
The legal industry is being sold a fantasy. This fantasy is packaged as “AI Legal Research,” a push-button solution that promises to find the needle in a haystack of case law. The reality is a tangle of brittle API integrations, probabilistic models that confidently lie, and a fundamental misunderstanding of what these tools actually do. They are not thinking machines. They are complex text-completion engines fed on a diet of public, and often dated, legal documents.
Dumping your firm’s entire document corpus into a generic AI platform is not a strategy. It’s an expensive way to create a new, opaque data silo that you can’t properly audit.
Deconstructing the Black Box
Most commercial legal AI tools are built on Large Language Models (LLMs). These models predict the next word in a sequence based on statistical patterns in their training data. They possess no genuine understanding of legal principles, jurisdiction, or precedent. When a lawyer asks a question, the LLM is not reasoning. It is generating a statistically plausible-sounding answer. This distinction is the source of nearly every risk associated with these systems.
The most critical failure mode is hallucination. This is when the model generates factually incorrect or entirely fabricated information, from case citations to legal statutes. It’s not a bug that can be patched. It is an inherent property of how the models are designed. They are built to generate creative text, a feature that becomes a catastrophic liability when factual accuracy is the only thing that matters.
The industry’s current patch for this is Retrieval-Augmented Generation (RAG). The concept is straightforward. Instead of letting the LLM answer from its own vast, unverified memory, you first force it to retrieve relevant text chunks from a trusted, private document collection. The LLM then uses only these chunks to formulate its answer. This process grounds the model, reducing the chance it will invent facts out of thin air. It’s a necessary step, but it introduces its own significant architectural complexity.
The RAG Pipeline in Practice
Building a RAG system means you are now in the data pipeline business. First, you must process and chunk all your source documents, briefs, contracts, and case files. Each chunk is then passed through an embedding model, which converts the text into a high-dimensional vector, a string of numbers representing its semantic meaning. These vectors are loaded into a specialized vector database like Pinecone, Weaviate, or Chroma.
When a user query comes in, the same embedding model converts the query into a vector. The system then performs a similarity search in the vector database to find the document chunks whose vectors are mathematically closest to the query vector. These chunks, along with the original query, are stuffed into a prompt and sent to the LLM. The LLM’s job is now constrained to synthesizing an answer based only on the provided context. It’s like shoving a firehose of raw data through the needle-thin opening of a prompt window and hoping for a coherent stream on the other side.
