
Most contract review automation projects quietly stall. They don’t crash in a spectacular fireball of failed API calls. They degrade into expensive, manual validation engines with a fancy UI, forcing paralegals to double-check every “automated” extraction. The core failure is not the technology, but a fundamental misunderstanding of the engineering problem: contracts are not standardized data packets. They are chaotic, negotiated artifacts.
Building a system that can reliably gut a contract for key data requires dodging a series of common, and often expensive, mistakes. This is not about picking the right vendor. It is about architectural discipline.
Mistake 1: The Uniformity Fallacy
The first trap is assuming that all contracts of a certain type, like a Master Services Agreement (MSA), follow a predictable structure. Engineers new to legal tech often try to build rigid templates or parsers that look for specific clause headings like “Term” or “Limitation of Liability.” This approach shatters the moment it encounters a contract drafted by a different firm, which might label the termination clause “Term and Termination” or simply embed the term length within the introductory paragraph.
A system built on exact string matching for clause titles is brittle. It creates a maintenance nightmare, requiring a new template for every minor variation. The correct approach is to build a system that logic-checks for concepts, not just headers. This involves using pattern recognition, proximity analysis, and semantic search to locate the substantive legal language, irrespective of its heading.
Consider this naive approach to finding the governing law clause:
def find_governing_law_naive(text):
lines = text.split('\n')
for i, line in enumerate(lines):
if "governing law" in line.lower():
# Assumes the state is in the next few lines
return lines[i:i+3]
return "Clause not found"
This code fails constantly. A more resilient function would search for keywords like “laws of the state of” or “governed by and construed in accordance with” and then use named entity recognition (NER) to extract the specific state or jurisdiction mentioned nearby.
Building for Variance
Your parsing engine must be designed to handle structural ambiguity. Instead of a rigid, top-down parser, think in terms of an agent-based system where small, specialized functions hunt for specific pieces of data. One agent looks for party names near the document’s start. Another looks for currency symbols and payment terms. A third hunts for termination conditions. These agents run in parallel, and their findings are pieced together later. This modular architecture is far more resilient to the organised chaos of legal documents than any monolithic template.
It’s slower, but it works.
Mistake 2: Ignoring Input Data Quality
The most sophisticated NLP model is useless if you feed it garbage. Contract automation doesn’t start with AI, it starts with a brutal pre-processing pipeline to sanitize incoming documents. A significant portion of contracts arrive as poorly scanned PDFs, complete with coffee stains, skewed text, and handwritten notes. Running OCR on these documents directly produces a text file filled with artifacts and character recognition errors that will choke any extraction algorithm.
A production-grade ingestion pipeline must include several stages:
- Image Enhancement: Deskewing the document image, removing background noise, and increasing contrast before OCR is run.
- Layout Analysis: Identifying headers, footers, tables, and columns to avoid mixing metadata with the core contract body. A failure here might cause your system to interpret a page number as a contract value.
- Artifact Stripping: Programmatically removing common OCR errors, stray characters, and formatting junk from the raw text output.
Bypassing this stage to save time is the definition of false economy. You will pay for it tenfold in debugging hours and manual correction. A system’s reliability is capped by the quality of its input data. No exceptions.
