
Most legal AI platforms are a thin veneer of natural language processing plastered over the same old keyword-driven databases. They sell you a conversational interface that, under the hood, still relies on brittle Boolean logic that fails to grasp context. The core mechanism is unchanged. You ask a question, and it pattern-matches strings in a document index, returning a list of results you still have to manually synthesize into a coherent legal argument.
This approach is a dead end. It offers marginal speed improvements for tasks a first-year associate was already doing. The actual shift in legal research technology is not about asking better questions. It is about fundamentally changing how the machine finds and structures the answers.
Gutting the Old Search Paradigm
Traditional legal research tools operate on a principle of lexical matching. You type “liability for defective products,” and the system hunts for documents containing those exact words or their synonyms. This process is fragile. A judge who prefers the phrase “culpability for faulty goods” in their opinion might be missed entirely. The system is a high-speed text scanner, not a comprehension engine.
AI-driven research bypasses this lexical dependency. It uses vector embeddings to map words, sentences, and entire documents to a high-dimensional mathematical space. The query “liability for defective products” and the sentence “The manufacturer was held accountable for the faulty item” are forced into close proximity within this vector space. The system retrieves documents based on conceptual closeness, not keyword overlap. It finds meaning, not just words.
This is not a simple feature upgrade. It is a full architectural replacement of the core search index.
The Mechanics of Vectorization in Case Law
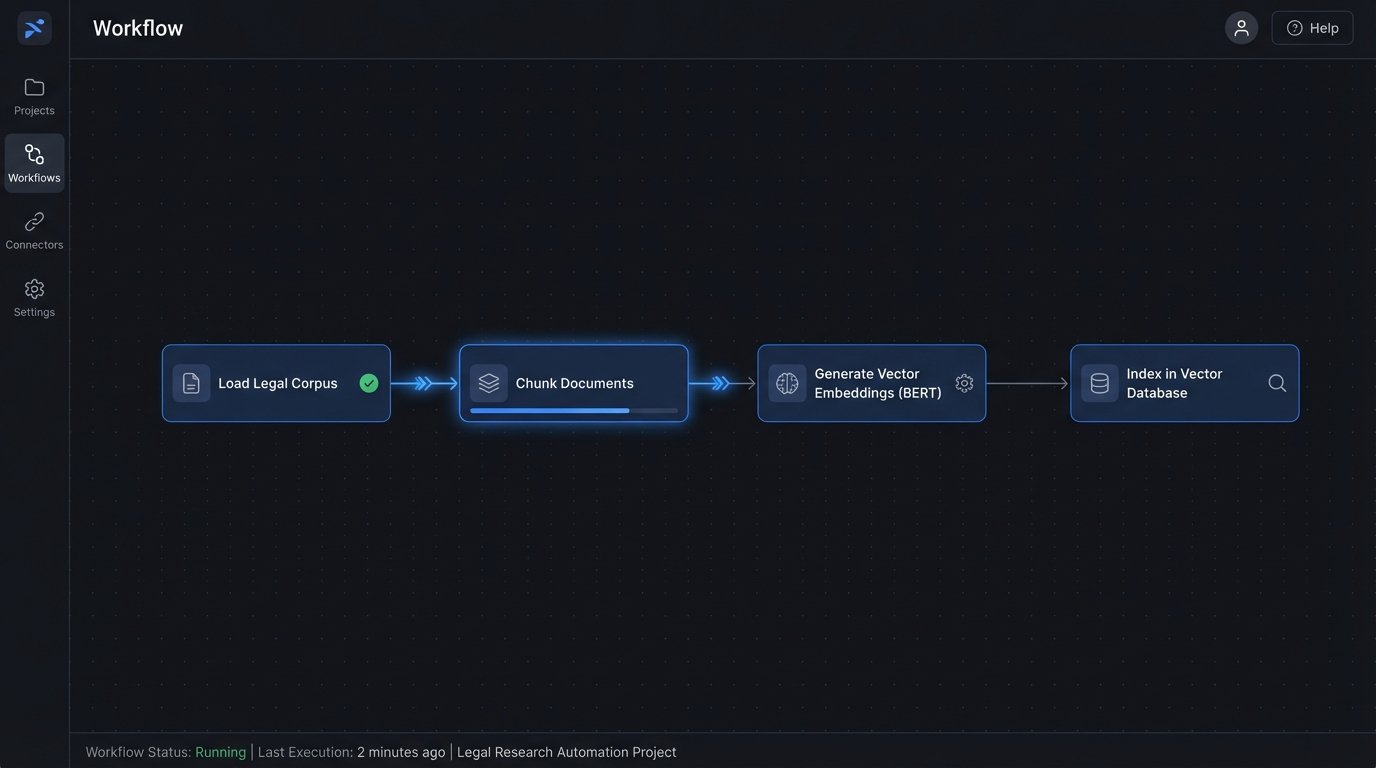
To implement this, you first need to process your entire legal corpus, whether it is public case law or your firm’s private document management system. A transformer model, like a BERT variant, reads every document and converts chunks of text into numerical vectors. These vectors, each a long list of numbers, represent the semantic essence of the text. They are then stored in a specialized vector database like Pinecone or Chroma.
