
The Data Fragmentation Tax in Real Estate
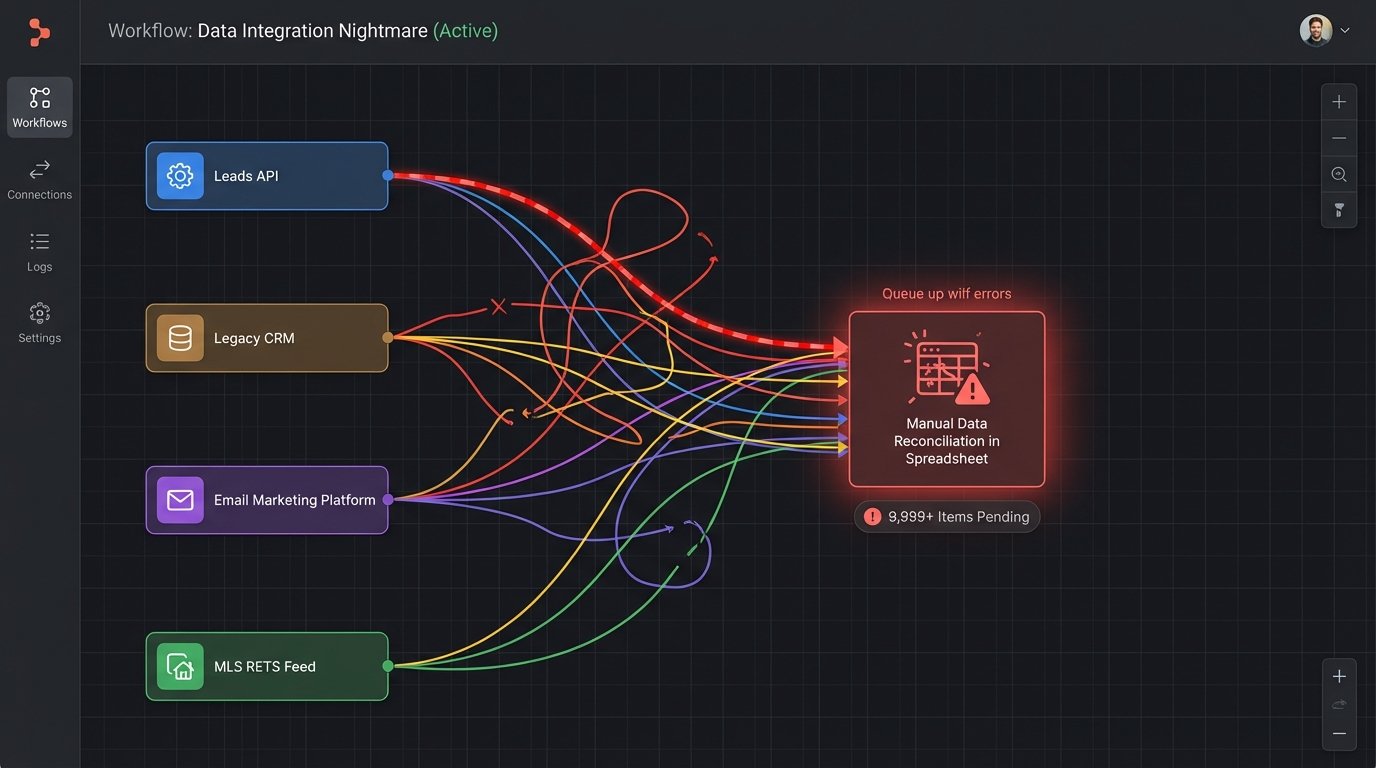
Every mid-sized real estate agency pays a tax. It is not a government levy. It is the operational drag caused by data existing in disconnected silos. An agent lands a new lead from a portal, which dumps the contact into a lead-routing system. The agent then manually copies that data into their primary CRM. When that lead becomes a client, their information is re-keyed into a transaction management platform. The same data gets typed a third time into the marketing automation tool for drip campaigns.
This is not just inefficient. It is a direct source of data rot. A phone number updated in the CRM never makes it to the email platform. A client’s name is misspelled in one system but correct in another. Before we intervened, one agency was bleeding nearly 10 agent-hours per week on data reconciliation alone. They were running a popular but aging CRM, a standalone email marketing service, a separate document management system, and pulling MLS data via a brittle RETS feed that required constant babysitting. The whole setup was a house of cards held together by manual labor and browser tabs.
The core problem was the lack of a single source of truth for a client or a property. Each SaaS tool maintained its own version of reality. Our job was not to find a better tool, but to architect a better system and kill the data fragmentation tax for good.
