
The debate between manual and automated contract review is framed incorrectly. It’s presented as a simple choice between a seasoned lawyer with a red pen and a magical AI that spits out perfect redlines. This is a fantasy peddled by sales teams. The real discussion is about surgical augmentation, not wholesale replacement. The core problem isn’t speed. It’s managing the entropy of unstructured data and forcing consistency where human fatigue guarantees failure.
Forget the marketing demos. Let’s talk about production environments where the rubber meets the road, and the road is a potholed mess of scanned PDFs and legacy data formats.
The Mechanical Truth of Manual Review
Manual review is a known quantity. We understand its failure modes because we’ve lived them. At its core, it’s a human-driven pattern-matching exercise. A lawyer loads a document, activates their internal mental model of risk, and begins scanning for deviations from that model. They hunt for missing clauses, non-standard language in indemnification, or suspiciously broad IP assignment terms. This process relies entirely on the individual’s memory, attention span, and experience.
The workflow is brutal. It involves constant context switching between the document, the playbook, email, and the case management system. Each switch is a potential entry point for error. The primary tool is often just Ctrl+F, a blunt instrument for a task requiring surgical precision. The process is slow, expensive, and produces inconsistent output from one reviewer to the next, or even from the same reviewer on a Monday morning versus a Friday afternoon.
This isn’t an intellectual exercise. It’s a high-stakes data processing task performed on a biological machine prone to exhaustion.
Failure Points in the Human Process
The weak link is cognitive load. After reviewing the fifth 50-page MSA of the day, the brain’s ability to spot a subtle but critical change in the governing law clause diminishes significantly. Key details get missed not because of incompetence, but because of the sheer volume and repetition. Institutional knowledge is another massive vulnerability. When a senior lawyer leaves, their finely tuned risk models and negotiation history walk out the door with them. What remains is a collection of Word documents on a shared drive with cryptic filenames like `MSA_template_final_v3_USE_THIS_ONE.docx`.
We try to mitigate this with checklists and playbooks, but these are static documents. They require the human processor to actively pull information, interpret it correctly, and apply it without deviation. It’s an analog control system in a digital world, and it’s fundamentally leaky. The output is a patchwork of individual interpretations, not a standardized, auditable data product.
Deconstructing the “Automation” Black Box
When vendors say “AI-powered contract review,” they are describing a pipeline of different technologies, each with its own limitations. The first step is usually Optical Character Recognition (OCR) to convert a scanned image into machine-readable text. This is a probabilistic process, not a perfect conversion. It guesses at characters, and it frequently guesses wrong, turning “indemnify” into “indemnify” with a weird ligature or “party” into “pacty.” These small errors can derail the subsequent stages.
