
The Automation Paradox: More Code, More Problems
Every vendor pitch promises the same dream. A “lights-out,” fully autonomous system that reduces headcount and eliminates human error. They sell a dashboard with green lights and a future where PagerDuty is silent. The reality is a 3 AM alert about a zombie process consuming 100% CPU because a third-party API changed a minor version number without notice. The automation did exactly what it was told. That was the problem.
The core of the issue is this: automation is a force multiplier, not a substitute for cognition. We build scripts to execute logic, but logic is brittle. It cannot account for the contextual drift that defines every production environment. We are not building systems to replace engineers. We are building tools to arm them, and the distinction is critical. Believing otherwise is how you end up debugging a cascading failure with a sales executive breathing down your neck.
The Brittle Logic of the Unattended Script
A script is an artifact of a point in time. It reflects the state of the system, the APIs, and the operational requirements on the day it was written. We deploy a Python script to rotate application logs on a fleet of servers. It checks file sizes, compresses old logs to a network share, and deletes the originals. It works perfectly for six months. Then, a new application version starts logging errors in a multiline JSON format that our simple line-parser can’t handle. The script no longer recognizes the log size correctly. The disk fills up. The application crashes.
The script did not fail. It executed its logic flawlessly based on outdated assumptions. The environment outgrew the automation. Relying on a script to handle unexpected API changes is like sending a Roomba to clean up a chemical spill. It has a single function and zero situational awareness. A human engineer would have seen the new log format during deployment checks or noticed the anomalous disk usage patterns days before the failure. That pattern recognition is not something you can easily code.
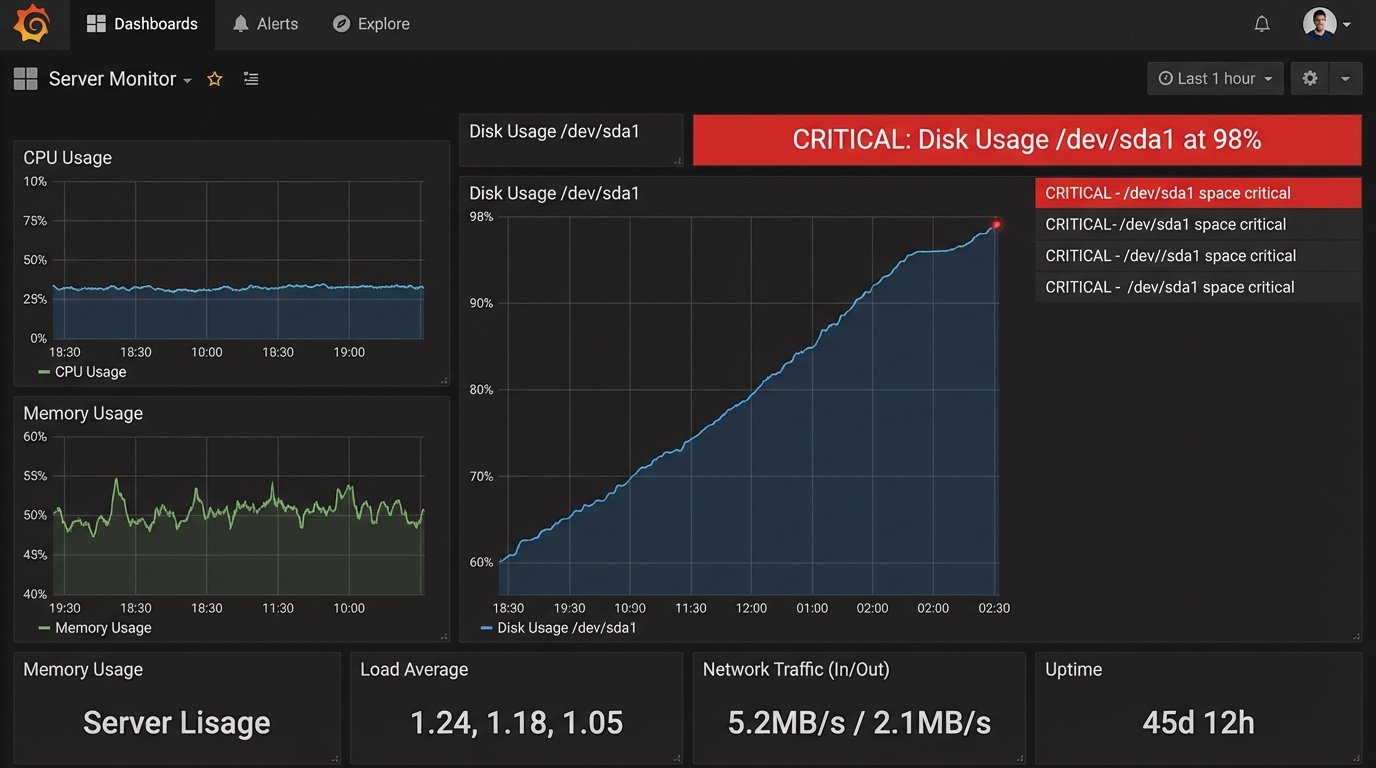
This is the trap of set-and-forget automation. The systems we manage are not static entities. They are organic, chaotic, and constantly being changed by dozens of other teams. A change in a CI/CD pipeline, a new security agent, or a minor patch to the OS can introduce side effects that our automation is blind to. The human role is not just to fix the break. It is to anticipate it through strategic monitoring and a deep understanding of the entire stack.