Evaluating the “All-in-One” Promise
The market is flooded with platforms promising a unified solution for real estate. Most are just repackaged CRMs with a few bolted-on features. Our criteria for selection was ruthlessly simple: a single data object for contacts, properties, and transactions, exposed through a functional REST API. We were not interested in shiny dashboards. We needed to see the underlying data model.
We settled on a platform, let’s call it Prop-Core, not because it was perfect, but because its data architecture was sane. It treated a “deal” as a central object that linked to “contact” and “property” objects. This structure mirrored the real-world workflow, a basic requirement that many other platforms failed. The API documentation was also a factor. It was reasonably up-to-date and included clear examples for standard CRUD operations, a low bar that many vendors still manage to trip over.
The sales pitch for these platforms always glosses over the migration. They show you a CSV import button and act like the problem is solved. The reality is that getting years of disjointed data from four different systems into a single, structured database is the real work. It is where these projects live or die.
The Migration: A Data Funnel, Not a Data Pump
Our first step was a full data audit and export from the legacy systems. We pulled contacts from the old CRM, deal history from the transaction tool, and property data from manual spreadsheets. The result was a mess of conflicting field names, inconsistent date formats, and a comical amount of duplicate entries. Simply pumping this garbage into the new system would have been pointless. We had to build a filter.
We used a Python script with the Pandas library to act as our processing engine. The script’s job was to ingest all the raw CSVs, standardize the column headers, and then apply a series of cleaning and deduplication rules. For example, phone numbers were stripped of all non-numeric characters. Addresses were normalized using a simple validation library to fix common typos in street names. This entire process is like trying to force sludge through a fine-mesh screen. You have to apply pressure and accept that some of it just will not go through.
The most complex part was linking records across the different datasets. We used a multi-pass approach. First, we matched contacts based on a direct email address match. Then, we ran a second pass using a fuzzy logic match on name and phone number to catch near-duplicates. Any records that could not be automatically matched with high confidence were flagged for manual review. This prevented us from creating a bigger mess than the one we started with.
Injecting Data via the API