Once you have text, the next stage involves Natural Language Processing (NLP) models. These are typically some form of Named Entity Recognition (NER) to find and categorize things like “Effective Date,” “Parties,” and “Termination for Convenience.” Clause classification models then attempt to tag entire paragraphs, identifying them as “Limitation of Liability” or “Confidentiality.” Finally, a risk-scoring algorithm, often a simple set of weighted rules, flags deviations from a predefined standard.
It sounds clean. It’s anything but.
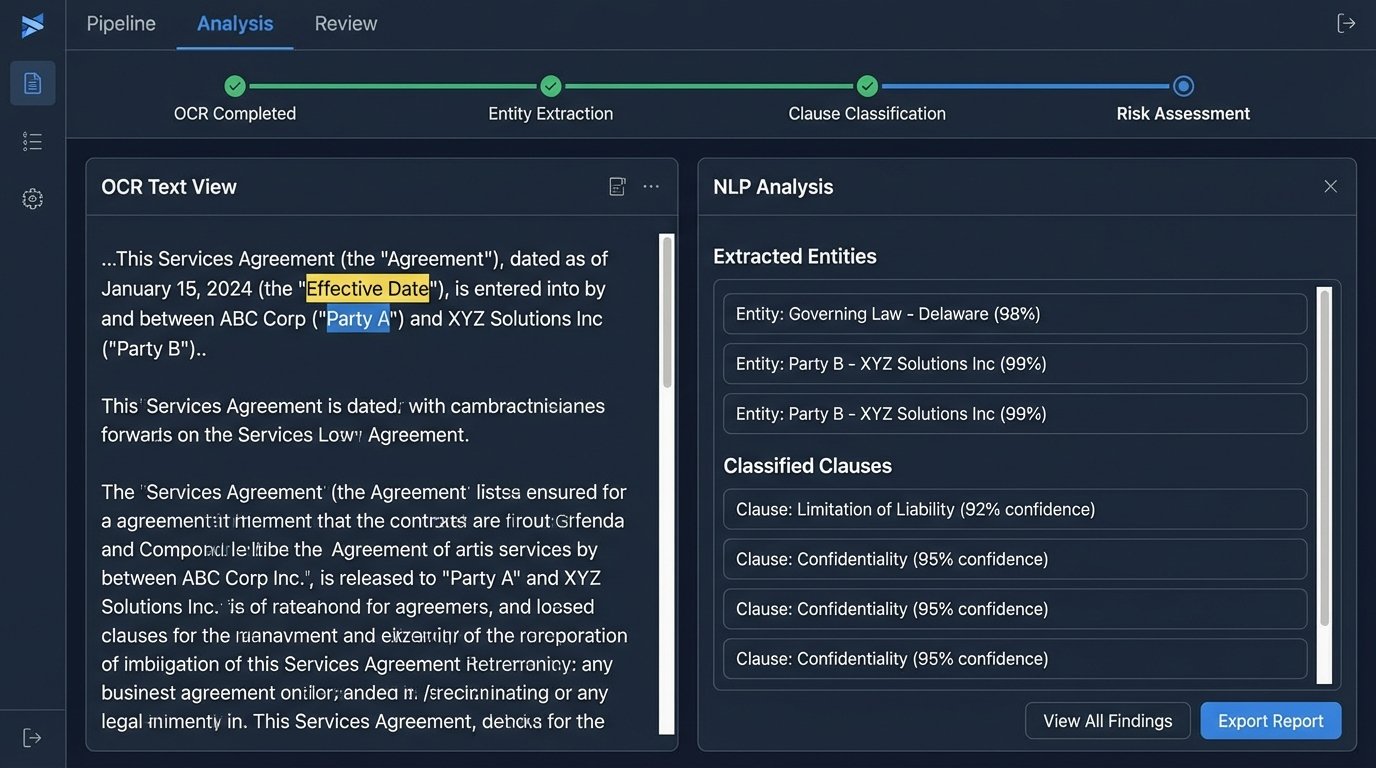
The Garbage-In, Garbage-Out Reality
Every model in that pipeline is trained on a specific dataset. If the vendor trained their model primarily on SaaS agreements, it will perform poorly on real estate leases or complex M&A documents. The model doesn’t understand legal concepts. It understands statistical relationships between words and phrases based on the data it was fed. It’s a sophisticated pattern-matcher, but it has no real-world context or ability to reason about novel language.
This leads to silent failures. The system might correctly identify 95% of liability clauses but completely miss a new, creatively worded one because it doesn’t match the patterns it knows. It won’t throw an error. It will simply fail to flag a high-risk term, giving a false sense of security. The black-box nature of many of these systems makes it impossible to debug why it missed something. You are left trusting a system whose decision-making process is opaque.
The idea of feeding a 20-year archive of poorly scanned, unstructured contracts into one of these systems and expecting clean data is an engineering fantasy. It’s like trying to shove a firehose of muddy water through a needle and hoping for a sterile stream on the other side. You don’t get analysis. You get noise.
Here’s a trivial example of what happens when you try to programmatically pull text from a poorly formatted PDF. The structure is lost, and what looks clean to the eye is a mess for a script.
import PyPDF2
def extract_text_from_pdf(pdf_path):
try:
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
text += page_text
# The output is often a jumbled mess of text blocks
# with lost line breaks and spacing.
print(text.replace('\\n', ' '))
except Exception as e:
print(f"Failed to process PDF: {e}")
# Assume 'scanned_contract.pdf' is a low-quality scan.
# The output will be far from clean, structured text.
# extract_text_from_pdf('scanned_contract.pdf')
The code looks simple, but the output from a scanned document is often unusable without a significant, and expensive, cleanup stage.
A Pragmatic Architecture: The Hybrid Model
The only viable path forward is not full automation, but a human-in-the-loop system designed for specific, narrow tasks. The goal is to offload the repetitive, low-cognition work from the lawyer, freeing them up to focus on high-level risk analysis and negotiation strategy. This means breaking the review process down into discrete, machine-solvable problems.
A functional architecture treats automation as a triage and data extraction tool, not a decision-making one.
Step 1: Automated Triage and First-Pass Filtering
The first job for automation is to sort the pile. You can build simple, high-confidence routines to handle this. For example, a script can ingest an agreement and check for the mere presence or absence of critical clauses based on keyword or regex matching. Does the document contain the phrase “Limitation of Liability” at all? If not, flag it for immediate human review. Does it use your company’s standard paper or the counterparty’s? This is a simple binary classification that can route contracts to the right teams without any deep analysis.
