
Ignoring the Data Integrity Contract
The marketing deck promises a “unified data platform.” The reality is a chaotic mess of conflicting data schemas from a dozen different vendors. You’re told the new CRM will seamlessly integrate with your MLS feed, but no one mentions the MLS data is a minefield of inconsistent capitalizations, null values represented as empty strings, and addresses that fail basic geocoding validation. The first mistake is believing the PowerPoint slides.
Your job is to enforce a data integrity contract before a single line of integration code is written. This means forcing a discussion on data normalization at the ingestion point, not later in the pipeline where it becomes exponentially more expensive to fix. If one system uses “St.” and another uses “Street,” you decide on a standard and reject or transform anything that deviates. This is non-negotiable.
The Ingestion Gateway Pattern
Build a single service that acts as a gatekeeper for all incoming data. This service does one job: it validates, cleans, and standardizes data against a rigid schema you define. Anything that fails validation is either rejected with a detailed error log or shunted to a dead-letter queue for manual inspection. Trying to shove this logic into every downstream application is how you end up with three different “clean” versions of the same address.
This approach forces discipline on the entire system. It also means that when a data source inevitably changes its format without warning, you have only one service to update, not five.
Trusting API Documentation Blindly
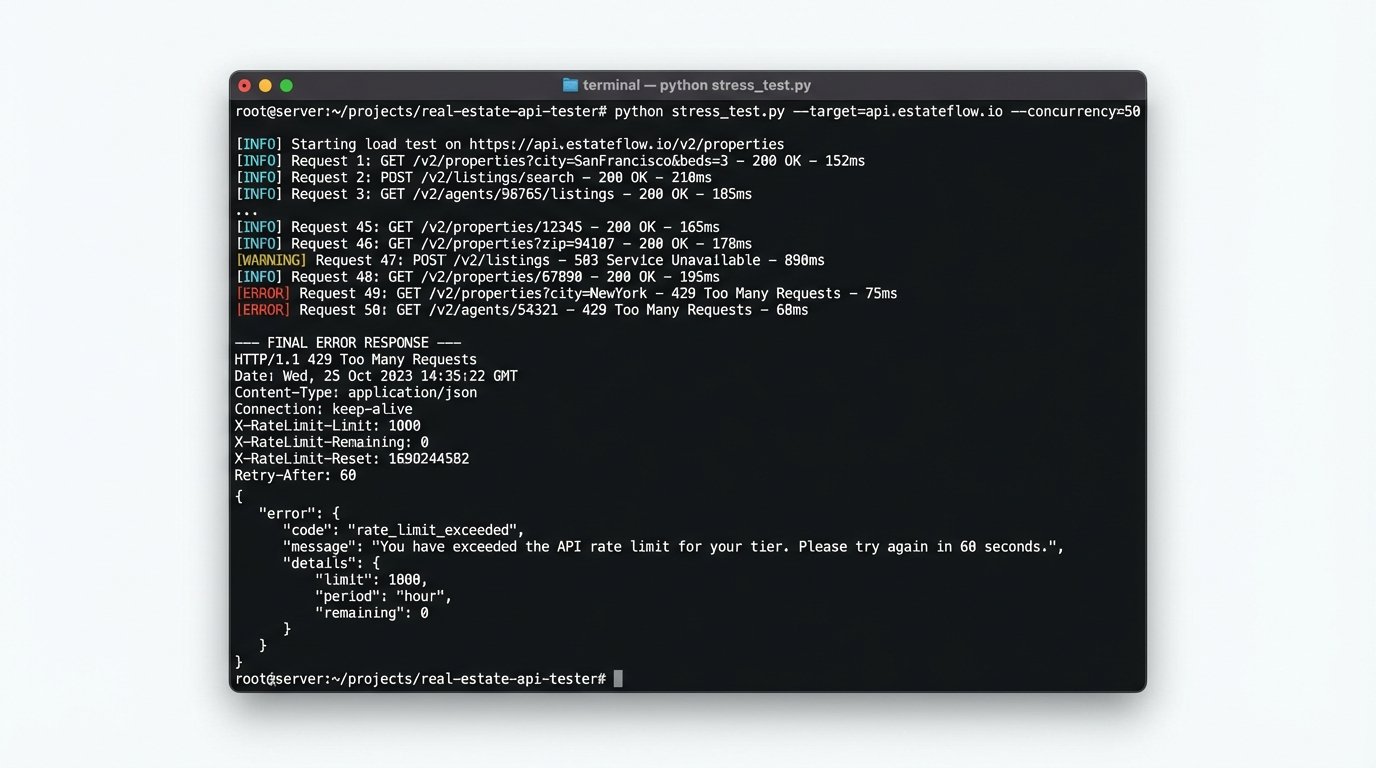
API documentation is often a work of fiction. It describes a perfect world where endpoints respond instantly, rate limits are generous, and data formats never change. In production, you’ll discover undocumented rate limits that trigger after 100 requests, critical data fields that return `null` despite being marked as required, and error messages that are completely cryptic. Assuming the documentation is accurate is a rookie move.
