
Most AI in real estate is a lie. It is a marketing veneer painted over decade-old statistical models and brittle rules-based systems. The pitch is a self-driving system for property valuation and lead generation. The reality is a collection of high-maintenance APIs that fail silently and produce outputs that require constant human override. We are sold intelligence but delivered regression.
The industry’s obsession with client-facing AI ignores the catastrophic data integrity problems that plague every single real estate operation. Before we can build a thinking machine, we must first build a system that can reliably read a PDF. The real work is not in predicting the future. It is in accurately representing the present.
The Valuation Mirage: Why Predictive Pricing Fails
Automated Valuation Models (AVMs) are the poster child for real estate AI. The concept is simple. Feed a model historical sales data, property characteristics, and location information. The model then spits out a price for any given property. In a stable, homogenous market, this works well enough to be vaguely useful. The problem is that the real estate market is neither stable nor homogenous.
These models are fundamentally brittle. They are typically built on gradient boosting machines or simple neural networks that learn correlations from historical data. The features are predictable: square footage, number of bedrooms, zip code, school district rating, days on market for comparable properties. The model learns that a certain combination of features correlates with a specific price point. It has no understanding of causation.
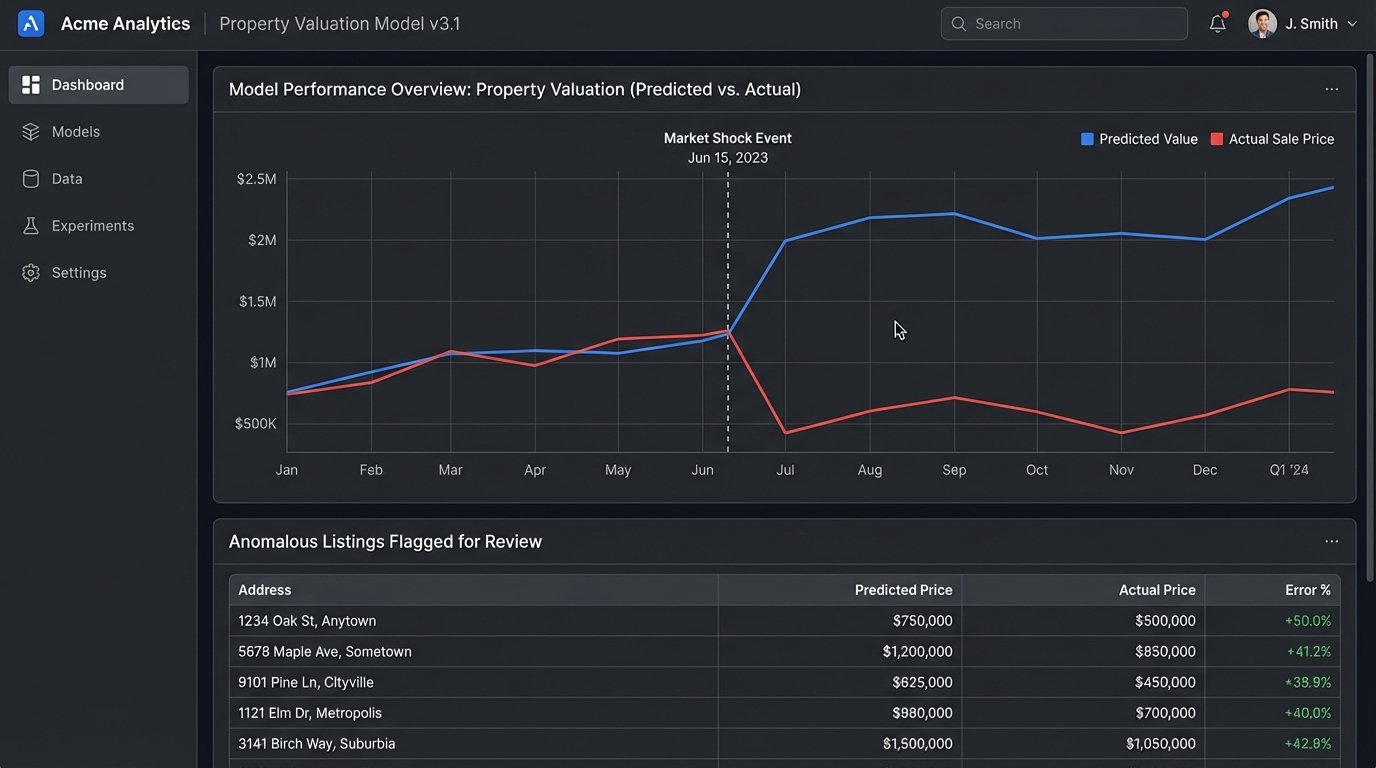
When the Data Lies
A market shock, like a sudden interest rate hike, invalidates the historical data the model was trained on. The correlations it learned are no longer reliable. The AVM continues to project prices based on a reality that no longer exists, leading to wild inaccuracies. It cannot account for black swan events because its entire worldview is confined to its training dataset.