When an attorney submits a query, the same model converts the query text into a vector. The system then performs a nearest neighbor search within the vector database. It calculates the mathematical distance between the query vector and every document vector in the index. The documents with the smallest distance, the closest conceptual neighbors, are returned as the primary results.
Forget memorizing complex search operators. The machine is now handling the nuance.
Retrieval-Augmented Generation: The Only Defensible Architecture
Dropping a generic large language model like GPT-4 into a law firm and letting it answer questions directly is malpractice waiting to happen. These models are not databases. They are probabilistic text generators trained on the public internet. They will confidently invent case citations, misstate legal tests, and “hallucinate” facts to provide a fluent-sounding answer.
The only technically sound approach is Retrieval-Augmented Generation (RAG). RAG forces the AI to ground its answers in a specific, trusted set of documents. It is a two-step process that separates information retrieval from text generation, creating a critical logic-check that prevents the model from inventing nonsense. Forcing a large language model to stick to a specific legal corpus is like building a Faraday cage around a radio transmitter. You can contain the signal, but stray frequencies still leak out without strict controls.
The workflow is rigid and essential:
- Step 1: Retrieval. The user’s query is first sent to the vector database. The system retrieves the top N most relevant document chunks from your firm’s trusted corpus. This could be specific case files, internal memos, or a curated subset of case law.
- Step 2: Augmentation. The retrieved text chunks are then dynamically injected into the prompt that is sent to the large language model. The system essentially tells the AI, “Using only the following information, answer the user’s question.”
- Step 3: Generation. The LLM generates a response, but its creative freedom has been massively constrained. It is forced to synthesize an answer based on the provided text, not its general knowledge base. The output also includes direct citations to the source documents used.
This architecture converts the LLM from a know-it-all oracle into a highly sophisticated summarization and synthesis engine that operates on a data set you control. It trades uncontrolled creativity for verifiable, auditable accuracy.
A Simplified RAG Prompt Structure
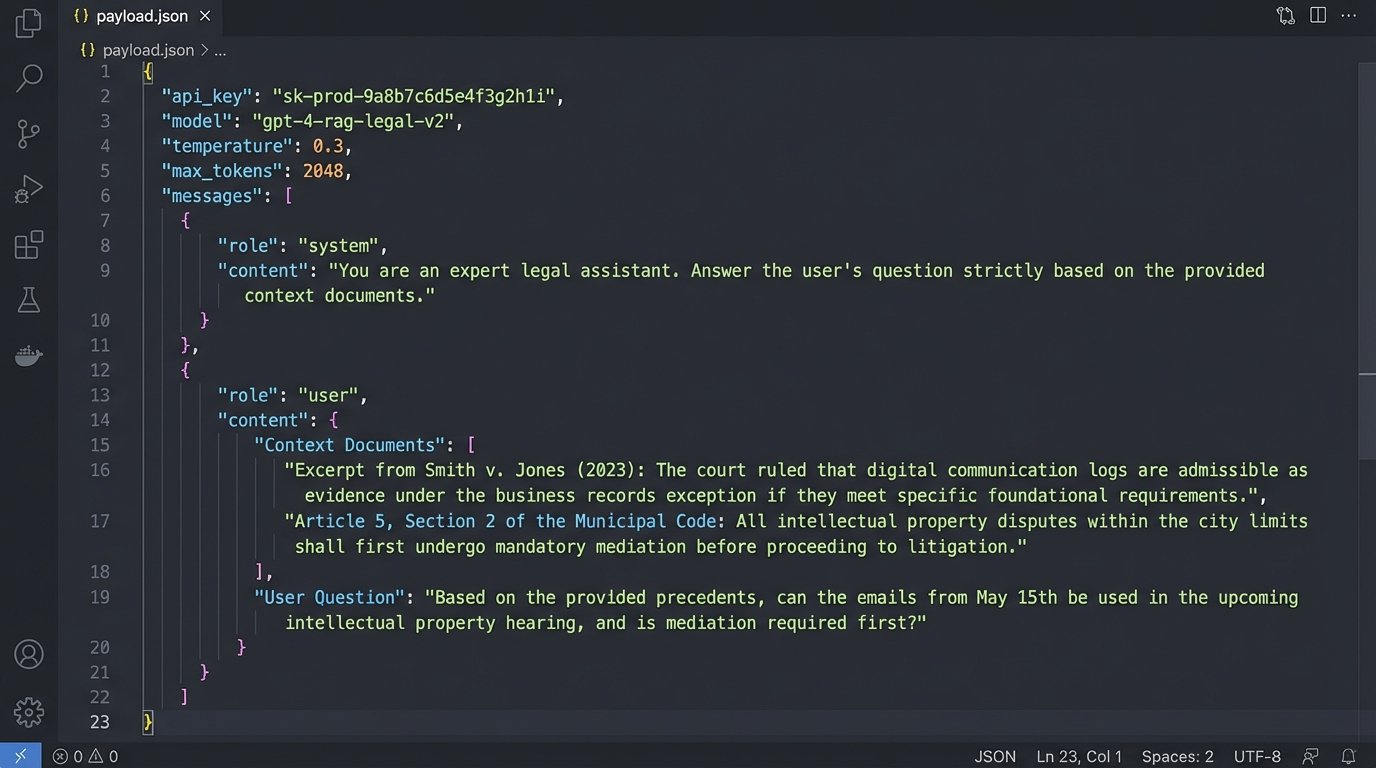
The actual prompt sent to the LLM’s API endpoint is the critical component. It is not just the user’s question. It is a carefully constructed set of instructions and data. A bare-bones version might look like this in a structured format, before being compiled into a final string for the API call:
{
"role": "system",
"content": "You are a legal analysis assistant. Answer the user's question based ONLY on the provided context documents. Do not use any external knowledge. Cite the source document for every claim you make using the format [Source: document_id]."
},
{
"role": "user",
"content": `
Context Documents:
---
Document ID: case_12345
Text: "The court in Smith v. Jones established a three-part test for negligence. The plaintiff must demonstrate duty, breach, and causation. The breach must be the proximate cause of the injury."
---
Document ID: memo_9876
Text: "Internal analysis suggests the causation element in the upcoming Miller case is weak. The connection between our client's action and the alleged damage is tenuous and relies on circumstantial evidence."
---
User Question:
"What is the standard for negligence and how does it apply to the Miller case?"
`
}
This structured prompt forces the model to operate within a sandbox of facts. Its output is directly traceable to the source material you fed it. There is no black box.
From Finding Documents to Structuring Arguments
The endgame for legal AI is not a better search tool. Search is a solved problem. The real challenge is synthesizing retrieved information into a structured, logical legal argument. The next generation of tools will not just give you a list of cases. They will give you a preliminary roadmap of your argument.
This involves several layers of processing that happen after the initial RAG step:
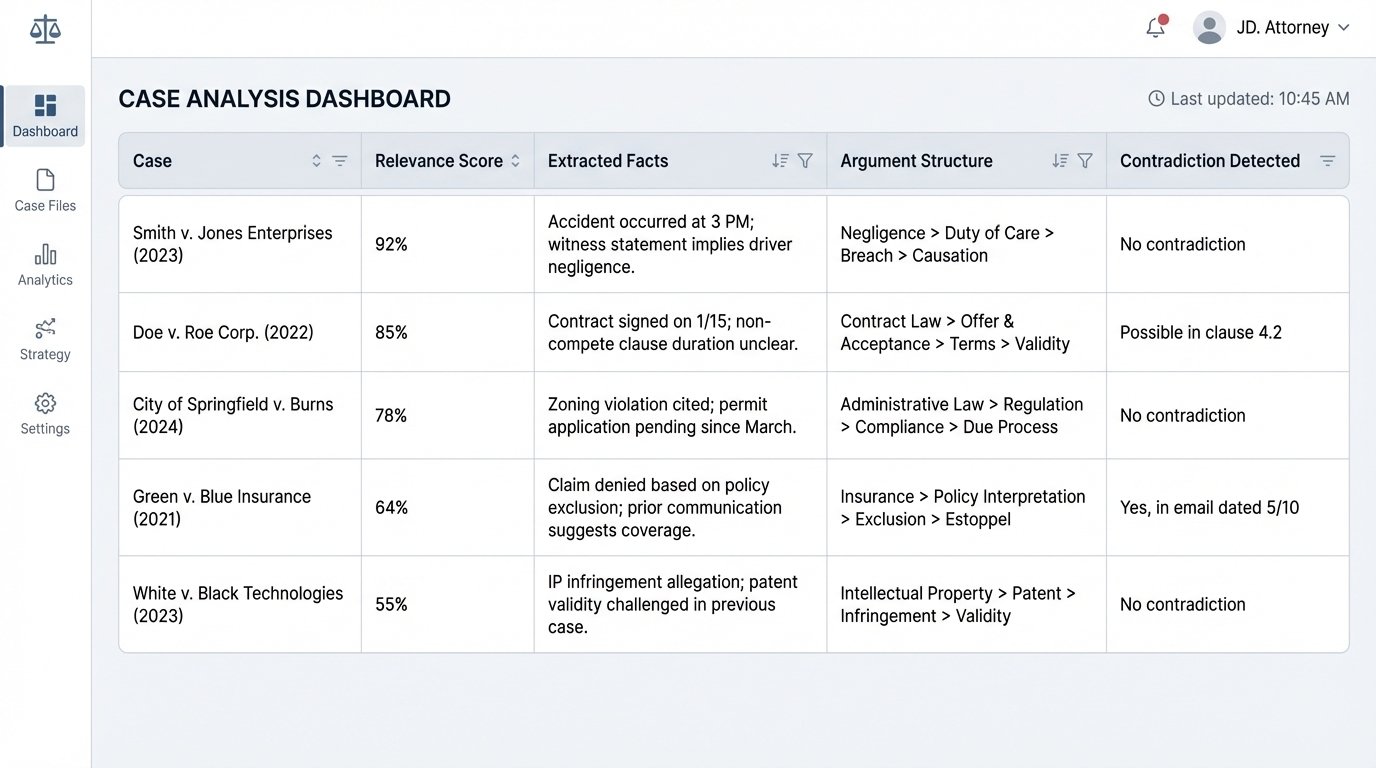
- Entity and Fact Extraction: The system scans the top retrieved documents to identify key entities like judges, courts, legal tests, and monetary amounts. It strips these facts from the unstructured text and organizes them.
- Argument Mining: More advanced models can identify the logical structure of a judicial opinion. They can differentiate between the holding, dicta, concurring opinions, and dissents. The system can flag which parts of the text are legally binding precedent versus persuasive commentary.
- Contradiction Detection: By comparing the logical claims across multiple documents, the system can automatically flag conflicting precedents or dissenting opinions that challenge your primary line of argument. It acts as an automated devil’s advocate, stress-testing your position before you even begin writing.
Instead of a paralegal spending ten hours reading and summarizing twenty cases, the machine produces an initial summary in minutes. The output is not a finished brief. It is a structured data object containing the key legal components, extracted facts, and flagged contradictions. The attorney’s job shifts from low-level research and summarization to high-level strategic validation and refinement of the machine-generated argument structure.