The Unreliable API Contract
Modern infrastructure is built on APIs. We bridge services, pull data, and trigger actions through countless HTTP requests. Each one is a contract, an assumption that the endpoint will behave as documented. This assumption is frequently wrong. Rate limits are enforced inconsistently, error messages are cryptic, and data schemas get modified with a commit message reading “minor updates.”
Consider an observability platform that pulls metrics from a cloud provider’s API. Your whole team depends on these dashboards to monitor application health. One morning, the graphs for a key service are flatlined. The automation shows no errors. A junior engineer might assume the service is just idle. A senior engineer knows that no errors is, itself, an error condition. You dig into the logs of the metric collector and find a flood of `403 Forbidden` responses that the script’s generic exception handler was silently swallowing.
It turns out the cloud provider deprecated the old authentication key format, a change announced in a blog post nobody read. A human sees the pattern of `403` errors and immediately suspects an authentication or authorization problem. The script just sees an exception, logs it to a file that’s never reviewed, and moves on. The monitoring blind spot grows until an actual outage occurs.
This is why robust error handling is not enough. You need logic that understands the *meaning* of different errors. A `503 Service Unavailable` is a transient issue you should retry. A `404 Not Found` could mean a misconfiguration. A `403 Forbidden` is a hard stop that requires immediate human intervention. Coding this level of nuance for every single API call is impractical.
A Simple Case of Naive Logic
Look at this basic function to fetch user data. It handles a generic exception, which is better than nothing, but it treats a network timeout the same as a permissions error. This is dangerous.
import requests
def get_user_data(api_key, user_id):
"""Naive function that hides critical error details."""
try:
headers = {'Authorization': f'Bearer {api_key}'}
response = requests.get(f'https://api.example.com/users/{user_id}', headers=headers)
response.raise_for_status() # Raises HTTPError for bad responses (4xx or 5xx)
return response.json()
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}") # Generic, unhelpful log
return None
A more responsible approach separates concerns. It specifically logic-checks for different status codes and prepares for intervention. The automation doesn’t try to solve the problem. It triages it for the human who can.
import requests
import logging
# Assume logging is configured elsewhere
def get_user_data_robust(api_key, user_id):
"""Better function that distinguishes between error types."""
try:
headers = {'Authorization': f'Bearer {api_key}'}
response = requests.get(f'https://api.example.com/users/{user_id}', headers=headers)