Consider the feature set. A model might see that properties in a specific zip code sell for 15% more. It doesn’t know why. It doesn’t know a new factory just closed, a zoning law changed, or a sinkhole opened up. Human agents know this context. The machine sees only the numbers, and when the context shifts, the machine is flying blind.
This is the core issue. The models are pattern matchers, not economic analysts. They are easily fooled by outlier data, such as a single anomalous sale price that pollutes the data for an entire neighborhood, or by luxury features that are not captured in the standardized data fields of an MLS entry.
Lead Nurturing Chatbots: The Illusion of Conversation
The next great promise is the AI chatbot, designed to engage potential clients 24/7. These systems are pitched as intelligent agents that can qualify leads, answer questions, and schedule showings. In practice, they are glorified interactive FAQs powered by basic Natural Language Processing (NLP) for intent recognition. They are a technical and financial dead end for most serious applications.
The engineering challenge is immense. Real estate conversations are filled with ambiguity, jargon, and high-stakes questions. A potential buyer might ask, “Are there any good schools nearby with a special needs program and is the foundation solid on this property?” A typical chatbot, even one using a large language model (LLM) via an API, will choke on this. It might correctly parse the “good schools” intent but will completely miss the nuance of the foundation question.
The result is a frustrated user and a lost lead. The bot provides a generic answer or, worse, a wrong one. The cost of training and fine-tuning a model to handle the sheer breadth of real estate queries is astronomical. You end up spending a fortune to build a system that is only marginally better than a well-designed web form. It is a wallet-drainer with a questionable return.
The High Cost of Sounding Human
To make these bots even remotely functional, you have two paths: third-party APIs or a custom-built model. The API route, using services from OpenAI or Google, gets you to a prototype fast. But you are now shipping client conversations to a third party, creating data privacy issues. You are also subject to rate limits, per-token costs that can spiral out of control, and model updates that can break your prompt engineering overnight.
Building a custom model gives you control but requires a dedicated team of ML engineers and a massive, meticulously labeled dataset of real estate conversations. This is not a project you hand off to a couple of backend developers. The ongoing maintenance, monitoring for model drift, and periodic retraining make it a permanent line item on the engineering budget. All this to avoid having a human send an email.
The Real Job: AI as a Data-Plumbing Tool
The actual, tangible value of AI in real estate is not on the front end. It is in the backend, doing the thankless work of cleaning up the industry’s notoriously dirty data. This is where machine learning can be force-injected to solve real, costly problems. The work is unglamorous, but the ROI is massive.
Forget predicting markets. Start by correctly identifying the number of bathrooms from five different MLS data feeds that all use a different naming convention. That is a solvable problem that saves thousands of hours of manual data entry and correction.
Automating Document Ingestion
Every real estate transaction generates a mountain of unstructured documents: sales contracts, inspection reports, deeds, loan agreements, and insurance policies. Most of this exists in PDF format, a digital prison for critical information. Manually extracting this data is slow, expensive, and prone to human error.
This is a perfect application for Optical Character Recognition (OCR) combined with Named Entity Recognition (NER). An OCR engine like Tesseract can rip the text from the scanned document. Then, a trained NER model can parse that raw text to identify and extract key entities: buyer name, seller name, property address, sale price, closing date. This is not science fiction. It is a direct application of existing technology to a high-value business problem.
A pipeline can be built to watch an inbox or a cloud storage folder. When a new contract PDF arrives, it is automatically processed. The extracted data is structured into a JSON object and then injected into the main database. This single piece of automation can eliminate entire departments of manual data entry clerks.
