
Resistance to automation is never about the technology. It’s a calculated response rooted in the memory of failed projects. Teams don’t fear scripts; they fear half-baked solutions pushed by architects who haven’t dealt with a production outage in a decade. They remember the last “efficiency tool” that doubled their workload by forcing them to debug its opaque failures at 3 AM. The skepticism is earned.
The typical playbook involves a top-down mandate, a six-figure software purchase, and a promise to “transform the workflow.” This approach is dead on arrival. It ignores the institutional scar tissue from past initiatives. To succeed, you have to gut that entire methodology. The fix isn’t a better tool. It’s a better strategy, one that treats trust as the primary resource to manage.
The Diagnosis: Why The Pushback is Logical
Before you write a single line of code, you must diagnose the specific strain of skepticism you’re facing. It’s rarely a monolithic fear of job loss. It’s a collection of valid, experience-based objections from different roles inside the engineering organization. Understanding these personas is critical.
The Senior Engineer Who’s Seen It All
This individual has survived at least three major “digital transformations.” They know the pattern: a massive initial investment, a chaotic implementation that breaks established processes, followed by a quiet abandonment a year later when the budget dries up. Their resistance is a form of self-preservation. They’ve learned that keeping their head down and sticking to their proven, manual processes is the safest path to keeping the systems running.
Their default position is that your new automation is just another flavor of technical debt they’ll eventually have to pay off.
The QA Analyst with a Meticulous System
Quality assurance is a discipline of process and precision. The QA team has developed a battery of manual tests, edge case explorations, and regression checks that they trust. To them, automation isn’t a helper; it’s a brute-force instrument that checks for the obvious but misses the nuance. They’ve seen automated test suites that are perpetually broken, or worse, give false positives that mask real bugs.
They don’t trust the machine to have the same investigative curiosity they do.
The Operations Engineer in the Trenches
This is the person who gets paged when an automated deployment script fails mid-run and leaves a production environment in a broken, indeterminate state. Their world is one of runbooks, rollback procedures, and careful, stateful changes. A black-box automation tool that performs fifty actions behind a single button is their worst nightmare. When it fails, they have no visibility and no control, forcing them to perform digital archaeology to figure out what went wrong.
They see your automation as a landmine in their production environment.
The Initial Breach: Target the Toil, Not the Glory
The single biggest strategic error is attempting to automate a complex, high-visibility process first. It’s a vanity project. The allure of claiming a massive ROI by automating the core CI/CD pipeline is strong, but the risk of catastrophic, public failure is too high. A single misstep here poisons the well for any future automation efforts. The correct approach is to go for the unglamorous, mind-numbing work that everyone hates.
Your first target should be a task that meets these criteria:
- Repetitive: It’s performed daily or weekly without variation.
- Time-Consuming: It takes a human 30-60 minutes of focused, manual effort.
- Low-Risk: A failure in the automated process is an inconvenience, not a production-down catastrophe. The manual process can still be used as a fallback.
- Universally Disliked: No one is passionate about this task. Its removal would be met with relief, not suspicion.
Good candidates include generating weekly performance reports from CSV exports, sanitizing logs for analysis, or provisioning a standardized developer environment. These tasks are pure toil. Automating them doesn’t threaten anyone’s job; it gives them back an hour of their day. It’s a small, undeniable victory.