Your first step with any new API is to build a small harness to hammer the endpoints. Stress-test them. Send malformed requests. Exceed the documented rate limits. See how the system actually breaks, not how the PDF says it should break. Log every response header and body, because the real limits and behaviors are often hidden there.
Defensive Coding Against Unreliable Payloads
Never directly access nested keys in an API response without logic-checking each level. A single missing key in a production payload can crash a whole process. Instead, use a utility function that safely traverses the object structure and returns a default value if any part of the path is missing. This prevents your application from throwing a `TypeError` at 3 AM because a vendor decided to rename a field from `agent_id` to `agentId`.
Here is a basic Python example. It’s simple, but it saves hours of debugging brittle code.
def get_nested_value(data_dict, keys, default=None):
"""
Safely retrieve a nested value from a dictionary.
Example: get_nested_value(response, ['property', 'details', 'bedrooms'])
"""
for key in keys:
if not isinstance(data_dict, dict) or key not in data_dict:
return default
data_dict = data_dict[key]
return data_dict
# Usage
api_response = {"property": {"details": {"sqft": 2100}}}
bedrooms = get_nested_value(api_response, ['property', 'details', 'bedrooms'], default=0)
# bedrooms will be 0 instead of causing a KeyError
This isn’t complex, it’s just necessary discipline.
Underestimating Latency Chains
A user clicks “Save” on a property listing. That single action might trigger a cascade of API calls: one to the CRM, one to the marketing automation platform, another to a data warehouse, and a final one to the MLS. Each call has its own latency. While each individual call might only take 300ms, chained together synchronously they create a terrible user experience. The user sees a spinning wheel for three seconds and assumes the application is broken.
Mapping out these service dependencies is critical. You need to distinguish between operations that must be synchronous and those that can be handled asynchronously. Updating the primary database record is synchronous. Sending an email notification or updating a third-party analytics tool is not. Shoving everything into a single, blocking request thread is an architecture designed for failure.
This is where you stop thinking in terms of simple request-response cycles and start architecting with message queues. Trying to make a dozen disparate APIs respond in real-time is like shoving a firehose through a needle. It’s a fundamental misunderstanding of distributed systems.
Isolate Processes with Queues
