
Most conversations about legal automation are a waste of time. They focus on superficial user interfaces and vendor promises of one-click solutions. The actual work happens in the plumbing, wrestling with brittle APIs and normalizing data from systems that should have been decommissioned a decade ago. The real trends are not about replacing lawyers but about building data-centric engines that force structure onto chaotic legal processes.
Forget the marketing slicks. The following are the tangible shifts in legal automation that directly impact architecture, data integrity, and a firm’s ability to operate without drowning in manual, repetitive tasks. These are not plug-and-play tools. They are architectural patterns that require engineering discipline.
Headless Document Generation
The old model of embedding logic inside Word templates via macros or clunky plugins is dead. It’s impossible to maintain, version control is a joke, and it collapses under the weight of conditional complexity. The forward-thinking approach is to completely decouple the data from the presentation layer. This means treating your documents as a final rendering target, not a container for business rules.
The core components are a structured data source, typically a JSON object, and a clean template file. We strip all logic from the DOCX or PDF file itself, leaving only placeholders. An engine, running on a server, takes the template, injects the JSON data into the corresponding placeholders, and renders the final, populated document. This moves the complexity from a fragile document file into testable, version-controlled code.
This is the difference between hard-coding values in an application and pulling them from a configuration file. It’s basic software engineering hygiene applied to a legal workflow.
The Technical Benefit: Scalability and Control
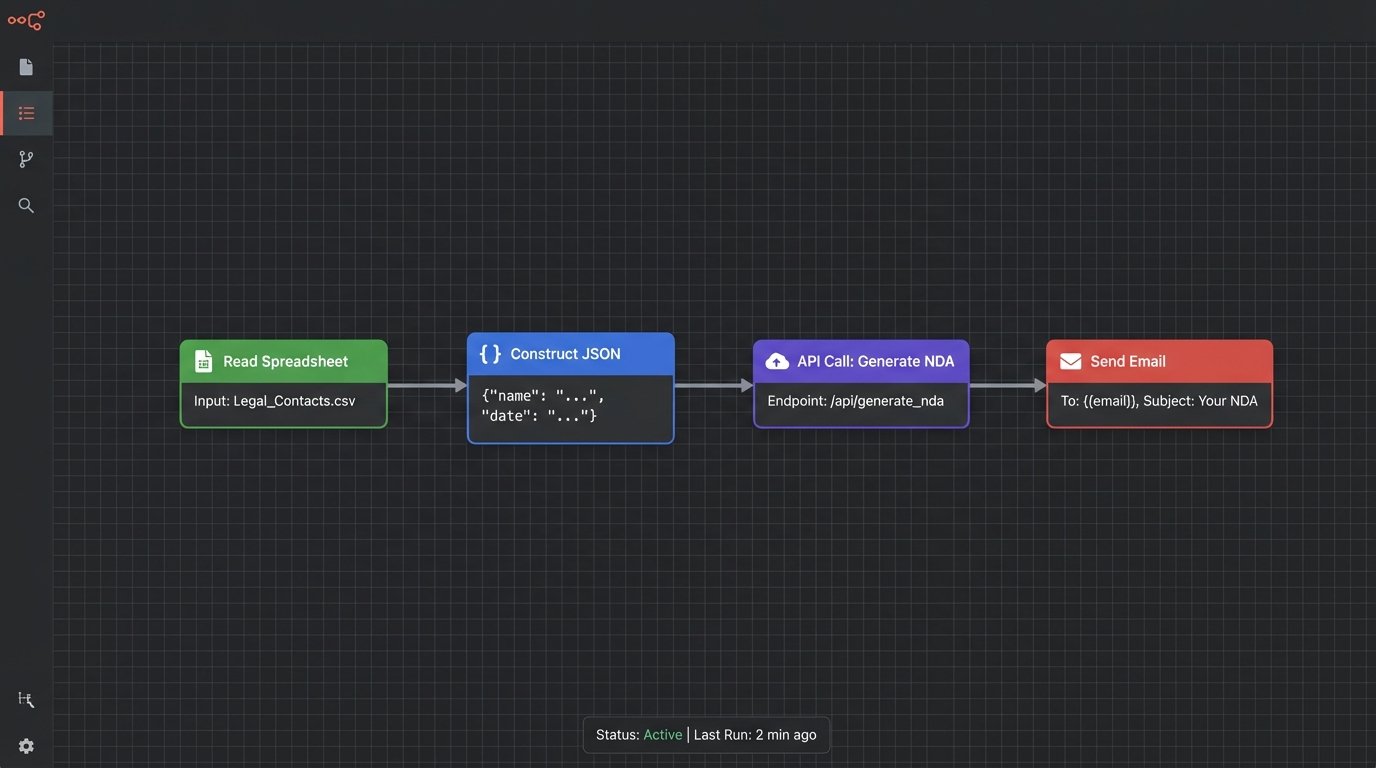