This is a vast improvement over open-ended generation, but it is not a silver bullet. The quality of the output is now entirely dependent on the quality of the retrieval. If your retrieval mechanism pulls the wrong documents, the LLM will dutifully synthesize a wrong answer based on that wrong information.
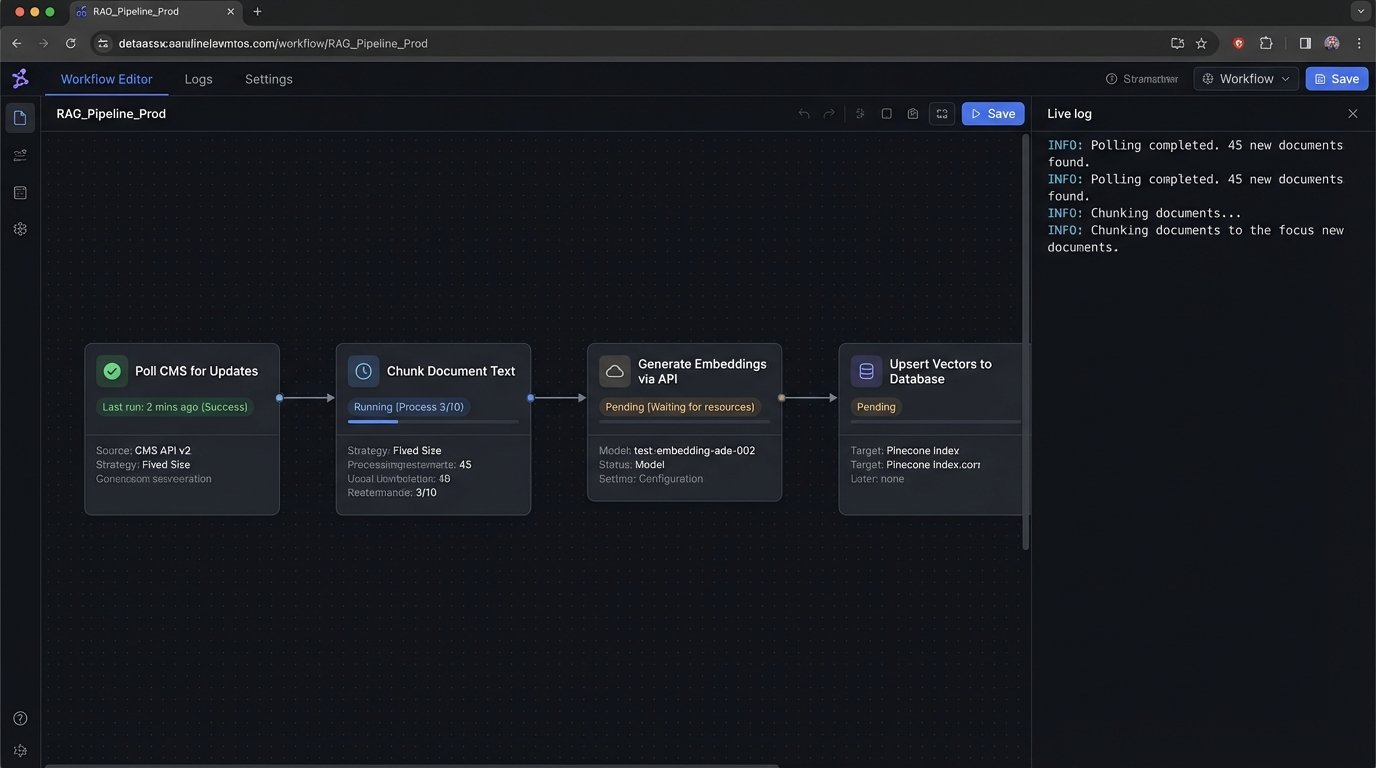
API Hell and Legacy System Integration
No AI tool works in a vacuum. It must be bridged to your firm’s existing systems, primarily the Case Management System (CMS) that holds the keys to the kingdom. This is where the polished marketing demos crumble against the hard reality of poorly documented APIs, legacy on-premise databases, and draconian rate limits. You cannot simply “connect” your AI to a 15-year-old SQL Server that was never designed for this kind of workload.
The integration work involves writing middleware to constantly poll the CMS for new or updated documents, trigger the vectorization pipeline, and manage the data flow. This code has to be ruthlessly efficient and packed with error-handling logic. What happens when the CMS API times out? What happens when a document is corrupted? What happens when the AI provider’s API key needs to be rotated? These are not edge cases. They are the daily reality of keeping a production system alive.
A simple Python script to fetch a document from a hypothetical CMS API illustrates the bare minimum of what’s required. Notice the explicit error handling for network issues, bad status codes, and JSON parsing failures. Every API endpoint in your stack needs this level of defensive coding.
import requests
import json
CMS_API_URL = "https://api.legacycms.com/v1/documents/"
API_TOKEN = "your_secret_api_token"
HEADERS = {"Authorization": f"Bearer {API_TOKEN}"}
def get_document_by_id(doc_id: int):
"""
Fetches a single document from the legacy CMS.
Includes basic error handling for production environments.
"""
try:
response = requests.get(f"{CMS_API_URL}{doc_id}", headers=HEADERS, timeout=10)
# Force a check for non-200 status codes
response.raise_for_status()
# Logic-check for expected content type before parsing
if 'application/json' in response.headers.get('Content-Type', ''):
return response.json()
else:
# Handle unexpected content types, e.g., HTML error pages
print(f"Error: Unexpected content type for doc_id {doc_id}")
return None
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
return None
except requests.exceptions.ConnectionError as conn_err:
print(f"Connection error occurred: {conn_err}")
return None
except requests.exceptions.Timeout as timeout_err:
print(f"Timeout error occurred: {timeout_err}")
return None
except json.JSONDecodeError:
print(f"Failed to decode JSON from response for doc_id {doc_id}")
return None
This snippet only retrieves one document. A real-world system needs to handle pagination, rate limiting, data transformation to strip out unusable metadata, and secure credential management. This is the unglamorous plumbing work that makes AI possible, and it often constitutes 80% of the total engineering effort.
