
The entire legal tech market is selling a fantasy. The pitch is a seamless, AI-driven utopia where intelligent agents handle discovery and automation eliminates paralegal grunt work. This narrative is pushed by vendors with half-baked products and consumed by partners who think technology is a magic wand. The ground-level reality is a swamp of disconnected systems, dirty data, and automation workflows held together with digital duct tape. The actual trend isn’t the rise of some mythical AI lawyer; it’s the brutal, unglamorous work of forcing structure onto decades of operational chaos.
Forget the marketing slicks. The future isn’t about buying a single, brilliant piece of software. It’s about having the technical discipline to build a coherent data strategy and the operational stomach to enforce it.
Deconstructing the “AI” Label
Most tools marketed as “legal AI” are not intelligent in any meaningful sense. They are overwhelmingly based on statistical models, natural language processing (NLP) for entity extraction, and occasionally, machine learning for predictive coding. This technology is decades old. E-discovery platforms have used predictive analytics to rank document relevance for years. Now, it’s just been rebranded with a more impressive acronym.
The process is straightforward. An NLP model is trained to recognize specific entities: names, dates, organizations, contract clauses. When you feed it a document, it doesn’t “read” or “understand” the text. It performs pattern matching against its training data, flagging text strings that have a high statistical probability of being what you’re looking for. It’s a more sophisticated version of hitting Ctrl+F.
This approach is effective for specific, narrow tasks. It can gut a 50-page contract for change of control clauses or strip dates from a mountain of emails. It fails spectacularly when asked to interpret nuance, context, or intent. The system has no concept of legal theory. It only knows that a certain sequence of words frequently appears in documents tagged as “Force Majeure.”
The dependency is always the quality of the input data. A model trained on clean, well-labeled contracts from the energy sector will produce gibberish when applied to M&A agreements in biotech. Garbage in, garbage out. Always.
The Generative AI Complication
Generative models like GPT-4 are a different beast, but they introduce a new set of problems. These Large Language Models (LLMs) are incredibly powerful for generating first-draft text. They can summarize depositions, draft boilerplate motions, and rephrase discovery requests. Their function is probabilistic text generation, not factual recall or logical reasoning. The model predicts the next most likely word in a sequence based on its massive training dataset.
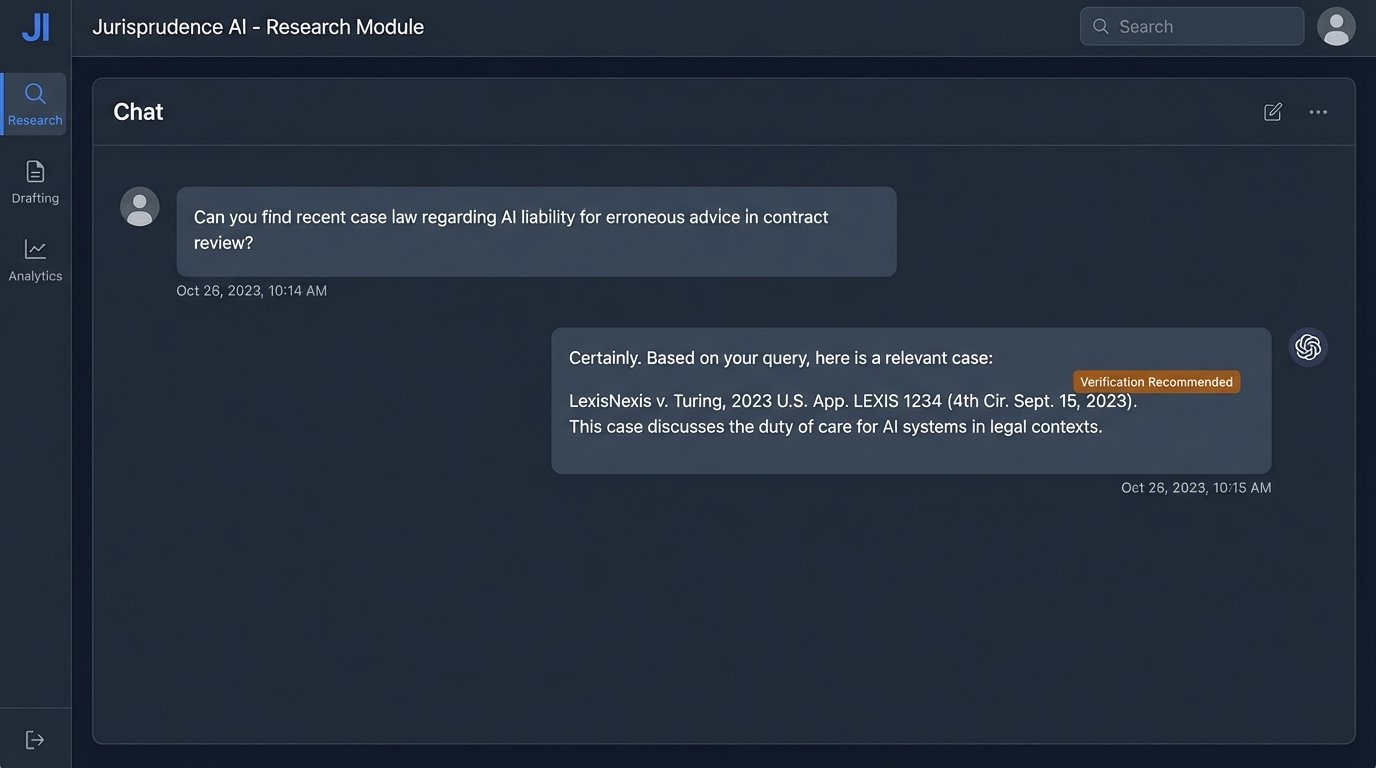
This mechanism is why LLMs “hallucinate.” They invent case citations that look plausible but are completely fabricated. They will confidently state incorrect legal principles because the language structure of the statement matches patterns in their training data. Using a public LLM for substantive legal work without a human expert performing a line-by-line validation is malpractice waiting to happen. It is not an analyst; it is a text engine.
Data privacy is the other massive, unresolved issue. Every query sent to a public API is data you no longer control. Sending client-confidential information to a third-party model is an ethical and security black hole. On-premise or private cloud models mitigate this, but they are wallet-drainers to set up and maintain. They require significant hardware and specialized talent to fine-tune and operate.