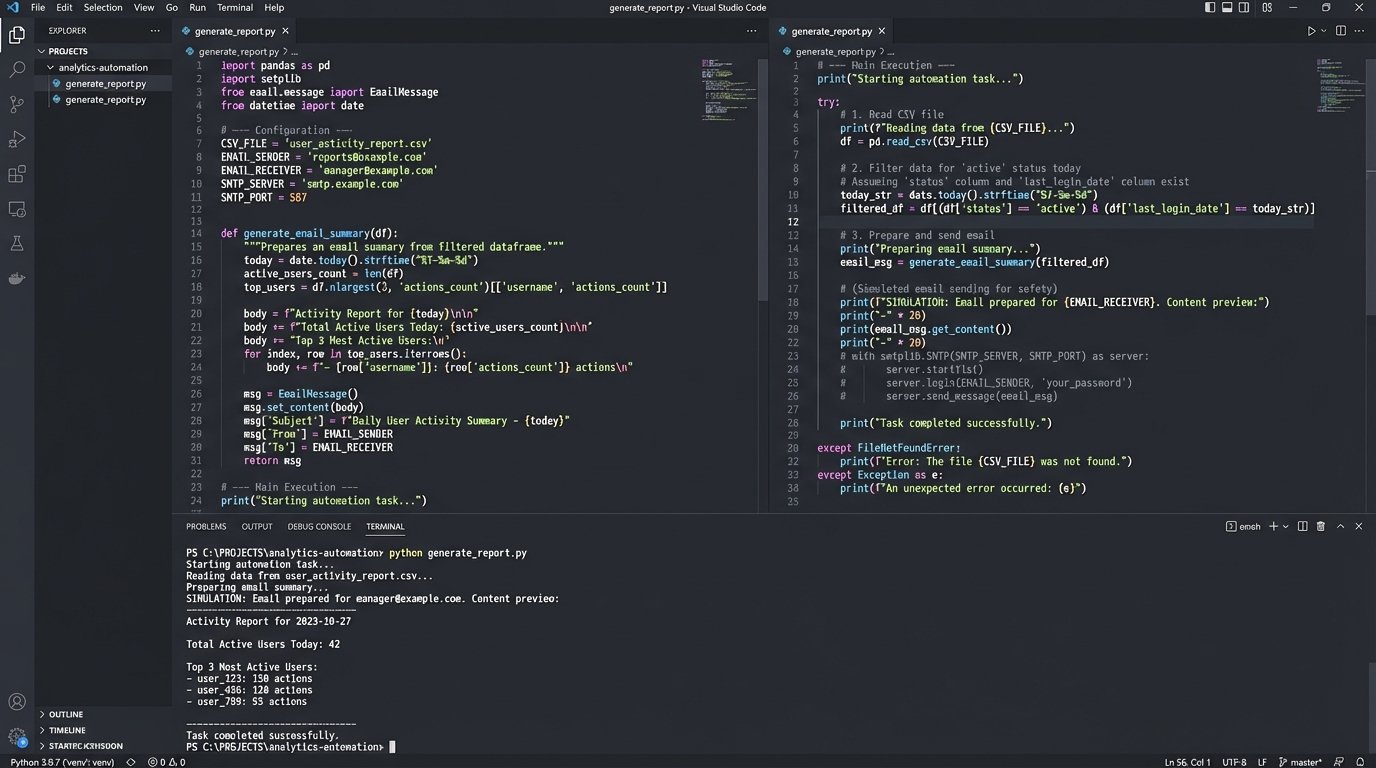
Imagine a manual process where an engineer has to download a daily user activity report, load it into a spreadsheet, filter for specific event types, and email a summary. This is a perfect target. A simple Python script using `pandas` can ingest the CSV, perform the filtering and aggregation, and use `smtplib` to dispatch the email summary. The entire operation is self-contained and easy to logic-check.
The trade-off here is political capital. This kind of small-ball automation doesn’t impress executives. But it’s not for them. It’s a targeted strike to win over the engineers on the ground.
Architecture of Trust: Build Augments, Not Replacements
Once you have a small win, the impulse is to get more ambitious. This is where you must exercise restraint. The next step is not to remove the human, but to build tools that make the human more effective. You must design for “Human-in-the-Loop” workflows. The automation performs the grunt work, but a human makes the critical decision.
Consider a database schema migration. A fully automated script that connects to the production database and applies a schema change is terrifying to an operations team. A better architecture breaks the process into distinct phases:
- The Script: An automation script connects to a staging database, applies the migration, and runs a series of validation checks to confirm success.