This architecture allows a firm to generate thousands of customized documents programmatically via a single API call. A paralegal can trigger a workflow that queries the case management system for matter details, constructs a JSON object, and calls the generation endpoint to produce a batch of engagement letters. The templates are stored centrally and can be updated without touching the underlying application code.
This breaks the dependency on desktop software and moves document assembly into a service-oriented model. You stop emailing templates around. You start calling services.
Use Case: High-Volume M&A Diligence
A firm handling a large merger needs to generate 500 unique NDAs for various third-party consultants. Instead of manual creation, a script iterates through a list of consultant details (name, entity, address). For each record, it constructs a specific JSON payload and sends it to the document generation service. The service returns a link to the generated PDF, which is then automatically emailed to the recipient through another service call. The entire process is logged, auditable, and takes minutes.
The real choke point is no longer document creation. It’s getting clean, structured data to feed the engine in the first place.
AI-Powered Contract Data Extraction
Contract review is a data problem disguised as a legal problem. For years, the solution was to throw more junior associates at the task. Now, we use fine-tuned language models to parse unstructured contract text and return structured JSON. This is not simple optical character recognition (OCR), which just turns a picture of text into text. This is about extracting semantic meaning.
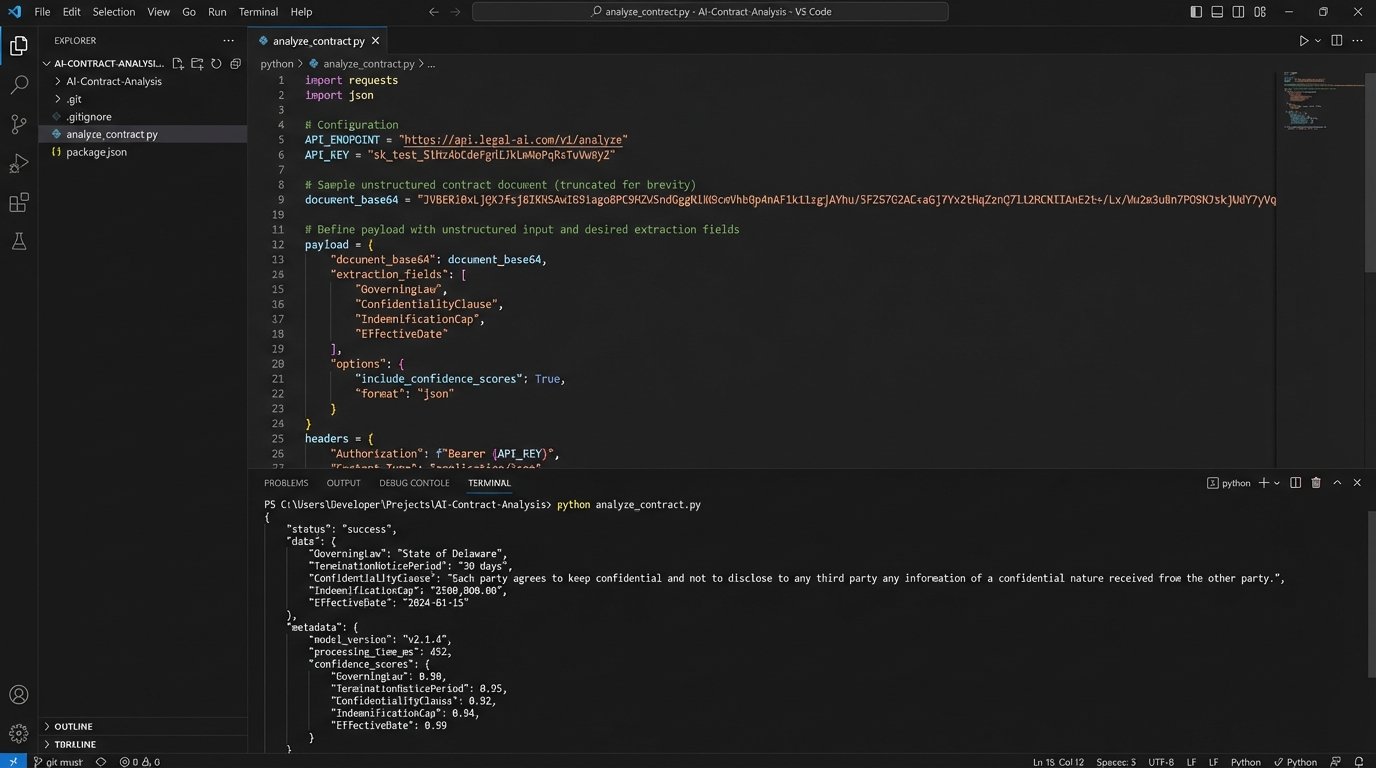
The process involves sending a document, usually as a PDF or DOCX file, to an AI model’s API endpoint. The prompt instructs the model to identify and extract specific clauses, dates, and entities. For instance, you can ask it to find the “Governing Law,” “Limitation of Liability,” and “Term” clauses and return them in a predefined JSON format. This transforms a dense, 80-page document into a predictable data object.