This stage isn’t about understanding the nuance of the clause. It’s about confirming its existence. This is a low-risk, high-value task that immediately segments high-risk documents from low-risk ones and saves immense human time.
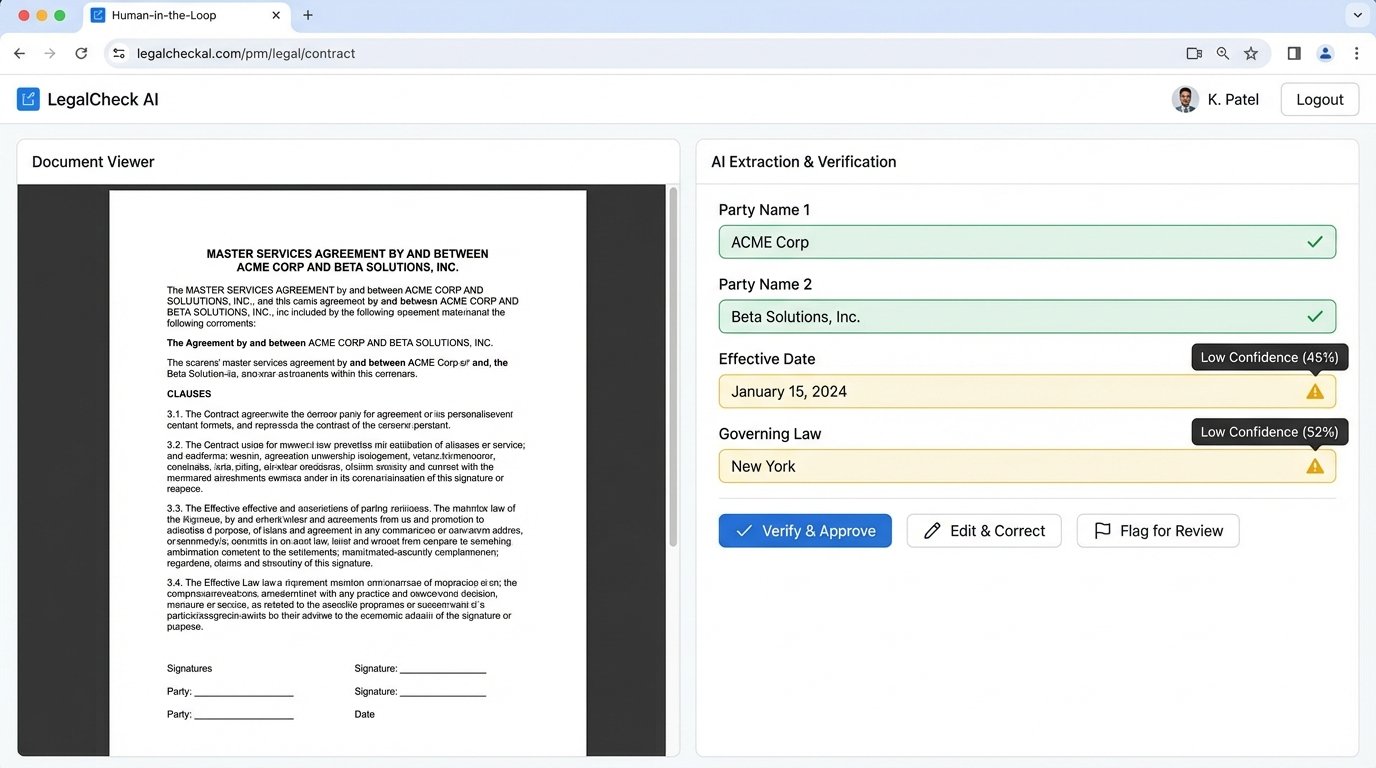
Step 2: Structured Data Extraction, Human Verification
The next task is to turn blobs of text into structured data. Use NER models to pull out key-value pairs: Party Names, Effective Date, Governing Law, Notice Period. The output of this process should not be fed directly into a database. It should be presented to a human reviewer in a side-by-side interface. On the left is the source document. On the right are the extracted data fields.
The human’s job shifts from hunting for information to verifying it. This is a fundamentally faster and less cognitively draining task. The machine does the tedious work of locating the data points, and the human provides the critical final logic-check. This `verify, don’t search` workflow is the core of an effective hybrid model.