The platform’s CSV import tool choked on our cleaned dataset. It had an arbitrary row limit and poor error reporting, failing silently on records with special characters. This forced us to bypass it entirely and inject the data directly through the API. This is often the case. The native tools are built for the simplest use case, not for serious migration.
We wrote another script to read our processed data frame and loop through it, making POST requests to the Prop-Core API endpoints for creating contacts, then properties, then transactions. The key was to manage dependencies. You cannot create a transaction without first having the contact and property records in the system and getting their new IDs back.
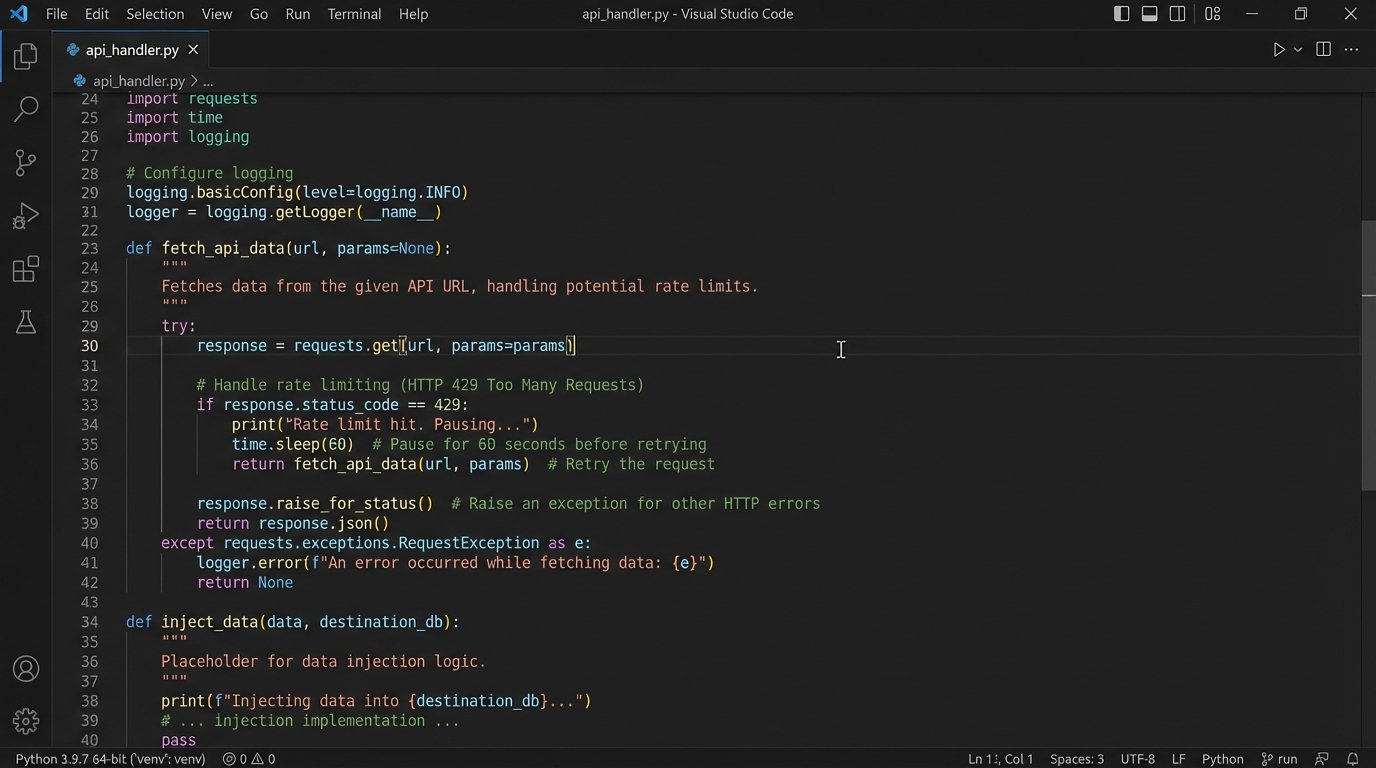
This is where we hit our first real wall: API rate limits. The platform throttled requests to 120 per minute. With over 50,000 records to create, a simple loop would have taken hours and likely triggered a temporary IP ban. We had to logic-check our script to include a sleep timer and rudimentary error handling for 429 “Too Many Requests” responses.
import requests
import json
import time
API_KEY = 'YOUR_API_KEY'
HEADERS = {'Authorization': f'Bearer {API_KEY}', 'Content-Type': 'application/json'}
BASE_URL = 'https://api.prop-core.com/v1/'
def create_contact(contact_data):
"""Posts a single contact to the API, with rate limit handling."""
url = f'{BASE_URL}contacts'
response = requests.post(url, headers=HEADERS, data=json.dumps(contact_data))
if response.status_code == 429:
print("Rate limit hit. Pausing for 60 seconds.")
time.sleep(60)
return create_contact(contact_data) # Retry the request
if response.status_code == 201:
return response.json()['data']['id']
else:
print(f"Failed to create contact {contact_data['email']}. Status: {response.status_code}")
print(f"Error: {response.text}")
return None
# Example Usage with a dataframe 'df_contacts'
# for index, row in df_contacts.iterrows():
# payload = {'name': row['FullName'], 'email': row['EmailAddress'], 'phone': row['PhoneNumber']}
# new_contact_id = create_contact(payload)
# if new_contact_id:
# print(f"Successfully created contact ID: {new_contact_id}")
# # Small delay to be a good API citizen
# time.sleep(0.6)
This script is basic, but it illustrates the core loop: attempt the request, check for the rate limit status code, pause if necessary, and retry. This small piece of defensive programming saved the entire migration from stalling out.
The Results: Quantifiable Change, Not Vague “Efficiency”
Post-migration, the agency operated from a single platform. The immediate effect was the elimination of duplicate data entry. We measured the impact directly by shadowing a few agents before and after the switch.