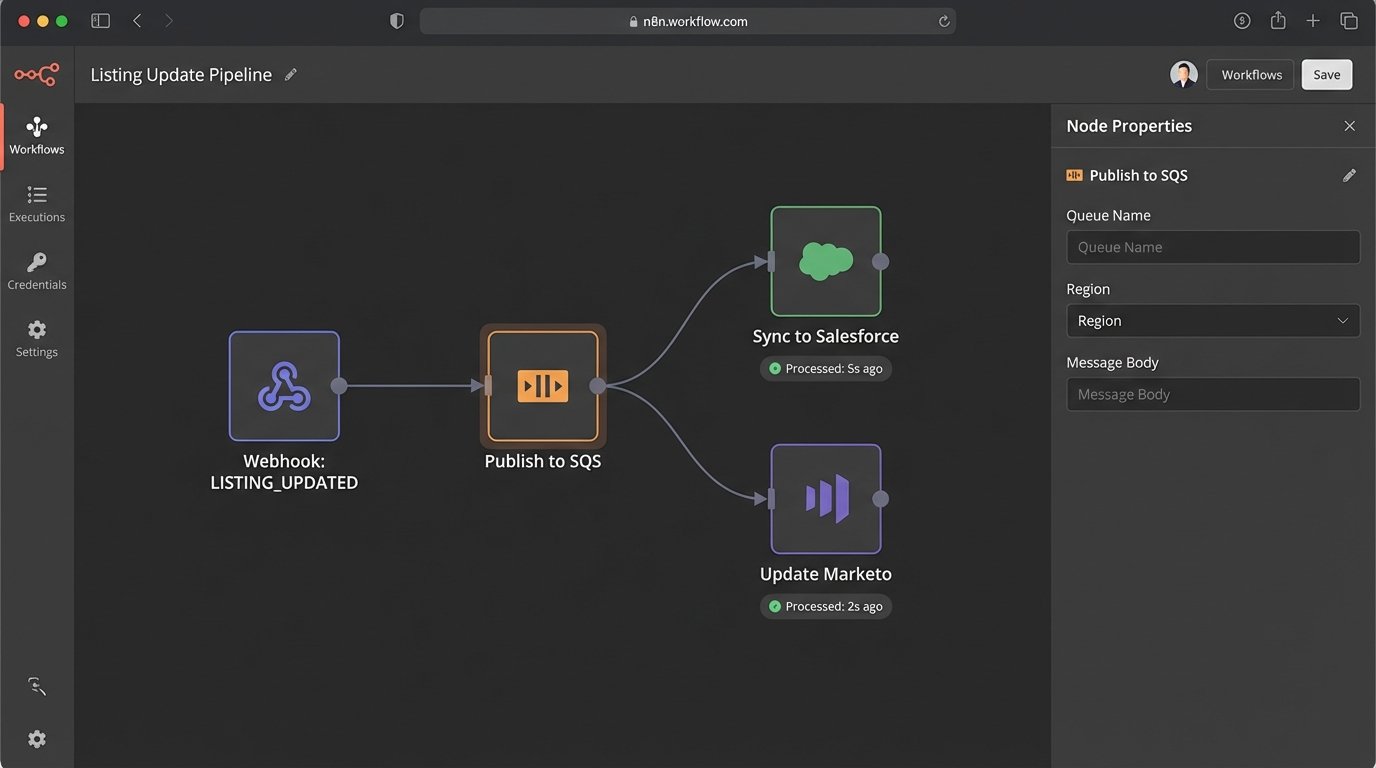
When that “Save” button is clicked, the primary application should do only the bare minimum: validate the data and write it to your local database. Then, it should push a message onto a queue like RabbitMQ or AWS SQS. The message contains the listing ID and the event type, like `LISTING_UPDATED`.
Separate, independent worker processes listen to this queue. One worker is responsible for syncing the data to the CRM. Another handles the marketing platform. If the CRM’s API is down, it doesn’t block the marketing update. The CRM worker can retry its job with an exponential backoff policy without affecting any other part of the system. This decouples your services and makes the entire architecture more resilient.
Architecting for a Single Vendor
Committing your entire architecture to a single proprietary platform is a massive strategic risk. That “all-in-one” real estate platform might look good now, but when they triple their prices next year or get acquired by a competitor who shuts down their API, your entire system is held hostage. You must build abstraction layers around third-party dependencies from day one.
This means your core application code should not directly call the Salesforce API or the Zillow API. It should call your own internal `CRMService` or `ListingService`. Inside that service is where the specific logic for talking to the third-party vendor lives. This creates a clean boundary, a firewall between your business logic and the vendor’s implementation details.
When the time comes to switch from one CRM to another, you don’t gut your entire application. You write a new adapter that implements your internal `CRMService` interface and change a single line in a configuration file. The rest of your code remains untouched and blissfully unaware of the change.
Neglecting Observability
A common failure is treating logging as an afterthought. Unstructured, plain-text logs are useless when you’re trying to debug a distributed system. You need structured logs, typically in JSON format, that capture context for every event: a request ID, user ID, session ID, and the specific application component. Without a way to trace a single user’s action across five different microservices, you are flying blind.
Your logs should tell a story. When an error occurs, the log entry must contain the full request body that caused the error, the stack trace, and the service’s state at the time of failure. Sending a vague “Error updating record” message to a log file is pointless. Your goal is to have enough information in a single log entry to reproduce the bug without having to guess.