Getting this to work reliably is like trying to shove a firehose through a needle. The input documents are a chaotic mix of scanned images, native PDFs, and files with bizarre formatting artifacts. Pre-processing the files to clean and normalize them is 80% of the battle.
The Technical Benefit: Structured Data from Unstructured Chaos
This approach allows you to build a searchable, queryable database of your firm’s entire contract history. You can run queries like, “Show me all client agreements signed before 2020 that have a liability cap under $1 million.” This is impossible when your contracts live as individual, inert files on a shared drive. It turns a document repository into a data warehouse.
A simple API call might look something like this, using a hypothetical extraction service.
{
"model": "legal-contract-analyzer-v4",
"document_base64": "JVBERi0xLjUNCiX...truncated...",
"extraction_fields": [
{"field_name": "GoverningLaw", "description": "Identify the state or country whose laws govern the agreement."},
{"field_name": "IndemnityClause", "description": "Extract the full text of the indemnification section."},
{"field_name": "TerminationNoticePeriod", "description": "Find the number of days required for notice of termination for convenience."}
]
}
The challenge is that the response is not guaranteed to be accurate. The model can misinterpret ambiguous language or simply “hallucinate” a value that isn’t there. This means any production workflow must include a human validation step. It’s an accelerator, not a replacement.
Use Case: Systematizing Lease Abstraction
A real estate practice needs to analyze a portfolio of 2,000 commercial leases. An automated workflow ingests the scanned leases, runs them through an OCR engine to produce raw text, and then sends that text to a language model. The model is prompted to extract key data points: lease start and end dates, renewal options, rent escalation clauses, and subletting permissions. The extracted data populates a central database, which is then reviewed for anomalies by a small team of paralegals.
