
The Lie of “Continuous Learning” and the Reality of Staying Relevant
Forget the term “continuous learning.” It’s a sanitized phrase from HR to make mandatory training sound inspiring. For us, it’s not about learning. It’s about not becoming obsolete. The automation stack you mastered two years ago is already a legacy system. The libraries you depend on have been forked, rewritten, or abandoned. This isn’t a gentle process of growth. It is a constant, grinding effort to keep your skills from decaying into irrelevance.
Success in this field isn’t measured by the number of courses you complete. It’s measured by your ability to parachute into a failing CI/CD pipeline at 2 AM, diagnose a race condition in a parallel test suite, and get the release unblocked. Everything else is academic. The real learning happens under pressure, not in a web browser tab with a video playing at 2x speed. The landscape shifts under our feet daily, and the only reliable practice is to treat your own knowledge as a perishable good with a very short shelf life.
Ditch the Certifications, Build a Personal Lab
Why Certs Are Mostly Useless Paper
Certifications are a wallet-drainer designed to test your short-term memory, not your problem-solving capability. They teach the “happy path” of a tool, a path that does not exist outside of the exam environment. No certification exam will ever ask you to debug a test that fails only on Wednesdays due to a latent bug in a third-party API’s caching logic. They provide a false sense of accomplishment and are frequently years behind the current version of the tool they claim to represent.
Hiring managers who fixate on them are broadcasting their own technical ignorance.
The Anatomy of a Functional Home Lab
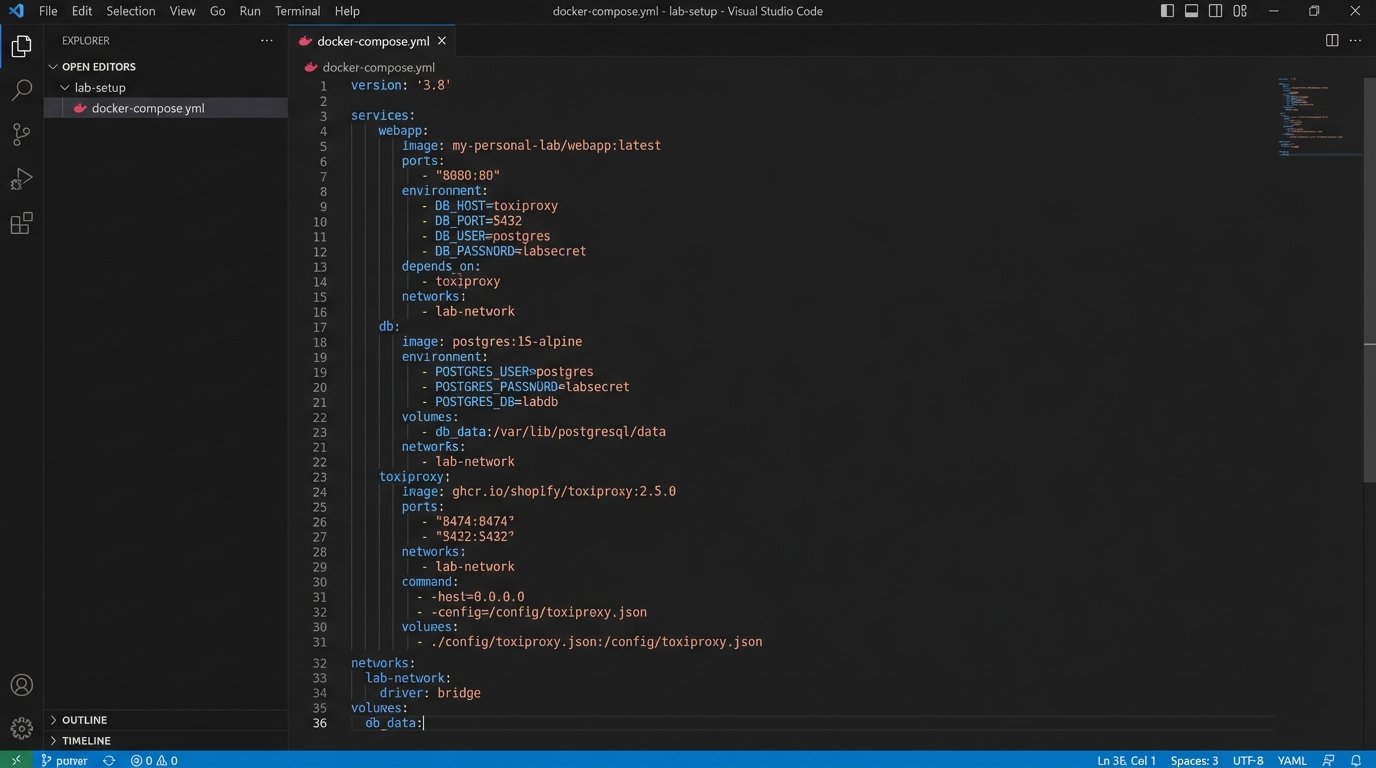
Your learning needs a sandbox where you can detonate things without consequence. This isn’t about building a massive server rack in your basement. It’s about having a reproducible, disposable environment to simulate real-world chaos. Start with Docker and Docker Compose. They are the bedrock. From there, get a minimal Kubernetes distribution like Minikube or k3s running. This forces you to understand networking, service discovery, and configuration management at a fundamental level.