The Integration and Cost Reality
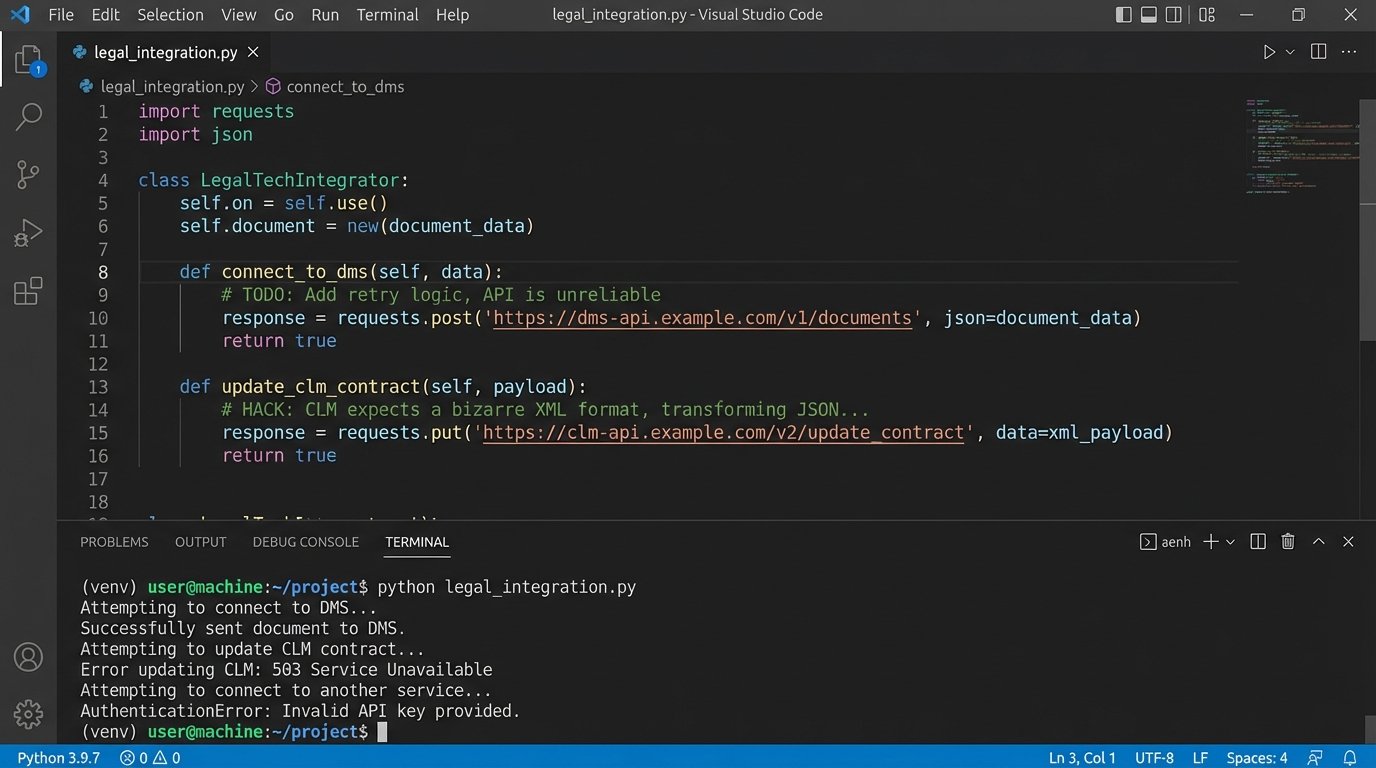
Buying a license for a contract review platform is the first, and cheapest, step. The real cost is in the integration. These tools do not work in a vacuum. They need to be connected to your Document Management System (DMS), your CLM, your e-signature platform, and your single sign-on provider. This is where projects go to die.
Your DMS probably has a clunky, poorly documented REST API with strict rate limits. The CLM was built a decade ago and expects data in a bizarre XML format. You will spend hundreds of engineering hours building brittle, custom connectors to bridge these systems. You will need to write scripts to handle authentication, data transformation, error logging, and retry logic. This is not a plug-and-play operation. It’s a full-blown systems integration project.
The subscription fee is a rounding error. The real wallet-drainer is the team of engineers you’ll need to force these disparate systems to talk to each other without losing data.
Measuring What Actually Matters
Finally, you must resist the temptation to measure success with vanity metrics like “contracts reviewed per hour” or “time saved.” These are vague, impossible to prove, and easily gamed. Instead, focus on concrete, auditable KPIs that directly map to risk reduction and operational efficiency.
Track the reduction in the cycle time from contract ingestion to the first redline being sent to the counterparty. Measure the adoption rate of playbook-approved clauses in executed agreements. A successful implementation will show a quantifiable increase in the use of standard language. Most importantly, track the decrease in executed agreements containing unacceptable risk positions, such as unlimited liability or non-standard data privacy terms.
These are not marketing metrics. They are hard, operational data points that prove the system is forcing compliance and reducing tangible risk. Anything else is just noise. The goal is not to review contracts faster. It’s to execute better contracts, consistently.