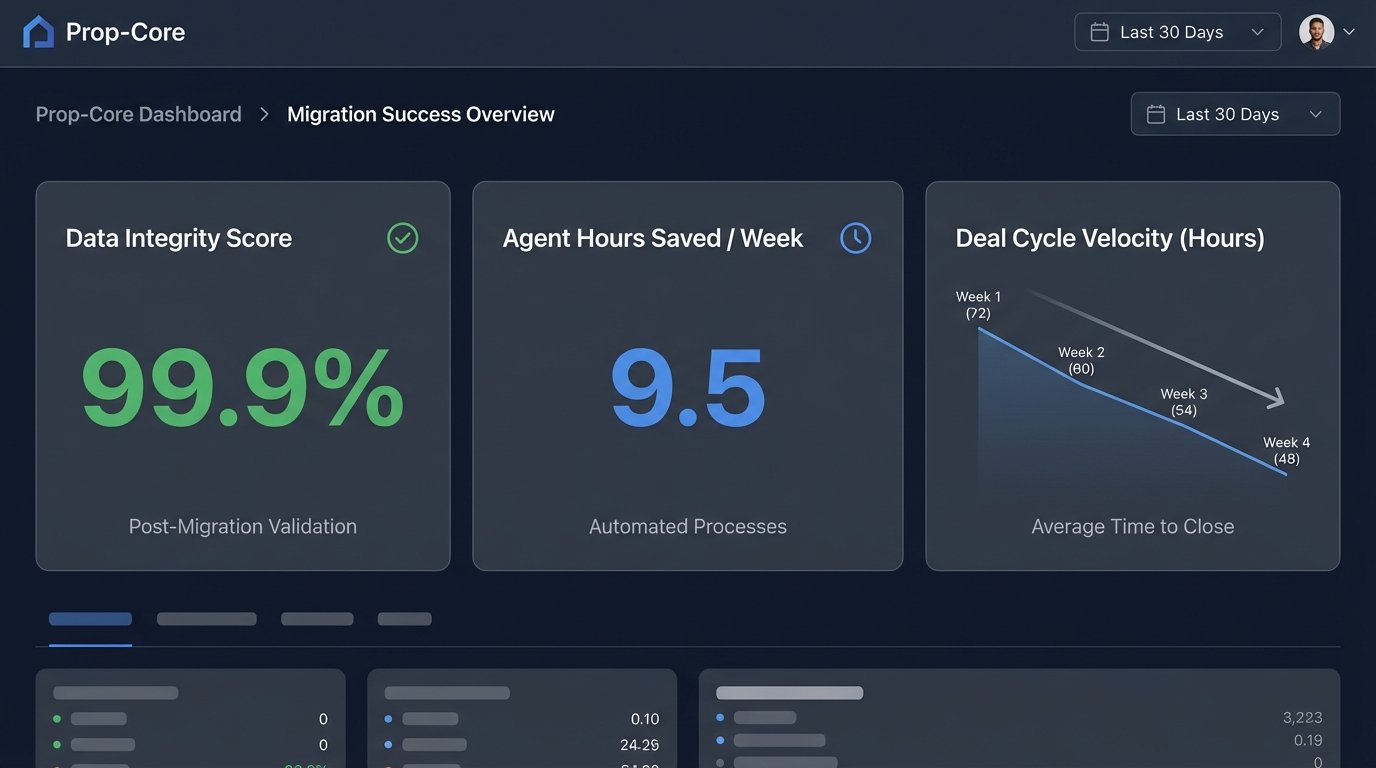
- Reduction in Manual Data Entry: Average time spent on data entry and reconciliation per agent dropped from 5 hours per week to less than 30 minutes. This was the single biggest win, freeing up nearly 10% of an agent’s work week.
- Data Integrity Score: We wrote a script to cross-reference contact details across the old systems and found a data discrepancy rate of 18%. Post-migration, with a single source of truth, that rate is functionally 0%. An updated phone number is now instantly reflected everywhere.
- Deal Cycle Velocity: The time from a lead being qualified to an offer being sent out was reduced by an average of 24 hours. This was a direct result of automating the creation of transaction files and associated documents, which previously required manual setup.
The ROI was not just about time saved. The agency decommissioned three separate SaaS subscriptions, resulting in a direct cost saving of over $12,000 per year. While the new platform was a significant investment, the combined savings in labor and software subscriptions projected a full payback period of 14 months.
Unforeseen Complications and New Problems
The project was not a complete victory without new battle scars. Consolidating everything onto one platform introduces a massive single point of failure. If Prop-Core has an outage, the entire agency is dead in the water. This is a risk that did not exist when work was spread across multiple, independent systems. We are mitigating this with a nightly automated backup script that pulls all key data out of the platform via its API and stores it in a series of flat files on a separate cloud provider. It is a crude insurance policy, but a necessary one.
The other issue is vendor lock-in. Migrating onto this platform was hard. Migrating off it would be even harder. The agency is now dependent on Prop-Core’s feature roadmap, pricing structure, and support quality. This is the fundamental trade-off of the all-in-one approach. You gain massive operational simplicity, but you sacrifice flexibility and control. The agency made this choice with open eyes, but it is a constraint they will have to manage for years.
The final lesson is that no platform is a magic bullet. It is just a tool. The productivity gains did not come from the software itself. They came from the disciplined process of cleaning the underlying data, defining a coherent workflow, and forcing the technology to conform to that workflow, not the other way around. Without that foundational work, they would have just ended up with a more expensive way to manage the same old mess.