
The hype around AI in legal research is deafening. Vendors promise a magic box that digests a vague query and spits out a perfect motion to dismiss. This narrative is not just wrong; it is technically illiterate. An AI, specifically a Large Language Model or LLM, is a statistical engine for predicting the next word in a sequence. It has no concept of truth, justice, or legal precedent. Treating it as a junior associate is the fastest path to malpractice.
The real conversation is not about whether AI will replace lawyers. It is about the brutal, unglamorous engineering required to make these systems do anything useful without fabricating case law. The future of law depends not on the models themselves, which are rapidly becoming commodities, but on the data pipelines, validation layers, and human-in-the-loop workflows that firms build around them. Anything less is just expensive fortune-telling.
Deconstructing the AI Research Stack
Most legal AI tools are built on a simple architecture known as Retrieval-Augmented Generation (RAG). This is a two-step process. First, your query is used to retrieve relevant documents from a database. Second, those documents are stuffed into the context window of an LLM, which then generates an answer based *only* on that provided text. The quality of the final output is therefore entirely dependent on the quality of that initial retrieval step.
This is the system’s central point of failure.
Vector Databases: The Illusion of Understanding
The retrieval mechanism is almost always a vector database. This system takes documents, chops them into chunks, and uses an embedding model to convert each chunk into a string of numbers, a vector. This vector represents the chunk’s semantic meaning in a high-dimensional space. When you submit a query, it is also converted into a vector, and the database finds the document chunks with the “closest” vectors. Proximity equals relevance.
The problem is that semantic similarity is a poor proxy for legal relevance. A vector search might correctly identify that a case about a shipping “pier” is semantically similar to your query about corporate “piercing the veil.” The machine sees overlapping concepts of structure and liability. The human sees a fatal, context-free error. The database has no legal ontology. It just matches numerical patterns.
Relying on this alone is an abdication of technical responsibility.
RAG’s Hallucination Problem
Once the vector search returns its list of hopefully-relevant document chunks, they are fed to the LLM. The model is then instructed to answer your original question using only this information. If the retrieval step pulled irrelevant or contradictory documents, the LLM will dutifully synthesize an answer from that garbage. It will state its output with absolute confidence, even if the underlying data is nonsensical.