The Data Sovereignty Imperative
Using a public AI service for legal research injects an unacceptable level of risk into the practice of law. Sending queries that contain confidential client information to a third-party API is a data breach by another name. Vague assurances from vendors about data privacy are worthless without technical verification. You must demand to see the architecture.
There are two primary models for deploying these systems securely:
- Private Cloud Deployment: The vendor provisions a completely isolated instance of their application stack within a cloud provider like AWS or Azure, under your firm’s account. Your data never co-mingles with that of other customers. This is expensive but provides strong logical separation.
- On-Premises or Self-Hosted: For the most sensitive data, the entire system, from the vector database to the LLM itself, runs on servers physically located in your data center. This offers maximum control and security but requires significant in-house technical expertise to maintain. It is a wallet-drainer of the highest order.
Any vendor who cannot clearly articulate their multi-tenant isolation strategy or offer a private deployment option should be immediately disqualified. The convenience of a shared, public service does not justify the risk of breaking attorney-client privilege.
The Hidden Costs Beyond the License Fee
The sticker price for an AI research platform is just the entry fee. The real costs are in data preparation, integration, and ongoing maintenance. Your firm’s document management system is likely a mess of poorly tagged files, duplicates, and legacy formats. An AI system cannot function on dirty data.
Budgeting for a legal AI project must include a line item for a data sanitation project. This involves writing scripts to normalize file names, extract text from old scanned PDFs using OCR, de-duplicate documents, and tag everything with consistent metadata. Without this foundational work, your expensive AI tool will produce unreliable results. It is the unglamorous, mandatory prerequisite that sales teams never mention.
The integration with your existing case management system is another pressure point. You need to build a reliable pipeline to continuously feed new documents and case updates into the AI’s knowledge base. This often means wrestling with sluggish, poorly documented APIs from your legacy software providers. The project is not finished at launch. It requires constant monitoring and upkeep to ensure the data remains current and the connections are stable.