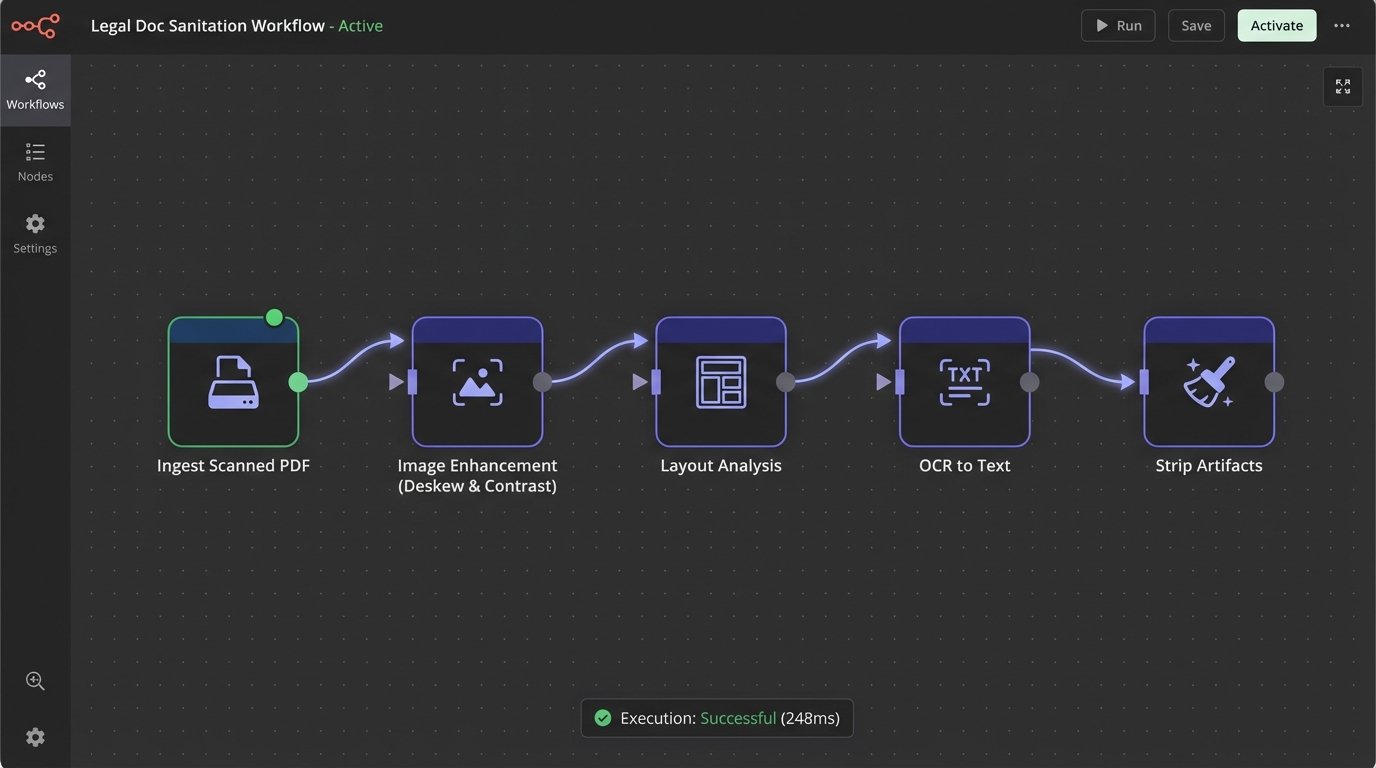
The image above illustrates a basic sanitation workflow. Each stage catches and corrects errors that would otherwise poison the downstream extraction models. Forcing this discipline at the point of ingestion prevents a cascade of failures later.
Mistake 3: Blind Faith in Off-the-Shelf AI
Vendors selling “AI-powered” contract analysis often present their models as black boxes. You send a document to their API, and a JSON object with extracted fields comes back. This is fine for a demo, but it’s a massive liability in production. When an extraction fails or returns an incorrect value, you have no visibility into *why*. You cannot debug the model’s internal logic, you cannot retrain it on your specific contract types, and you are entirely dependent on the vendor’s development cycle to fix issues.
A hybrid approach is superior. Use pre-trained language models for broad tasks like clause classification, where they excel at understanding semantic context. But for extracting specific, high-stakes data points like renewal dates or liability caps, supplement the AI with rule-based logic. Regular expressions and dependency parsing are not glamorous, but they are predictable, auditable, and easy to debug when they break.
A simple fallback mechanism can inject this predictability:
import spacy
# Load a pre-trained NLP model
nlp = spacy.load("en_core_web_sm")
def get_renewal_date(text):
"""
Hybrid function to find the renewal date.