The goal is not to build a perfect, clean system. The goal is to build something you can intentionally break. Set up a simple application, write automation against it, and then start injecting failures. Use a tool like Toxiproxy to simulate network latency and connection drops. Manually corrupt a database record. Configure your application with insufficient memory. This is how you learn to write automation that is resilient to the entropy of production environments.
Master the Primitives, Not Just the Frameworks
The HTTP Protocol Is Your Foundation
High-level automation frameworks like Playwright or Cypress are powerful, but their abstractions are a trap. They hide the raw HTTP requests and responses that are the lifeblood of every web application. When a test fails with a cryptic framework-specific error, your first instinct should be to bypass the framework entirely and diagnose the problem at the protocol level. Can you replicate the failure with a simple `curl` command? Are the correct headers being sent? Is the server returning a non-standard status code that the framework doesn’t know how to handle?
Debugging a framework without knowing the underlying protocol is like trying to fix a corrupt database file with a plain text editor. You can see the raw data, but you have no concept of the structure or the rules that govern it, leaving you to guess randomly. Keep a file of useful `curl` commands handy to check health endpoints, post form data, and inspect authentication headers directly. This single skill will save you countless hours of debugging.
# Check headers and status code from a protected endpoint
curl -v -H "Authorization: Bearer your_jwt_token" https://api.example.com/v1/user/profile
# Submit a form and see the raw response
curl -X POST -d "username=test&password=123" https://app.example.com/login
Learn a Systems Language, Even Poorly
Most automation is written in scripting languages like Python or JavaScript. They are excellent for gluing systems together and rapid development. However, they shield you from the machine. To truly understand performance and concurrency, you must get closer to the metal. Pick up a systems language like Go or Rust. You do not need to become an expert developer in it.
The objective is to understand concepts that scripting languages abstract away: static typing, pointers, memory allocation, and green threads versus OS threads. This knowledge pays dividends when you need to diagnose a memory leak in your test runner or understand why your parallel tests are deadlocking. It gives you the ability to read the source code of the tools you rely on and pinpoint the exact line of C++ or Go that is causing your test suite to fall over.
Instrument Everything, Trust Nothing
The Fallacy of the Green Checkmark
A green checkmark in your CI/CD pipeline is one of the most misleading indicators in our industry. It signals a binary outcome: the test script executed without throwing a terminal exception. It says nothing about the quality of that execution. Was the test slow? Did it consume an absurd amount of memory? Did it pass because a critical assertion was accidentally commented out? The pass/fail status is the lowest form of signal you can get from your automation.
We must move beyond this binary view and start treating our automation runs as a source of rich performance and behavioral data.
Practical Observability for Automation
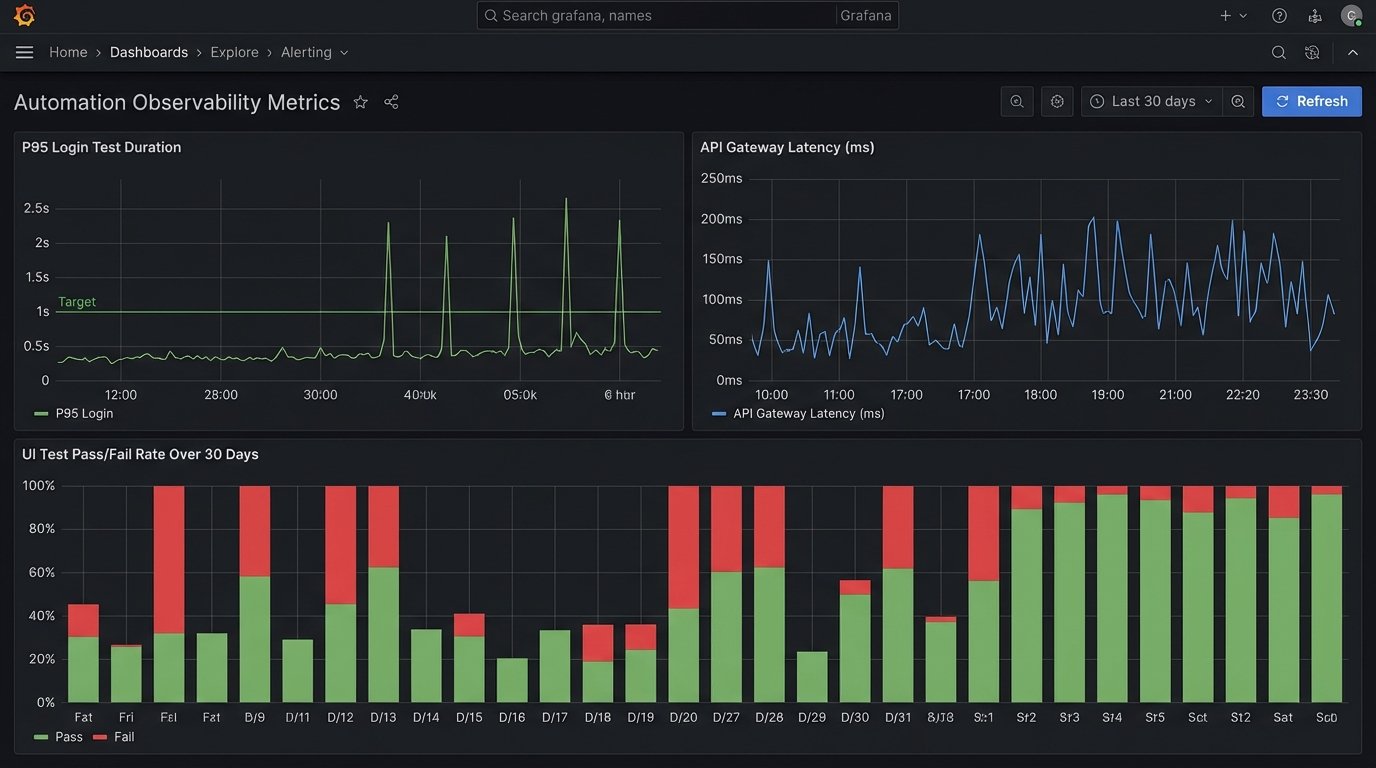
Your automation suite should be a first-class citizen in your organization’s observability stack. This means your test results should not just live and die in a Jenkins console log. You need to push metrics to a time-series database like Prometheus and logs to a centralized system like Loki or the ELK stack. At the start of a test, generate a unique correlation ID. Inject this ID into every log message and every metric emitted during that test run.