This is not the AI “hallucinating” in the popular sense. It is the AI performing its function perfectly, based on flawed input. The hallucination happened during the retrieval step, and the LLM is just the final stage of the error cascade. Connecting a new AI tool directly to a legacy case management system without a proper data validation layer is like hooking a fire suppression sprinkler system to a sewer line. You will put out the fire, but the collateral damage from the filth you spray everywhere will be the real disaster.
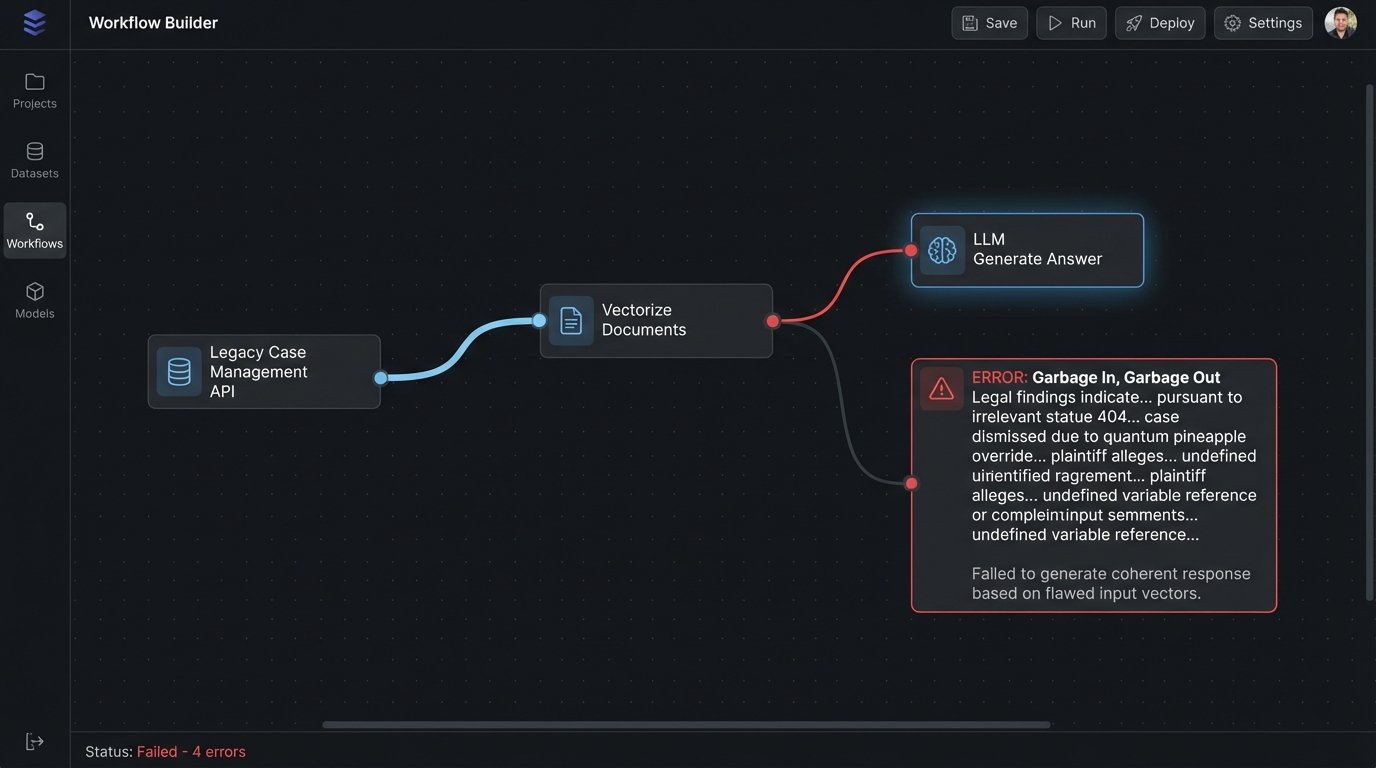
The integration with existing firm infrastructure is where these projects truly die. Your firm’s knowledge is not in a clean, indexed database. It is spread across a thousand Word documents on a network share, locked in a sluggish, decade-old case management system with a poorly documented REST API, and stuck in the outboxes of senior partners. Getting that data into a usable format for a vector database is a data engineering nightmare that most off-the-shelf AI solutions conveniently ignore in their sales pitches.
A More Realistic Architecture
The future is not about asking better questions to a generic AI. It is about building systems that construct better queries for the AI. This means moving away from simple semantic search and toward an architecture that understands legal entities and their relationships. The goal is to reduce the search space *before* the query ever hits the vector database, forcing the AI to work with a pre-qualified, highly relevant set of documents.
This approach has two main components: structured data injection and the development of a legal knowledge graph.
Structured Data Injection
Instead of passing a raw natural language query to the RAG system, we first need to enrich it with structured metadata. This involves building a pre-processing layer that identifies key legal entities in your firm’s documents: judges, courts, jurisdictions, case types, motion types, and cited statutes. This metadata is stored alongside the document vectors.
When a user asks a question, the system does not just search for the question’s text. It uses the metadata to build a far more specific, filtered query. For example, instead of searching for “cases about summary judgment for breach of contract,” the system constructs a query that programmatically filters for documents tagged with `motion_type: summary_judgment`, `case_type: breach_of_contract`, and `jurisdiction: SDNY`. This drastically narrows the pool of potential documents, shunting aside irrelevant noise and increasing the probability that the retrieved context is actually useful.
Here is a simplified Python representation of this logic. Notice how we are not just passing text, we are building a precise query object.
