the only way to build a durable, long-term competitive edge in a market that is finally being forced into a data-driven reality.