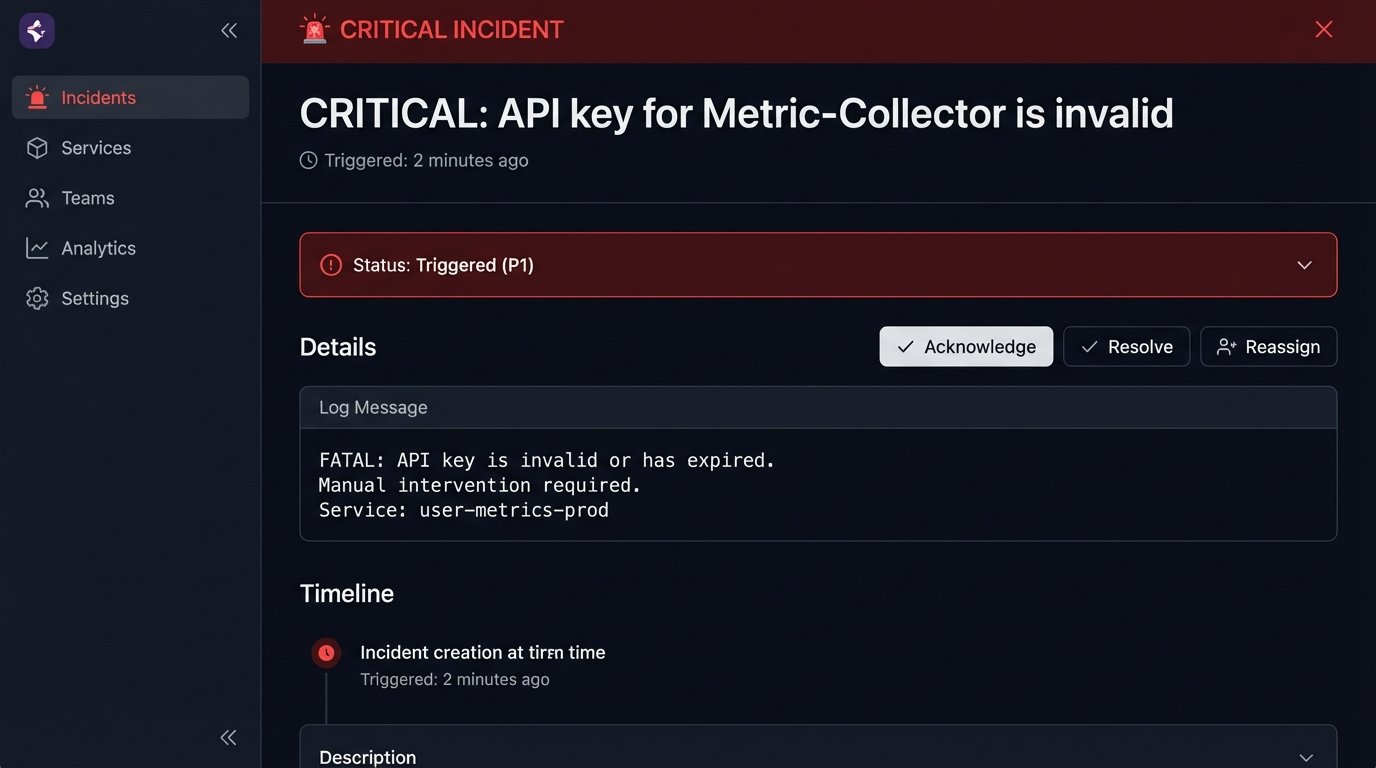
if response.status_code == 403:
logging.critical("FATAL: API key is invalid or has expired. Manual intervention required.")
# Trigger a high-priority alert (e.g., PagerDuty)
return None
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as e:
logging.warning(f"HTTP error for user {user_id}: {e.response.status_code}")
# Could trigger a lower-priority ticket
return None
except requests.exceptions.RequestException as e:
logging.error(f"Network-level error fetching user {user_id}: {e}")
# Likely a transient issue, maybe retry logic belongs here
return None
The second script is not fully “automated.” It is designed to fail intelligently and hand control over to a human operator when it encounters a problem it cannot, and should not, solve on its own.
The Data Interpretation Gap
Automation is excellent at collecting and aggregating data. It can ingest terabytes of logs, metrics, and traces. It can put them on a graph. It cannot, however, tell you what they mean in the context of your business. A dashboard showing a 50% spike in database queries is just data. A human provides the interpretation: “That’s not a performance problem. That’s the marketing team running their end-of-quarter report, it happens every time.”
Security tooling is a perfect example of this gap. An anomaly detection system might flag a developer for cloning a large number of repositories from the company’s source control. The automated response, configured by a well-meaning but context-free security team, is to lock the developer’s account and open a tier-one support ticket. The developer is now blocked for hours, derailing a critical project.
An experienced engineer on that developer’s team would have known they were setting up a new build server, a task that requires checking out the code for multiple services. That human has the business context. The automation only has a statistical baseline. Without a human in the loop to apply that context, the automation becomes a source of friction, not a solution. We create automated roadblocks that require more human hours to bypass than the original manual process took.
The “Self-Healing” Fallacy
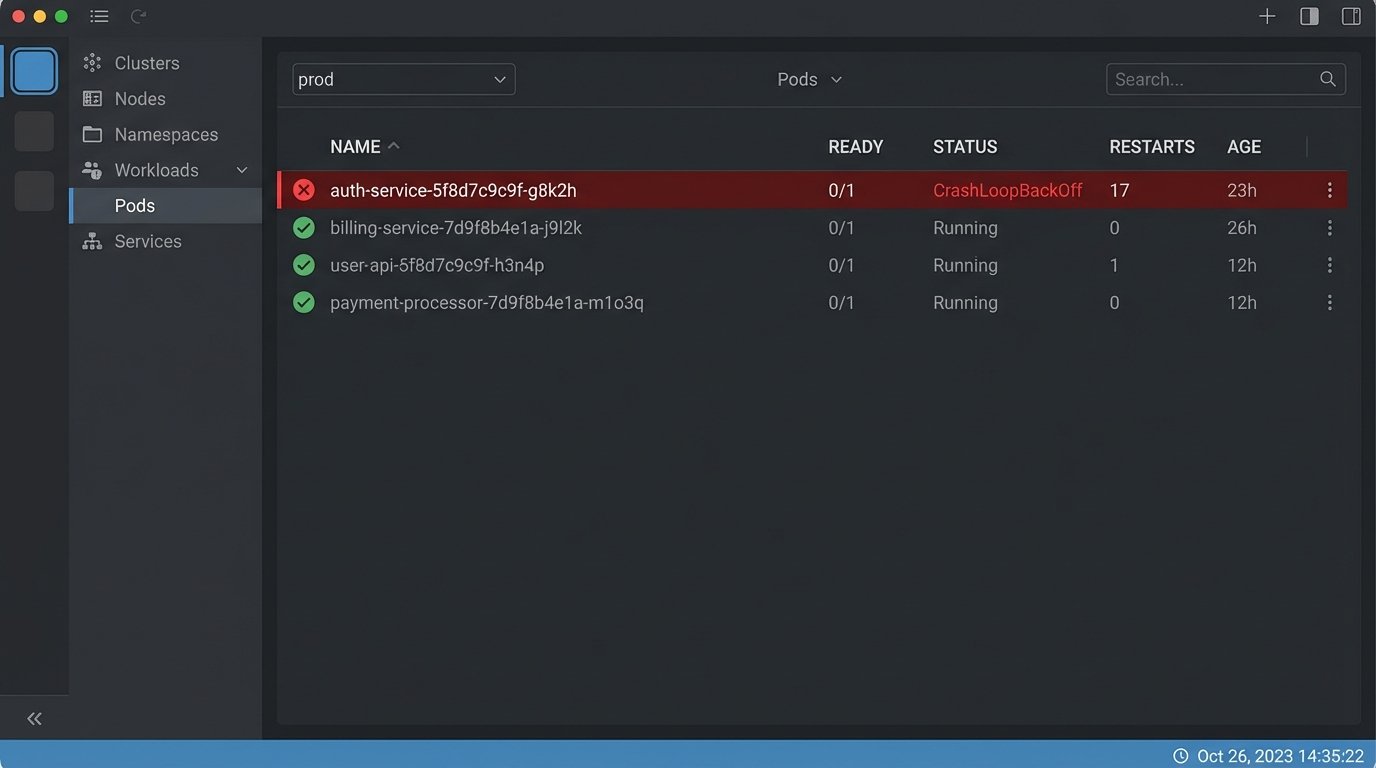
The term “self-healing” is vendor marketing at its finest. In practice, it usually means “automated restart.” A Kubernetes liveness probe fails, so the orchestrator kills the pod and starts a new one. The application has a memory leak, so the pod crashes and gets restarted. The system is “healthy” again, but the underlying problem is never addressed. The constant restarts just mask the bug while burning CPU and creating noise in the logs.