Invest in Centralized Logging and Metrics
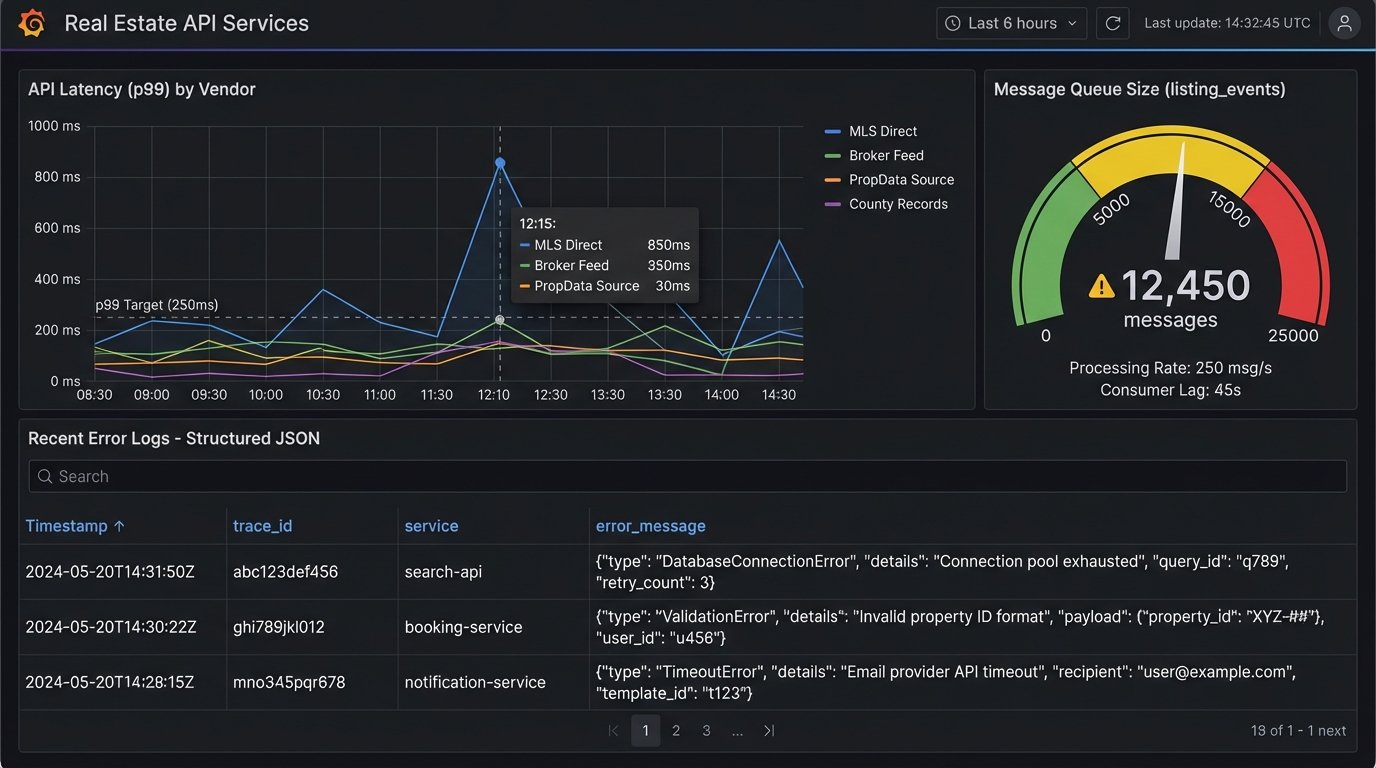
All services should push their structured logs to a centralized platform like Elasticsearch, Datadog, or Splunk. This allows you to build dashboards that correlate events across your entire stack. You can track the latency of each step in your asynchronous workflows and set up alerts for when error rates exceed a certain threshold. This isn’t a luxury, it’s a requirement for maintaining a production system.
Metrics are just as important. Instrument your code to track key business operations: number of listings ingested per hour, average API response time from each vendor, and the size of your message queues. When a queue starts backing up, it’s an early warning sign that a downstream service is failing. Waiting for customers to report the problem means you’ve already failed.
The core issue is never the technology itself. It’s the failure to anticipate the friction between clean system diagrams and messy production reality. Every new tool introduces new potential points of failure. Your job is to find them before your users do.