
The goal is not to replace a third-year associate redlining a 150-page Master Services Agreement. The goal is to stop them from doing it at 2 AM, fueled by caffeine and the fear of missing a critical indemnity clause buried in a sub-section. Automating contract review is an exercise in applied paranoia. It shifts the burden of low-level, repetitive pattern matching from a fatigued human brain to a deterministic system that never gets tired and never gets bored.
This is not about artificial intelligence in the cinematic sense. It is about brute-force data processing, logical validation against a known-good data set, and creating an audit trail that can withstand scrutiny. We trade the opaque risk of human error for the quantifiable, manageable risk of system configuration error. The latter is a far better problem to have.
Clause Extraction and Classification
The initial step in any automated review is to gut the document, stripping it down to its component clauses. This process typically starts with Optical Character Recognition (OCR) for scanned PDFs, a technology that is now a commodity but still introduces a non-zero error rate. Once you have machine-readable text, the system injects it into a pipeline for clause identification. Simpler systems rely on regular expressions to find keywords like “Limitation of Liability” or “Indemnification.”
This regex-based approach is fast and cheap but notoriously brittle. A slightly different phrasing or a typo in the source document can cause the pattern match to fail completely. More sophisticated platforms use Natural Language Processing (NLP) models, often fine-tuned on millions of existing legal documents, to classify entire paragraphs by their legal concept. This is more resilient to variations in language but introduces its own set of problems, namely performance bottlenecks and the “black box” nature of debugging a misclassification.
A hybrid approach is often the most practical. Use regex for high-certainty, boilerplate clauses and feed the rest to the NLP model. You always need a human-in-the-loop exception queue for anything the machine tags with low confidence. Forgetting this is how you end up with an automated system that quietly misfiles a critical termination clause.
Enforcing Playbook Consistency
Once clauses are extracted and classified, the real work begins. The system’s primary function is to logic-check each extracted clause against the firm’s pre-approved playbook language. This is not a subjective analysis of legal merit. It is a simple, binary comparison: does the text in the third-party document match one of the approved variations stored in our database? This comparison is often done using a string similarity algorithm, like Levenshtein distance, to flag minor deviations for review.
The value here is forcing standardization. Associates can no longer use a slightly modified indemnity clause they pulled from an old deal because they were in a hurry. The system acts as a gatekeeper, flagging any deviation from the golden source. Building this golden source is the single biggest upfront cost. It requires partners to agree on standard language, a process that can be politically charged and time-consuming. Mapping a thousand slightly different legacy limitation of liability clauses from past deals into a dozen standardized variations is like trying to force-fit mismatched plumbing parts. It’s a painful, one-time project that pays dividends for years.

The machine becomes a ruthless, unemotional enforcer of the standards your own lawyers agreed upon. It doesn’t care about client pressure or deadlines. It only compares text.
The Data Structure of a Playbook
A properly architected playbook is not a collection of Word documents. It is a structured database, often a simple key-value store or a relational database, where each clause is an object with associated metadata. This structure is critical for automation. A typical object might look something like this in JSON format:
{
"clauseId": "LOL-001",
"clauseType": "Limitation of Liability",
"playbookVersion": "2.1",
"language": {
"standard": "IN NO EVENT SHALL EITHER PARTY'S AGGREGATE LIABILITY...",
"fallbacks": [
{
"position": 1,
"text": "EXCEPT FOR BREACHES OF CONFIDENTIALITY OR INDEMNIFICATION OBLIGATIONS...",
"riskScore": 15
},
{
"position": 2,
"text": "LIABILITY SHALL BE CAPPED AT THE TOTAL FEES PAID IN THE PRECEDING 12 MONTHS...",
"riskScore": 5
}
]
},
"negotiationNotes": "Push for standard language. Fallback 2 is acceptable for deals under $50k.",
"lastUpdated": "2023-10-26T14:30:00Z"
}
This structure allows the system to not just identify a non-standard clause, but to suggest approved alternatives and provide context from the firm’s own negotiation history. It converts tribal knowledge into a queryable data asset.
Quantifiable Risk Scoring
Automation moves the conversation from a subjective “this feels risky” to a data-driven “this clause represents a risk score of 40.” By associating a numerical weight with every playbook deviation, you can generate an aggregate risk score for the entire agreement. A missing force majeure clause might add 5 points. An uncapped indemnity obligation could add 100 points. This forces a triage process based on data, not gut instinct.
This scoring can be dynamic. The system can be configured to make API calls to external services as part of its analysis. For instance, it can check the counterparty’s entity name against government sanctions lists or use a financial data provider to check their credit rating. This external data can then be used to modify the risk score. A high-risk clause from a financially unstable counterparty is a much bigger problem than the same clause from a Fortune 500 company.

This creates a consistent, defensible methodology for risk assessment. When a partner needs to approve a high-risk deviation, they are presented with a clear, numerical justification for why it requires their attention. It removes the ambiguity from the escalation process.
Building a Structured Data Layer for Analytics
The most significant long-term benefit of contract automation has nothing to do with speed or accuracy in a single review. It is the creation of a structured data repository. Every contract that passes through the system, whether it’s the initial third-party paper or the final executed version, is deconstructed into a structured data object. Clauses, metadata, negotiation history, and risk scores are stored in a database, not a flat file system of PDFs and DOCX files.