{
"document_id": "contract_7592_v3.pdf",
"extracted_entities": [
{
"text": "Johnathan Miller",
"label": "BUYER_NAME",
"confidence": 0.98
},
{
"text": "123 Oak Avenue, Anytown, USA",
"label": "PROPERTY_ADDRESS",
"confidence": 0.99
},
{
"text": "$450,000.00",
"label": "SALE_PRICE",
"confidence": 0.95
}
],
"ingestion_timestamp": "2023-10-27T10:00:00Z"
}
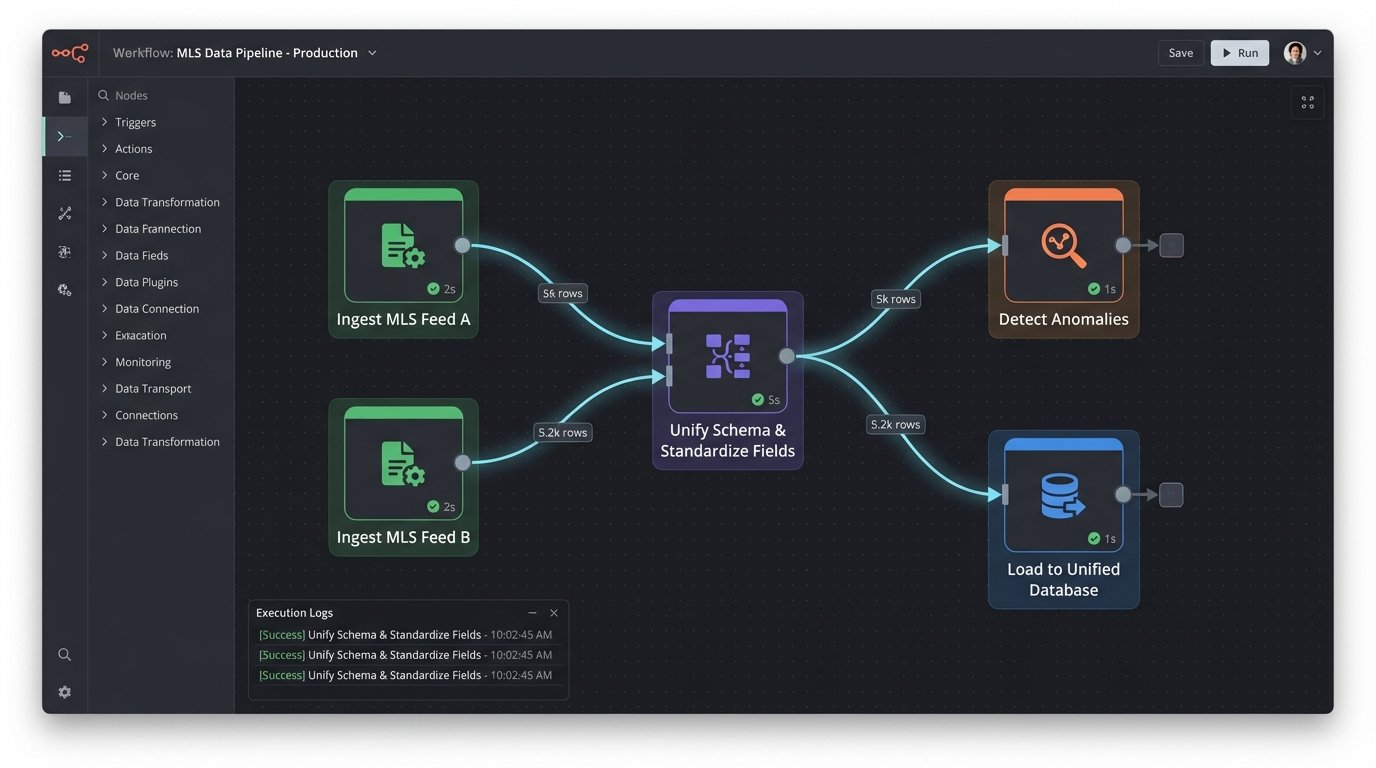
Unifying the Chaos of MLS Data
There is no single source of truth for property listings. There are hundreds of Multiple Listing Services (MLS) across the country, each with its own schema, field names, and data standards. A field named `baths_total` in one feed might be `full_bathrooms` in another. Property type could be an integer ID in one system and a free-text string in another. This makes building any kind of national-level application a nightmare of data mapping and custom logic.
Machine learning models can be used to hammer this data into a single, unified schema. A classification model can look at the property description, photos, and features to standardize the property type, flagging “townhouse” and “twnhs” as the same thing. Anomaly detection models can flag listings with impossible values, like a 200-square-foot house with 8 bedrooms. The process is like trying to assemble a single engine from the mismatched parts of fifty different car models. It requires custom tooling and a deep understanding of the source systems’ quirks.
This data normalization is the foundation of every other feature. Your fancy AVM is worthless if it is being fed garbage data. Your search function is useless if it cannot understand the different ways to describe a two-story home. Fixing the data plumbing is not an “AI feature”. It is a prerequisite for building reliable software.
The Architectural Decision: Renting vs. Owning the Intelligence
Once you decide to tackle a real problem, the next question is architectural. Do you build the model in-house or do you call a third-party API? This is a critical decision with long-term consequences for your budget, your data security, and your ability to control your own product.