The Vector Database: Your Newest Technical Debt
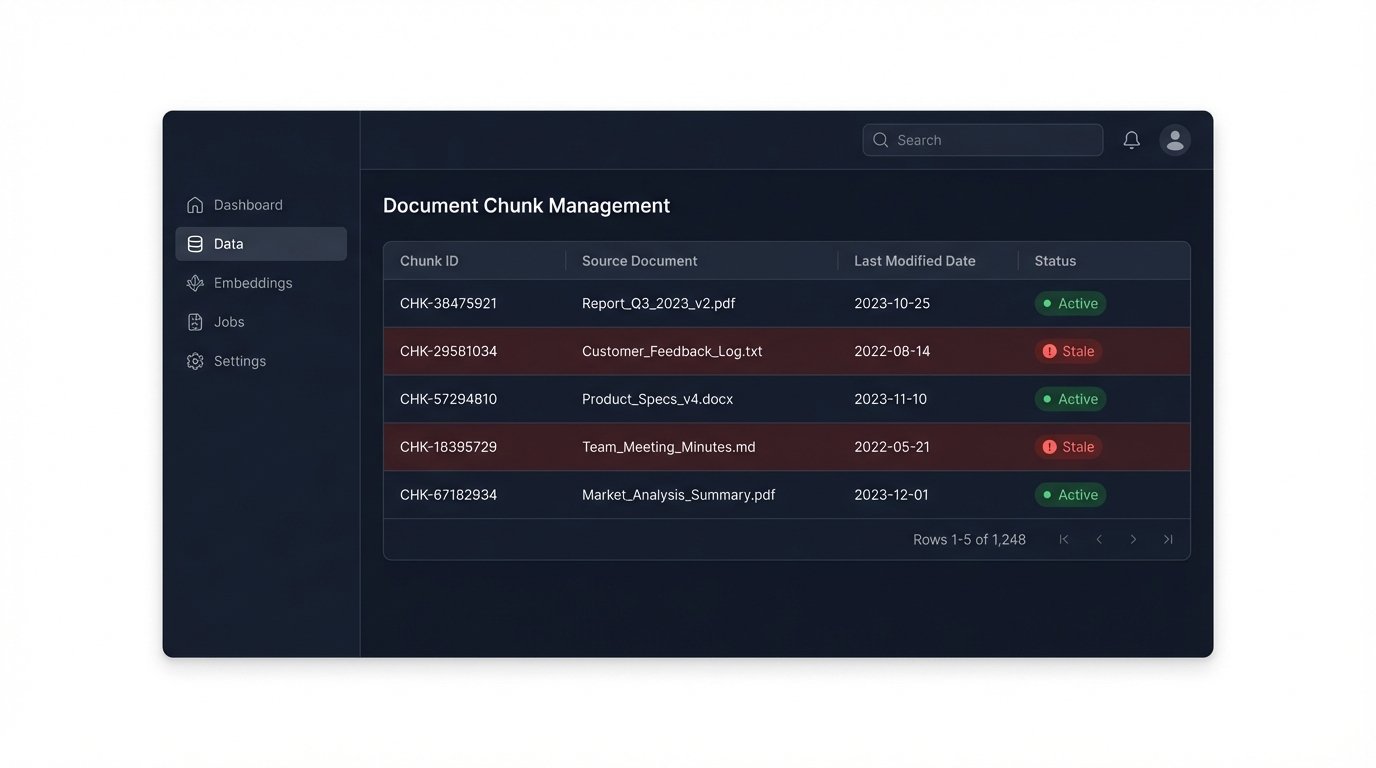
Vector databases are the backbone of modern RAG systems, but they are also a new and unfamiliar piece of infrastructure for most law firm IT departments. The choice of which embedding model to use has permanent consequences. If you vectorize 10 terabytes of documents using OpenAI’s `text-embedding-ada-002`, you are locked into that model’s specific vector space. If a better model is released next year, you cannot simply switch. You must re-process and re-embed your entire document collection, a process that is both computationally expensive and time-consuming.
This creates a form of technical debt. Your data’s usefulness is now tied to the lifecycle of a specific machine learning model. Furthermore, you have to manage the update process. When a brief is amended or a contract is revised, you must have a mechanism to find and replace the old document chunks in the vector database. A failure to do so results in data rot, where your AI is retrieving and citing outdated information. This is a subtle but dangerous failure mode that can silently poison the system’s reliability over time.
A More Durable Architecture: The Legal Knowledge Graph
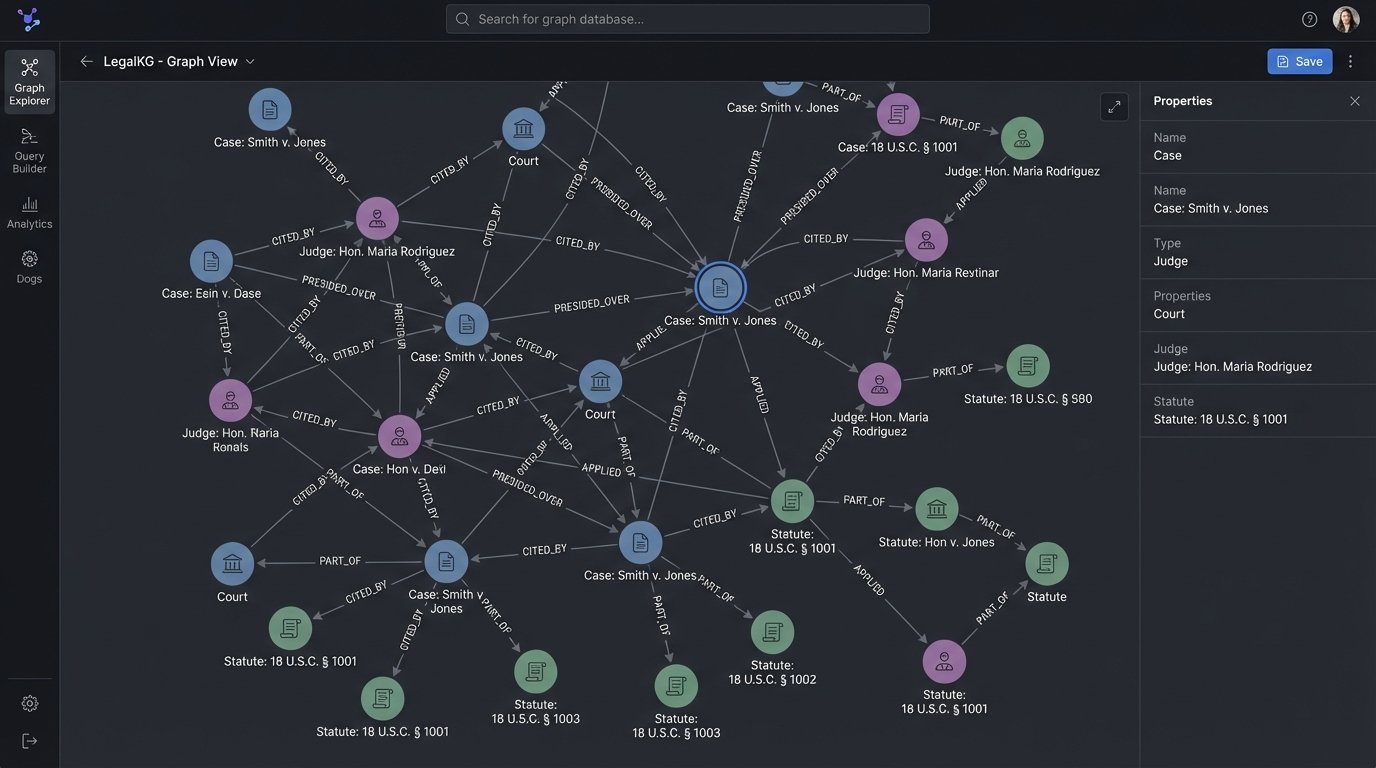
RAG and vector search are a powerful but blunt instrument. They find semantically similar text. They cannot answer precise, structured questions with deterministic accuracy. For that, a different architecture is required: a knowledge graph. Instead of treating documents as bags of text, a knowledge graph approach extracts structured entities and their relationships.
This process involves using AI, but in a more controlled way. We can use Named Entity Recognition (NER) models fine-tuned on legal text to identify and extract key entities like judges, courts, plaintiffs, defendants, statutes, and case names. Once extracted, these entities become nodes in a graph. The relationships between them, such as “cited,” “overruled by,” “affirmed on appeal,” or “presided over by,” become the edges connecting the nodes. This structured data is then stored in a graph database like Neo4j.
The result is a system that can answer complex queries with perfect precision. A query like, “Show me all cases presided over by Judge Smith in the Southern District of New York that cite Marbury v. Madison,” is not a semantic search. It is a precise traversal of the graph. The system returns a list of nodes that meet those exact criteria. There is no probability, no guessing, and no hallucination. The answer is either in the graph or it is not.