- The Output: The script generates a full execution plan and a clear “diff” of the proposed changes for the production environment. It saves this as a reviewable artifact.
- The Gate: The script then pauses and prompts the on-call engineer for explicit approval. It presents the diff and waits for a manual `y/n` input before proceeding.
This architecture transforms the automation from an autonomous agent into a highly capable assistant. It handles the tedious setup and validation but leaves the final, high-consequence decision to a trusted operator. It gives them control and visibility, which are the cornerstones of trust. This approach feels less like shoving a firehose through a needle and more like giving the operator precise control over the valve.
You aren’t taking away their keyboard; you’re just making the commands more powerful.
Exposing the Guts: Radical Transparency is Non-Negotiable
The fastest way to destroy trust is with a black box. An automation that fails without a clear error message or traceable log is worse than no automation at all. It creates more work than it saves. Every piece of automation you build must be designed with the assumption that it will fail, and it must provide the tools for a junior engineer to diagnose that failure quickly.
This means logging is not an afterthought. It’s a primary feature. Use structured logging from the beginning. Every log entry should be a JSON object, not a simple string. This allows for trivial ingestion and filtering in log management systems like Splunk or an ELK stack.
Example: Structured Logging in Python
Instead of `print(“Deployment failed!”)`, you need to provide context that is machine-parsable. The goal is to allow an engineer to query for all failed deployments for a specific service without resorting to `grep`.
import logging
import json
import sys
# Basic configuration for JSON-formatted logs to stdout
handler = logging.StreamHandler(sys.stdout)
formatter = logging.Formatter('{"timestamp": "%(asctime)s", "level": "%(levelname)s", "module": "%(name)s", "message": "%(message)s"}')
handler.setFormatter(formatter)
logger = logging.getLogger('release_automation')
logger.addHandler(handler)
logger.setLevel(logging.INFO)
# Prevent logs from propagating to the root logger
logger.propagate = False
def push_to_registry(image_name, image_tag):
log_context = {'image_name': image_name, 'tag': image_tag}
logger.info(f"Starting image push.", extra=log_context)