# This is a conceptual example, not production code.
def build_filtered_query(natural_language_query, case_metadata):
"""
Constructs a precise query object by combining
natural language with structured metadata filters.
"""
filters = []
if case_metadata.get("judge_name"):
filters.append(f"judge_name = '{case_metadata['judge_name']}'")
if case_metadata.get("jurisdiction"):
filters.append(f"jurisdiction = '{case_metadata['jurisdiction']}'")
# The final payload sent to the search system
# contains both the text vector and the hard filters.
structured_query = {
"query_text": natural_language_query,
"filters": " AND ".join(filters)
}
return structured_query
# Example usage
query = "precedents for dismissing a case on procedural grounds"
metadata = {
"judge_name": "Esther Salas",
"jurisdiction": "D.N.J."
}
final_query_object = build_filtered_query(query, metadata)
# The search backend now executes a hybrid search.
# It performs a vector search on the query_text ONLY on documents
# that have already passed the metadata filter check.
This method forces discipline on the system. It prevents the LLM from drawing conclusions from a ridiculously broad set of data. It is more work upfront, but it is the only way to build a reliable research tool.
Building a Legal Knowledge Graph
The next level of maturity is to move beyond document tagging and build a true knowledge graph. Using a graph database like Neo4j, you can model the relationships between legal entities. A case is not just a document; it is a node in a graph that is `presided_over_by` a judge node, `cites` other case nodes, and `interprets` a statute node.

Building this graph is a significant data modeling and extraction challenge. It requires sophisticated entity recognition models to parse documents and identify these relationships. The payoff is immense. You can perform queries that are impossible with a simple vector search, like “Show me all cases where Judge Smith cited Judge Jones’s opinion on Rule 12(b)(6), and find the common legal arguments used by the prevailing parties.” This is a query about relationships, not just keyword similarity.
This graph then becomes another input for your RAG system. The results from a graph query can provide hyper-specific context to the LLM, allowing it to generate analysis that is deeply rooted in the structural reality of the law, not just the statistical proximity of words.
How to Prepare for This Shift
Firms cannot just buy their way into this future. The vendors selling “AI-powered” solutions are often just providing a slick user interface on top of the same flawed RAG architecture. The real competitive advantage comes from the proprietary data and systems you build in-house.
Start with Data Hygiene Now
Your AI system will only ever be as good as the data you feed it. The most important project you can start today has nothing to do with AI. It is about getting your firm’s data in order. Institute a mandatory, firm-wide policy for document management. Standardize naming conventions. Implement a consistent metadata tagging schema for every new document. Migrate away from scattered network drives to a centralized document management system with a usable API.
This is thankless, difficult work. It is also the absolute prerequisite for anything that follows. Without a clean, structured data source, any AI project is doomed before it starts.
Pilot Small, Validate Brutally
Do not attempt to build an “all-knowing” legal AI. Pick one, specific, high-pain, low-complexity research task. For example, generating a timeline of events from a set of deposition transcripts, or finding all contracts with a specific non-compete clause. Build a small pilot system to automate just that one task.

Then, measure its performance obsessively. Run the AI’s output against the work of a junior associate. Track accuracy, speed, and, most importantly, the number of “correctable errors” versus “catastrophic failures.” The goal is not to be perfect. The goal is to build a system that fails predictably and safely, allowing for efficient human review.
Invest in Engineers, Not Subscriptions
The core LLMs are a commodity. The real value is in the engineering that glues them to your specific data and workflows. Stop shopping for a magic AI product. Start investing in people. Hire a legal engineer or train a tech-savvy paralegal who understands Python and APIs. The person who can write a script to pull data from your CMS, clean it, and run it through a classification model is infinitely more valuable than a subscription to a generic AI chat interface.
The future of law is not a disembodied AI brain. It is a human lawyer augmented by a custom-built, data-driven system that they understand and control. The firms that will win are the ones that recognize this is an engineering challenge, not a procurement problem.