This is not healing. This is automated denial. The system is in a persistent state of failure, but the orchestrator’s simple logic loop presents a facade of stability. A true healing process requires diagnosis. A human engineer sees the crash-looping pod, pulls the logs and memory dumps, and identifies the root cause in the application code. The orchestrator’s job is to maintain service availability while the human performs the actual fix. It’s a damage control mechanism, not a solution.
Designing for this reality means building observability *into* the automated response. When a pod is restarted for a liveness failure, the automation should also trigger a process to snapshot the logs, capture a core dump, and create a ticket with all that diagnostic information attached. It should prepare the patient for the doctor. It should not pretend to be the doctor itself.
Design for Intervention, Not Replacement
The most mature automation systems are not the ones that run silently in the dark. They are the ones designed with the human operator in mind. The goal is not to eliminate human touch, but to make that touch as precise and effective as possible. This is a fundamental shift in design philosophy, moving from black-box automation to glass-box systems built for partnership.
This approach requires several key principles:
- Clear State Reporting: The automation must be able to report what it is doing, what it has done, and why. If a script is modifying firewall rules, it should log which rule it is changing, the ticket number that authorized the change, and the user who triggered the job. No magic.
- Manual Overrides: Every powerful automation needs an equally powerful “stop” button. When a deployment script goes haywire, you need a way to kill it instantly without having to SSH into a box and find the process ID. This is a non-negotiable safety feature.
- Idempotency: Scripts should be runnable multiple times without changing the result beyond the initial application. This allows an operator to safely re-run a failed job after fixing an external issue, without worrying about creating duplicate resources or corrupting state.
- Graceful Failure Modes: When automation hits an unexpected state, it should fail into a safe, predictable condition. It should revert changes if possible, halt execution, and clearly signal that it requires human help. The worst thing it can do is continue executing with bad data.
This is how you build trust in an automated system. Engineers will only use tools that they understand and can control. A system that is opaque and uncontrollable will be bypassed in favor of manual processes, defeating the entire purpose of the investment.
The real value of a senior engineer is not in writing one more script. It is in designing these complex, interwoven systems. Our job is to handle the exceptions, to apply judgment, and to provide the strategic oversight that no algorithm can replicate. Automation handles the high-volume, low-complexity tasks. The human handles the low-volume, high-complexity problems where experience and intuition are the only tools that work.