First, try a rule-based regex pattern. If it fails, use a more general NER model.
"""
# High-precision regex for "renews on MM/DD/YYYY"
rule_based_result = find_date_with_regex(text)
if rule_based_result:
return {"value": rule_based_result, "method": "regex"}
# Fallback to a general purpose NER model
doc = nlp(text)
for ent in doc.ents:
if ent.label_ == "DATE" and "renew" in ent.sent.text.lower():
return {"value": ent.text, "method": "ner"}
return {"value": None, "method": "not_found"}
This hybrid function prioritizes a high-precision, easily understood method (regex) and only falls back to the more opaque neural model if the first pass fails. This gives you control and a clear audit trail for each piece of extracted data.
Your job is to build a reliable system, not just to use the latest AI model. Control is everything.
Mistake 4: Decoupling Automation from the Human Reviewer
The goal of contract automation is not to eliminate lawyers but to augment them. Building a system that dumps extracted data into a database without a clear validation workflow for a human is a recipe for disaster. No model is 100% accurate. The system must be architected around the assumption of failure and provide a seamless way for a human to catch and correct those failures.
Every piece of data extracted by the system should have a confidence score attached. This score is not just a statistical measure from the model. It should be a composite score that factors in the extraction method (a regex match is higher confidence than a broad semantic search), the quality of the source document (lower OCR confidence means lower data confidence), and historical performance.
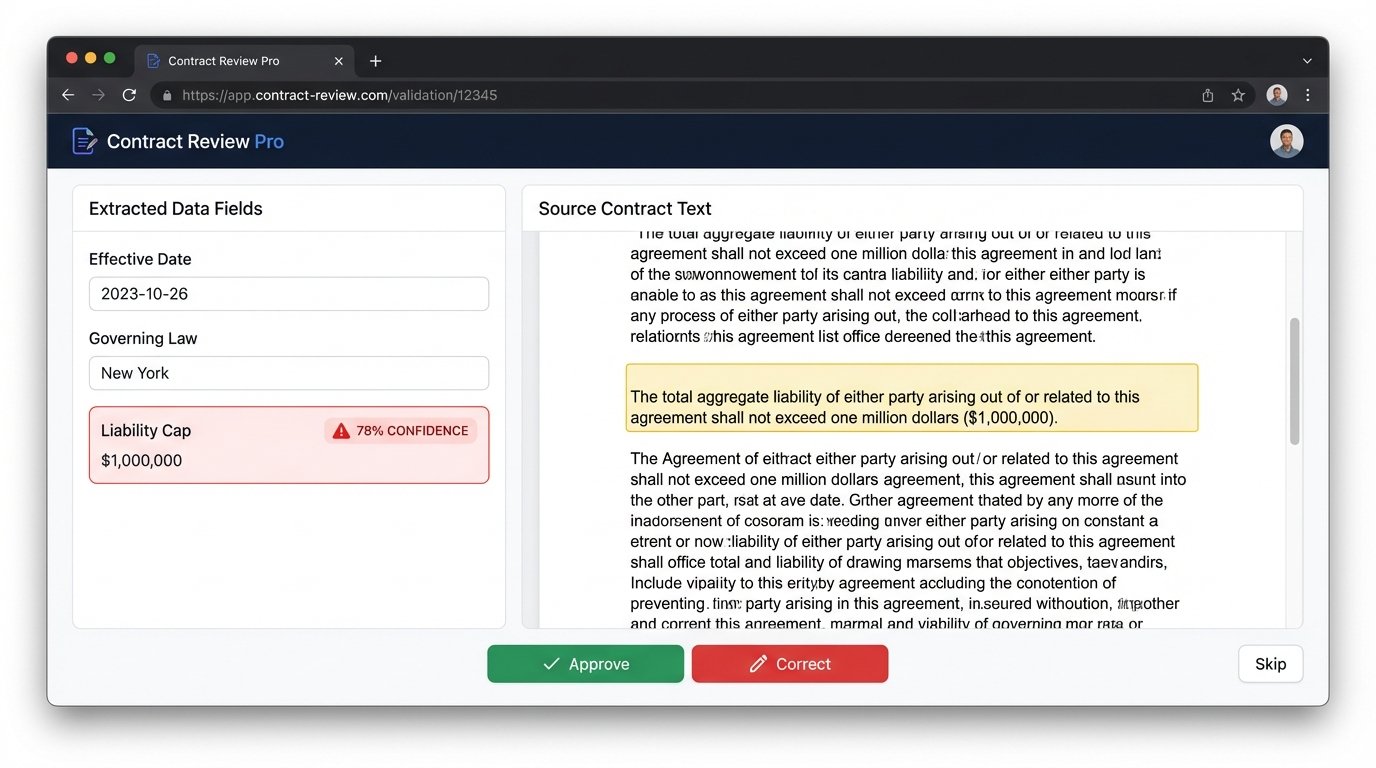
Data points with a confidence score below a certain threshold (e.g., 90%) must be automatically flagged and routed to a human reviewer. The user interface for this review process is critical. It must show the extracted value, the source text from the original document with the relevant passage highlighted, and the confidence score. The reviewer should be able to accept the value with a single click or type in a correction. This is the human-in-the-loop (HITL) process, and it’s non-negotiable for any serious implementation.
This feedback loop does more than just correct errors. The corrections themselves become the most valuable training data you have. They are a clean, curated dataset of your model’s failures, which can be used to fine-tune the models and improve their accuracy over time. An automation system without a HITL workflow is a dead-end street.
Mistake 5: Neglecting Downstream System Integration