This data layer is the foundation for true legal analytics. You can begin to answer questions that were previously impossible to address systematically.
- What is our average time to close an MSA with a counterparty in the financial services sector?
- Which clauses does our most common counterparty consistently redline?
- Are we accepting more risk in Q4 deals to meet revenue targets?
- Which of our own lawyers most frequently deviates from the playbook?
Answering these questions allows a firm to move from a reactive posture to a proactive, data-informed strategy. You stop thinking about individual documents and start analyzing a dataset representing your entire portfolio of legal agreements. The process is no longer about just shoving a firehose of documents through a review pipeline; it’s about capturing every drop of data that comes out the other side.
System Limitations and Integration Headaches
These systems are not a magic fix. They are expensive, both in licensing fees and the internal man-hours required for configuration. The initial setup, which involves codifying your legal playbook and training the classification models on your specific document types, is a significant project that can take months. The system is only as good as the playbook data you feed it. Garbage in, garbage out.
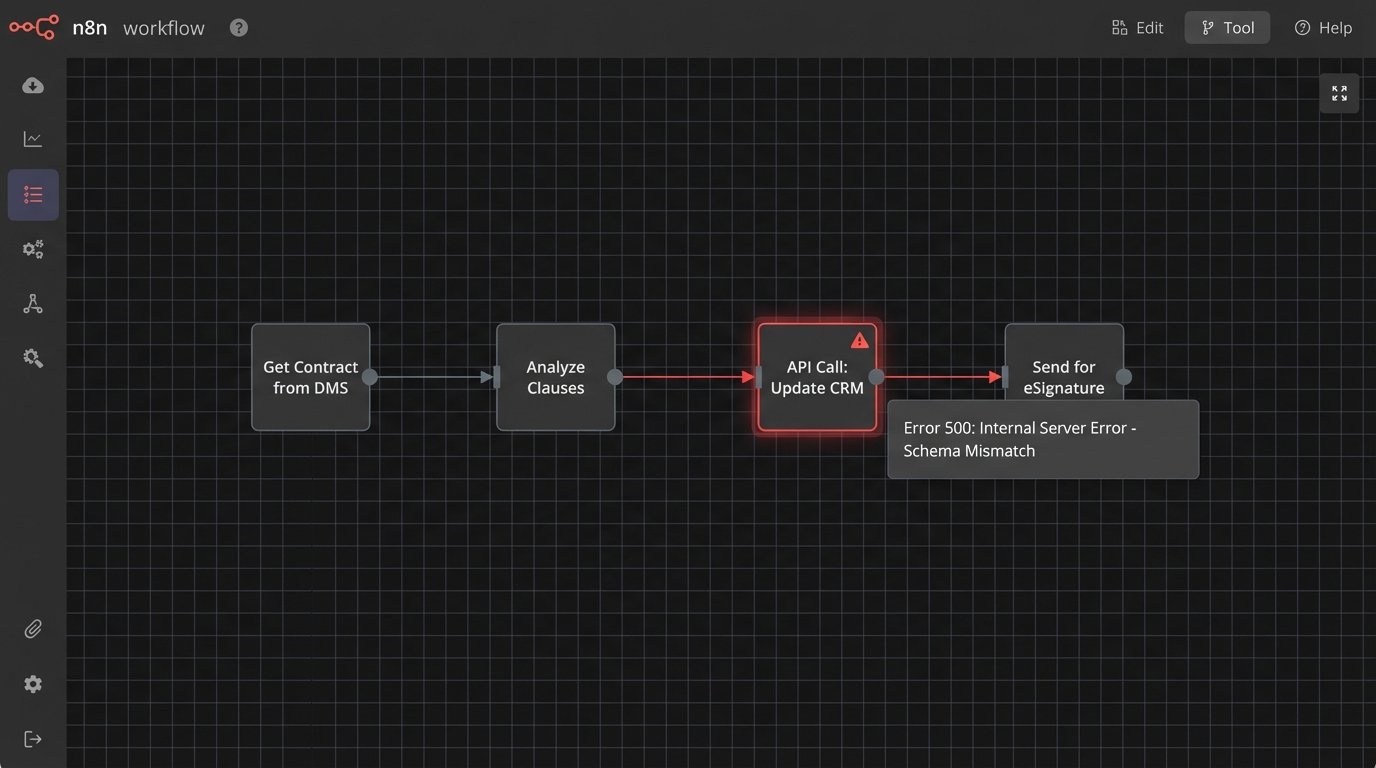
Integration is another persistent source of failure. Getting the contract review platform to communicate reliably with your document management system (DMS), customer relationship management (CRM), and e-signature platform is a constant battle. You will be dealing with poorly documented REST APIs, authentication token expirations, and data schema mismatches that cause workflows to fail silently in the middle of the night.
Finally, there is the problem of over-reliance. If lawyers begin to trust the system blindly without performing their own sanity checks, the automation creates a new single point of failure. The system is a tool to augment human expertise, not replace it. It should handle the 80% of repetitive, low-value work, freeing up lawyers to focus on the 20% of high-risk, nuanced issues that require genuine legal judgment. Forgetting that distinction is the fastest way to turn a powerful tool into a dangerous liability.