# Simulate a push operation that fails
push_successful = False # In reality, this would be the result of a subprocess call
if push_successful:
logger.info("Image push successful.", extra=log_context)
return True
else:
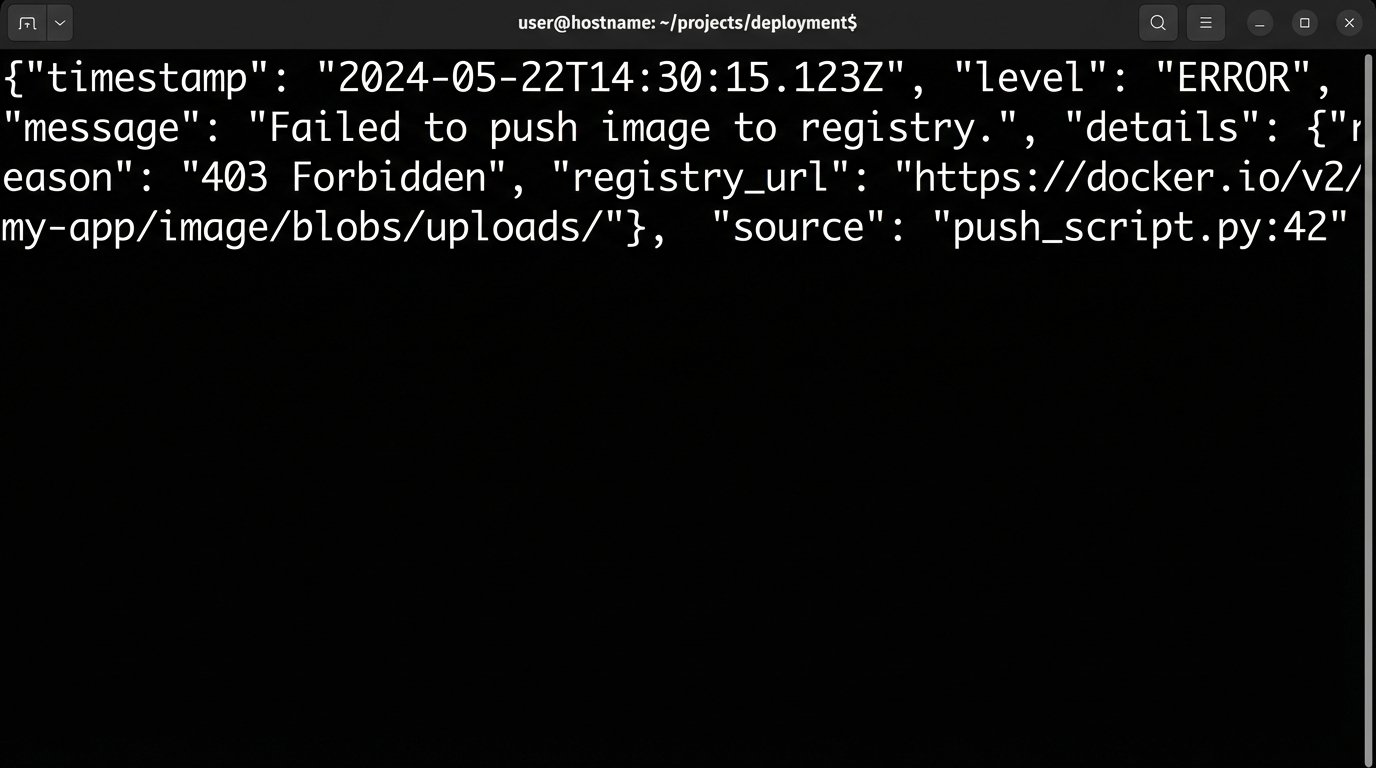
# The 'extra' dictionary injects structured data into the log record
error_details = {"reason": "403 Forbidden", "registry_url": "registry.corp.internal"}
log_context.update(error_details)
logger.error("Failed to push image to registry.", extra=log_context)
return False
# Execution
push_to_registry("auth-service", "v1.2.3")
This simple script, when it fails, produces a clean, queryable JSON line. The person debugging it immediately knows the what, why, and where without having to guess. This level of transparency is expensive. It takes more time to write code that explains itself this well. But it is the only way to convince a skeptical team that your tool is an asset, not a liability.
Weaponizing Data: Create the Feedback Loop
To convert the final holdouts, you need to prove the value of your automation with objective data. This requires instrumenting every script to report its own metrics. Your automation should not just run; it should report back on its own performance. Treat every automated job as if it were a production microservice.
At a minimum, for every execution, you should capture:
- Start and End Timestamps: To calculate duration.
- Exit Status: A binary success or failure.
- Execution Host: To identify environmental issues.
- Input Parameters: What version was deployed? What report was generated?
These metrics should be pushed to a time-series database like Prometheus. From there, you can build a simple Grafana dashboard. This dashboard is your most powerful political tool. It visualizes the work being done by the automation. It shows trends over time: success rates improving, execution times decreasing. You can put a number on the hours saved.
Making this dashboard public and placing it on a monitor in the team’s area changes the conversation. The automation is no longer an abstract concept. It’s a visible, quantifiable part of the team’s workflow. It also creates a feedback loop. When the team sees a spike in failures on the dashboard, they become proactive stakeholders in fixing the problem. They start to own it.
This creates overhead. You have to maintain the dashboard and the metrics pipeline. But this is the cost of converting skeptics into advocates. They stop seeing automation as something being done *to* them and start seeing it as a system they help manage.