The automation does the first 90% of the work. The humans handle the final 10% of validation and edge cases, which is a far more efficient use of their time.
Composable e-Discovery Workflows
The monolithic e-Discovery platforms are dinosaurs. They lock you into a single, proprietary ecosystem where every feature, from processing to review, comes with an exorbitant price tag. Moving data between these walled gardens is intentionally difficult and expensive. The modern approach is to build a composable pipeline using best-in-class tools for each stage of the EDRM, connected by APIs.
This means you might use one vendor’s tool for data ingestion and early case assessment because it’s fast and cheap. Then, you programmatically push the culled data set to a different platform that specializes in technology-assisted review. Finally, the documents marked for production are exported via API to a third service that handles Bates stamping and formatting. You stitch together a workflow that fits your needs and budget.
You become the systems integrator. This gives you immense flexibility but also makes you responsible for every point of failure.
The Technical Benefit: Flexibility and Cost Management
By breaking the monolithic chain, a firm can avoid vendor lock-in. If a processing engine becomes too expensive or a review platform’s performance degrades, you can swap it out with a competitor without having to migrate your entire e-Discovery operation. It forces vendors to compete on performance and price at each stage of the workflow, rather than on the stickiness of their all-in-one platform.
This architectural choice prioritizes modularity over convenience. It’s more work to set up and maintain, but it prevents a single vendor from holding your data and your budget hostage.
Use Case: Building a Bespoke Litigation Support Stack
A boutique litigation firm decides its primary review platform is too sluggish for complex productions. They keep the platform for linear review but build an integration with a specialized data analytics tool. When privileged documents need to be logged, the document metadata is exported via the review platform’s API and sent to a custom-built web application for logging. For production, the final set is pushed to a low-cost, high-throughput production engine. The firm chooses the right tool for each job instead of forcing one tool to do everything poorly.
The connections are the weak points. An unannounced API change by one vendor can break the entire chain, often during a critical production deadline.
Logic-Gated Client Intake
Standard client intake is a passive process. A potential client fills out a web form, that data is emailed to a distribution list, and then someone manually enters it into three different systems: CRM, conflicts, and billing. This is inefficient and prone to human error. A logic-gated system injects automation directly into the intake workflow itself.
As a user fills out the form, the back-end services are already at work. When the potential client enters their name, an API call is made in real-time to the conflicts database. When they enter the names of adverse parties, more calls are made. The system cross-references these against all current and former client matters. If a high-probability conflict is detected, the form submission can be programmatically halted, and the user can be shown a message to call the firm directly.
This turns a dumb data collection tool into an active risk management system.

The Technical Benefit: Real-Time Conflict Checking and Data Validation
The primary benefit is speed and accuracy in conflict checking. It reduces the risk that a new matter will be opened before a comprehensive check is complete. It also enforces data integrity from the very beginning. Instead of a paralegal trying to decipher a client’s messy form submission, the system can validate addresses, pre-populate known company information from corporate data APIs, and ensure all required fields are present and correctly formatted before the data ever hits your internal systems.
This requires that your internal systems, particularly your case management and billing databases, are accessible via stable, well-documented internal APIs. For most firms, this is the main roadblock.
Use Case: Automated Onboarding for High-Volume Practices
An immigration law firm processes hundreds of new client inquiries a week. Their online intake form is connected to their case management system. As a client provides their information, the system automatically creates a provisional matter record, runs a preliminary conflict check, and, if no conflicts are found, generates an engagement letter using the headless document generation service mentioned earlier. The letter is sent to the client for e-signature. A partner only gets involved for the final review and counter-signature.
This workflow compresses a multi-day, multi-person process into about fifteen minutes of automated steps and five minutes of human review. It fails, however, if the underlying data in the case management system is a mess, leading to either false positive conflict hits or, worse, missed conflicts.