Building this system is a heavier engineering lift than setting up a RAG pipeline. It requires expertise in data modeling, NLP, and graph databases. But the result is a durable, auditable, and intellectually honest asset for the firm. It is a system of record, not a probabilistic answer machine.
The Security and Compliance Minefield
The final consideration is security. Sending client-privileged information to a third-party AI provider’s API is a high-risk activity. Even with contractual promises of zero data retention, the data must travel over the public internet and be processed on infrastructure you do not control. This presents an attack surface that many firms, and their clients, will find unacceptable.
The alternative is to self-host open-source LLMs and embedding models. This gives you complete control over the data, which never leaves your own private cloud or on-premise servers. However, this path is a wallet-drainer. Running production-grade models requires significant investment in GPU hardware, and you need the in-house talent to manage and maintain this complex infrastructure. It is a classic build vs. buy decision, but with security and client confidentiality hanging in the balance.
Firms must force their security officers and engineering leads to have this conversation. A decision to use a SaaS AI platform is a decision to accept a certain level of data-handling risk. That risk must be explicitly acknowledged and weighed against the cost and complexity of building a self-hosted alternative.
The rush to adopt AI in legal research is creating a generation of brittle, unreliable, and insecure systems. The tools are powerful, but they are not intelligent. They are data processing engines that must be integrated with surgical precision and a healthy dose of skepticism. Instead of chasing the fantasy of a robot lawyer, firms should focus on using these technologies for what they are good at: extracting and structuring information. Building a deterministic knowledge graph is harder work, but it creates a lasting asset that provides accurate, verifiable answers. That, not a chatbot that can imitate a lawyer, is the real future.