Using a pre-trained model from a major provider is fast. You can get a proof of concept running in days. The trade-off is control. You are sending your data to a black box. You have no visibility into how the model works, what biases it might have, or how it will change in the future. When the provider pushes an update, your application might break for reasons you cannot debug. You are fundamentally dependent on another company’s roadmap.
The Cost of Sovereignty
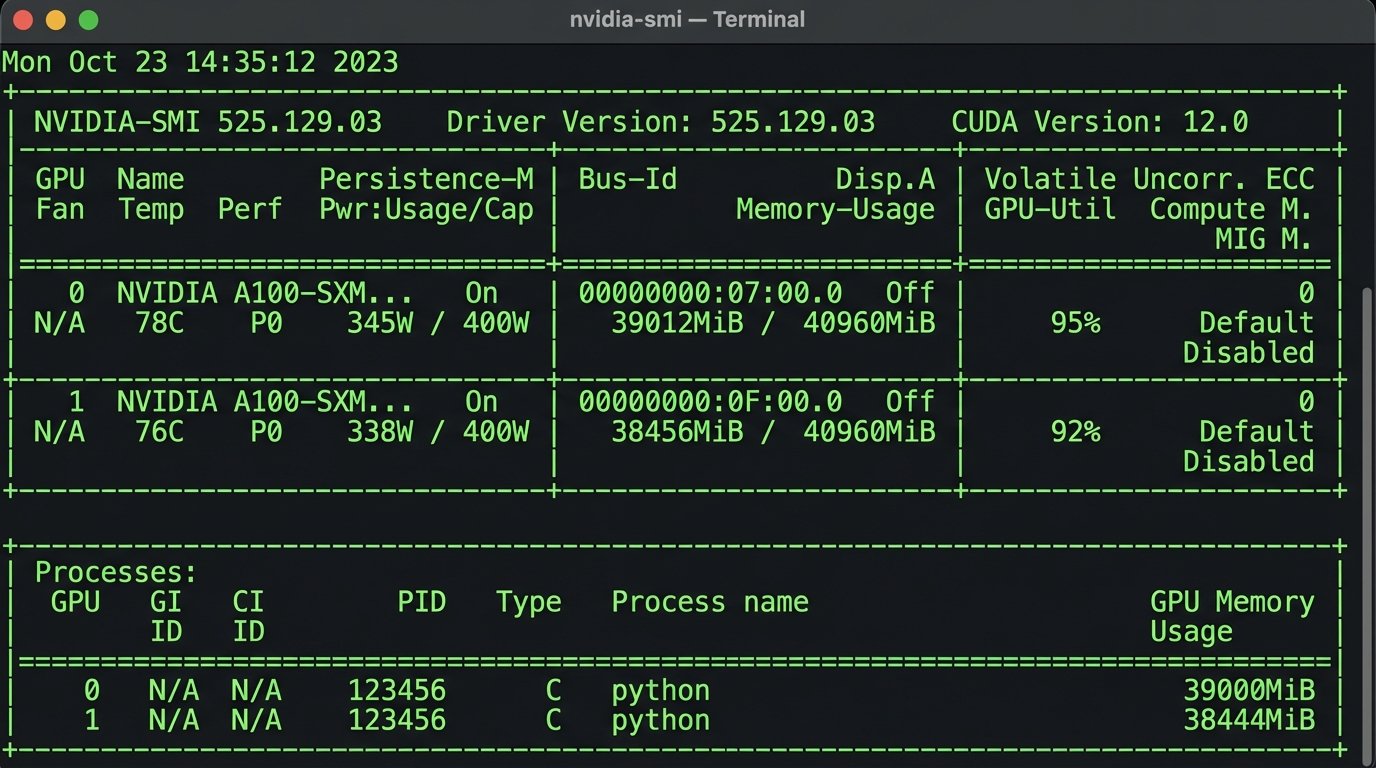
Building your own models is the path to data sovereignty and deep customization. You can train the model on your own proprietary data, fine-tuning it to the specific jargon and edge cases of your business. The model and the data stay within your infrastructure, eliminating many privacy concerns. You are in complete control.
This control comes at a steep price. You need a team with specialized skills in data science and MLOps. You need to pay for the GPU compute time to train the models, which is not cheap. You also need a robust infrastructure to serve the models in production with low latency and high availability. Owning the intelligence means owning the entire complex and expensive lifecycle of that intelligence.
There is no easy answer. For a non-critical function, an API might be sufficient. For a core business process, like document extraction or data normalization, the investment in a custom model is often justified. The critical point is to make this decision consciously, rather than defaulting to the path of least resistance.
The future of software in this industry will be defined not by those who bolt on the flashiest AI widgets, but by those who do the hard work of automating the core data processing that the entire system relies on. Stop chasing chatbots. Start parsing PDFs. Fix the data first.