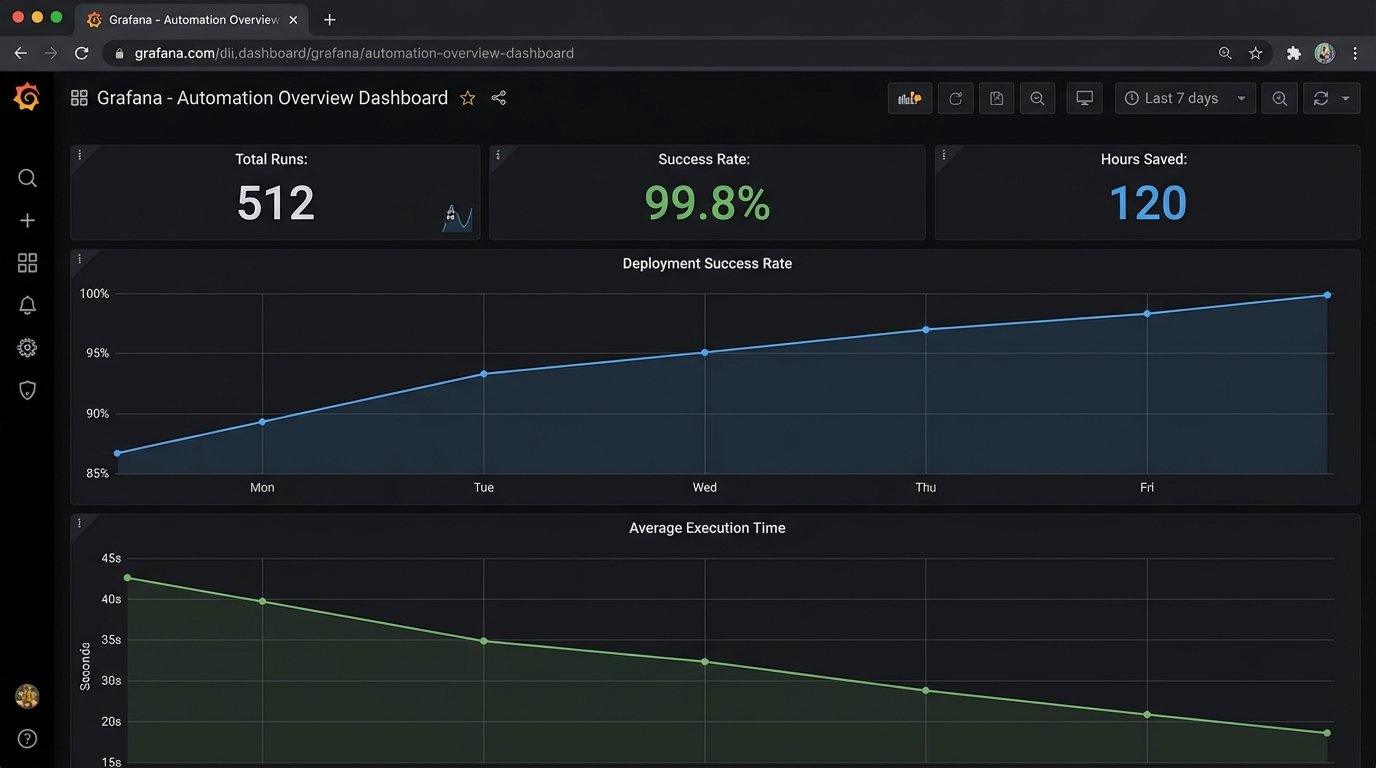
The goal is to reach a tipping point where the manual process becomes unthinkable. When a team member can point to a dashboard and say, “The deployment automation has run 500 times this month with a 99.8% success rate, saving us roughly 120 hours,” the argument is over. The data wins.
The entire strategy hinges on a deliberate, methodical escalation of trust. You start by solving a minor annoyance. You build on that by creating tools that augment their control, not remove it. You solidify it by making your tools transparent and debuggable. You finalize it by proving its value with undeniable data. Resistance crumbles not because of a superior argument, but because of a superior, observable reality you’ve helped to build.