The Real Work: Data Structure and System Integration
The most significant barrier to any meaningful automation or AI implementation in a law firm is the abysmal state of its data. Most firms operate on a collection of siloed systems that were never designed to communicate. The Case Management System (CMS) doesn’t talk to the Document Management System (DMS), which doesn’t talk to the billing system. Data is trapped in proprietary formats, unstructured PDF documents, and free-text fields populated with inconsistent entries.
Trying to build an intelligent system on top of this foundation is like trying to build a skyscraper on a swamp. Before you can even think about AI, you have to drain the swamp. This involves the painful work of data cleansing, normalization, and migration. It means defining a canonical data model for core entities like matters, clients, and documents, then forcing every system to conform to it.
A common approach is to build a middleware layer, an internal API that acts as a universal translator between your legacy systems. This API exposes clean, consistent endpoints for core business objects. Instead of having your new automation tool connect directly to the sluggish, poorly documented CMS database, it communicates with your stable, well-defined middleware. This abstracts away the backend chaos and gives you a single point of control.
For example, a `GET /matters/{matter_id}` endpoint in your internal API should return a clean JSON object, regardless of how convoluted the data storage is in the backend.
{
"matterId": "MAT-2023-08-15-A",
"matterName": "Acquisition of TechCorp Inc.",
"client": {
"clientId": "CLI-101",
"clientName": "Global Innovations LLC"
},
"matterType": "Mergers & Acquisitions",
"status": "Active",
"keyDates": {
"opened": "2023-08-15T09:00:00Z",
"closingTarget": "2024-02-28T17:00:00Z"
},
"assignedAttorneys": [
{"userId": "j.smith", "role": "Partner"},
{"userId": "a.jones", "role": "Associate"}
]
}
Building this is not easy. It requires dedicated engineering resources. But it is the only path forward. Without this structured data foundation, any investment in AI is wasted.
Automation Is Just Explicit Logic
The term “automation” is often used as a catch-all for anything that reduces manual work. In a technical context, it refers to a specific sequence of triggers, actions, and conditional logic. It is not intelligent. It is a predefined workflow that executes when a specific condition is met. Think of it as a set of digital dominos.
A classic legal automation use case is client intake. A prospective client fills out a web form (the trigger). This action sends the form data to a workflow automation platform like Make or a custom script. The workflow then executes a series of steps:
- Data Validation: Logic-checks the input to ensure the email is a valid format and all required fields are filled.
- Conflict Check: Injects the prospective client’s name and related parties into the conflicts database via an API call.
- Conditional Logic: If the conflict check returns a hit, it routes the request to a compliance officer and sends the prospect a “pending review” email.
- Case Creation: If the conflict check is clear, it creates a new matter in the CMS, again via an API call.
- Document Generation: It populates a template engagement letter with the client’s data and saves it to the DMS.
- Notifications: It sends a Slack notification to the assigned attorney and an email to the client with the engagement letter attached.