Now you can build Grafana dashboards that show you trends. How has the P95 duration of the login test changed over the last 30 days? Is there a correlation between slow API responses from the staging environment and an increase in flaky UI tests? This transforms automation from a simple validation gate into a proactive monitoring tool that can detect performance regressions long before they hit production.
Treat Your Automation Code Like Production Code
The “Test” Directory Is a Code Ghetto
There is a pervasive and damaging mindset that test code doesn’t have to adhere to the same quality standards as application code. This leads to automation suites that are a tangled mess of duplicated code, hardcoded values, and nonexistent error handling. The result is a brittle, unmaintainable liability that erodes trust in the entire testing process. This has to stop. Automation code is production code. It runs on every commit and directly controls the speed and safety of software delivery.
Treat it with the same respect. The “it’s just a test” excuse is the mark of an amateur.
Applying Production Principles
Your test code repository needs a `README.md` that explains how to set up and run the tests. It needs a strict linter configuration that is enforced by a pre-commit hook. Every single change, no matter how small, must go through a pull request and be reviewed by at least one other engineer. You should be using design patterns to manage complexity. The Page Object Model is a start, but you should also be thinking about dependency injection to manage service clients and using a factory pattern to generate test data.
Your code should be organized, readable, and structured for maintenance. If a new engineer cannot get the test suite running and understand the purpose of a test file within their first day, your architecture has failed. Period.
The Social Engineering of Continuous Learning
Read the Damn Pull Requests
Your most valuable source of information is not a blog post or a conference talk. It is the stream of pull requests from the development teams you work with. Set up notifications for the repositories of the services your automation targets. Spend 30 minutes every day reading the code that is about to be merged. You will see API contracts changing before the documentation is updated. You will spot new frontend components that need test coverage. You will understand the “why” behind a change, not just the “what.”
This is the highest-fidelity, lowest-latency source of information you have. Neglecting it is professional malpractice.
Find the Signal in the Noise
The internet is saturated with low-quality technical content designed to sell you something. Trying to learn from marketing blogs and vendor whitepapers is like trying to hydrate by drinking saltwater. The volume is there, but the content is toxic to your understanding. You must be ruthless about curating your information sources. Unsubscribe from every marketing email list. Instead, use an RSS reader to follow the personal blogs of engineers who build the tools you use.
Follow the bug trackers and official GitHub issue lists for your core frameworks. The discussions in those threads contain more practical knowledge than a dozen certified courses. Focus on depth over breadth. Becoming a true expert on your core stack is far more valuable than having a superficial knowledge of ten different trendy tools.
Final Check: The Anti-Pattern Checklist
Learning is as much about what you stop doing as what you start doing. If any of these sound familiar, fix them.
- Stop chasing the new shiny framework. Master the one you have. Stability and deep knowledge beat novelty.
- Stop accepting flaky tests. A flaky test is a failing test. Isolate it, fix the root cause, or delete it. There is no middle ground.
- Stop writing automation that only runs on your machine. If it’s not containerized and running in a CI pipeline, it doesn’t exist.
- Stop measuring success by the number of test cases. This is a vanity metric. Measure success by the number of production bugs your automation prevented.
- Stop ignoring test failures. An ignored failing test teaches the entire organization that the automation suite is worthless and can be bypassed.