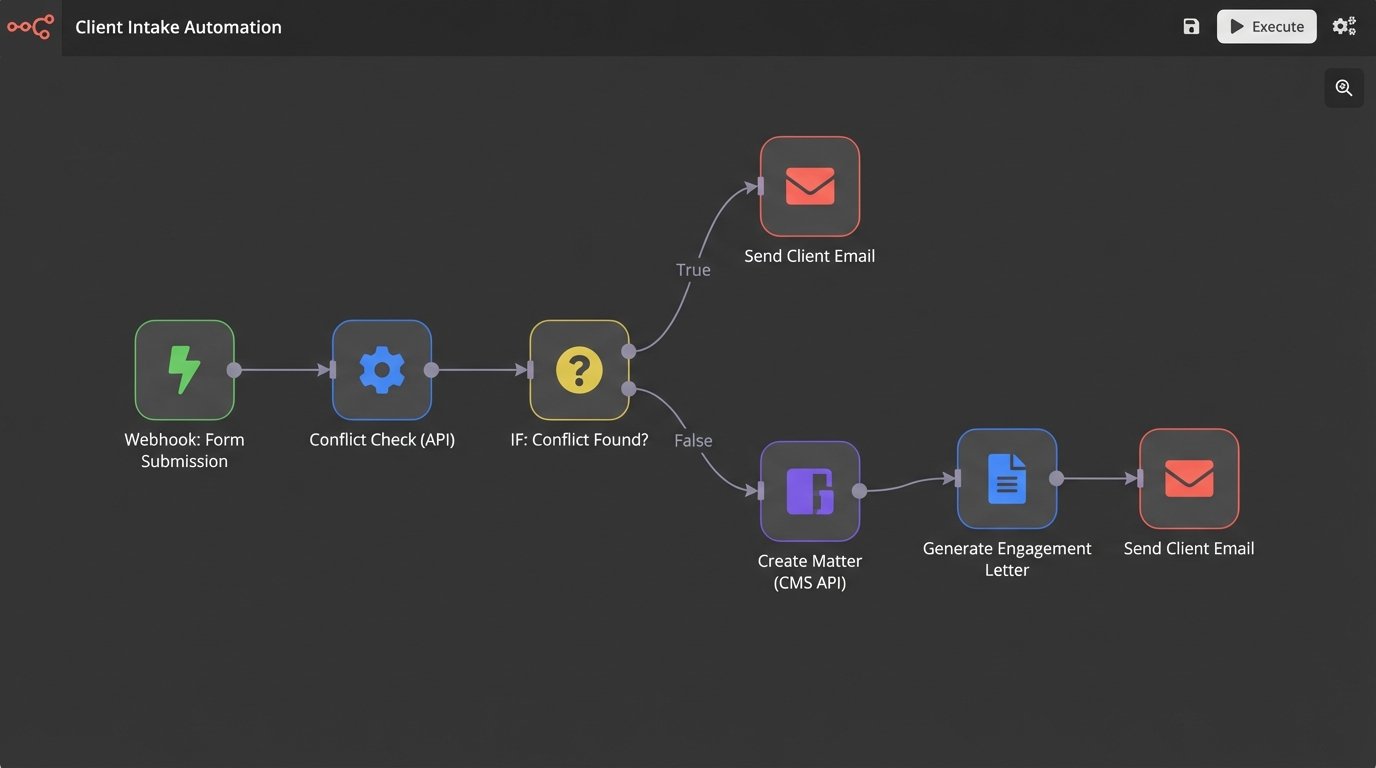
None of this requires AI. It requires well-defined processes and systems that can be controlled programmatically. The entire workflow is brittle. If the CMS API changes an endpoint or the conflict check system goes down, the automation breaks. The maintenance of these workflows is a significant, ongoing operational cost that is often ignored during the initial sales pitch.
Choosing the Right Tools
No-code platforms like Zapier or Make are excellent for simple, linear workflows that bridge common SaaS applications. They are fast to deploy but become cumbersome and expensive as logic complexity increases. Their polling-based triggers can introduce delays, which may not be acceptable for time-sensitive processes.
For more complex, business-critical automation, custom code is almost always the answer. A Python script running in a serverless function (like AWS Lambda) provides more control, better error handling, and direct integration with internal systems. It also requires a developer. This is the classic engineering speed vs. control calculation. A no-code tool gets you 80% of the way there in a day. The last 20% requires an engineer and takes two weeks.
The Necessary Adaptation for Lawyers
The takeaway for legal professionals is not that they need to become software developers. The critical skill is developing systems thinking. Lawyers must learn to deconstruct their own work into logical, repeatable processes. They need to be able to map a workflow on a whiteboard, identifying every decision point, every data input, and every required output. This is a form of architectural design.
The job is evolving from a service provider to a system manager. The value a senior lawyer provides will be less about drafting a standard document from scratch and more about designing and validating the automation that drafts that document. Their expertise is used to define the rules, set the quality control gates, and handle the exceptions that the automated system cannot. They become the “human in the loop,” the final arbiter of quality and strategy.
This requires a shift in mindset. It means viewing legal work not as a series of bespoke, artistic endeavors, but as a production system that can be optimized, measured, and improved. Forcing this level of process discipline into a profession that prides itself on individual judgment is a massive cultural challenge. It’s also the only way to stay relevant.
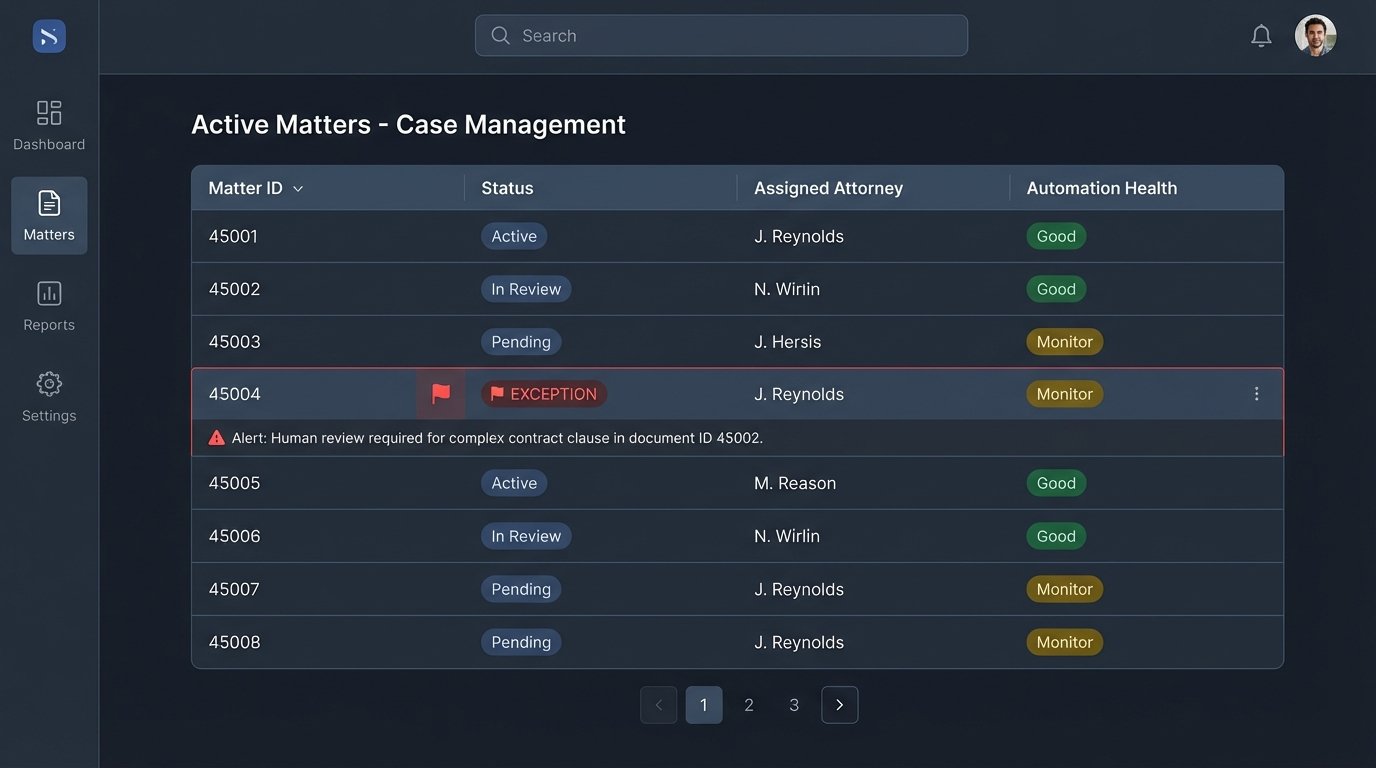
Firms that invest in the unsexy, foundational work of data structuring and process definition will be the ones that succeed. They will be able to plug in new technologies, including genuine AI, as they mature. Firms that continue to chase shiny objects without fixing their core operational rot will find themselves with a collection of expensive, underused tools and no real improvement in efficiency or quality.
The trend is not a technology. It is a discipline.