Extracting data is only half the battle. That data is useless unless it is correctly injected into the firm’s other systems of record, such as a Contract Lifecycle Management (CLM) or matter management platform. This is where many projects get bogged down in a mire of brittle, poorly documented APIs.
Before writing a single line of extraction code, you must map the data schema of the target system. What is the exact field name for “Contract Expiration Date” in the CLM? Is it a `DATE` type or a `DATETIME` type? Does the system expect `MM/DD/YYYY` or an ISO 8601 format? A mismatch in these simple details will cause data synchronization to fail silently or, worse, corrupt the records in the target system.
The output of your extraction pipeline should be a clean, standardized JSON object. Do not just pass the raw output from a model. Your code must sanitize, format, and validate every value before attempting to send it to another system.
A clean payload is structured and predictable:
{
"contract_id": "MSA-2023-45B",
"document_hash": "a1b2c3d4e5f6...",
"parties": [
{"name": "Global Tech Inc.", "role": "Provider"},
{"name": "Client Solutions LLC", "role": "Client"}
],
"effective_date": "2023-10-01",
"term_months": 36,
"governing_law": "Delaware",
"liability_cap": {
"value": 2000000,
"currency": "USD"
},
"extraction_metadata": {
"confidence_score": 0.94,
"model_version": "v2.1.4"
}
}
This structure is self-documenting. It enforces data types and provides metadata for auditing. Trying to push a messy, unstructured dictionary of values into a CLM API is like shoving a firehose through a needle. It requires meticulous data mapping and robust error handling to manage API rate limits, authentication failures, and validation errors.
Mistake 6: Treating the System as a One-Time Build
Legal language is not static. Business practices change, new regulations are passed, and your firm starts using new types of agreements. A model trained on last year’s contracts will slowly become less accurate over time. This phenomenon, known as model drift, will silently degrade the performance of your entire system if you are not actively monitoring it.
An automation platform is not a project you complete. It is a system you maintain. This requires a dedicated feedback and retraining pipeline. Every human correction made during the validation step must be logged. Periodically, this logged data of “ground truth” corrections should be used to retrain and fine-tune your extraction models.
You must also implement ongoing monitoring. Track key performance indicators like the average confidence score, the percentage of extractions flagged for human review, and the straight-through processing rate (the percentage of documents processed with no human intervention). A gradual decline in these metrics is a clear signal that your models are drifting and need to be updated.
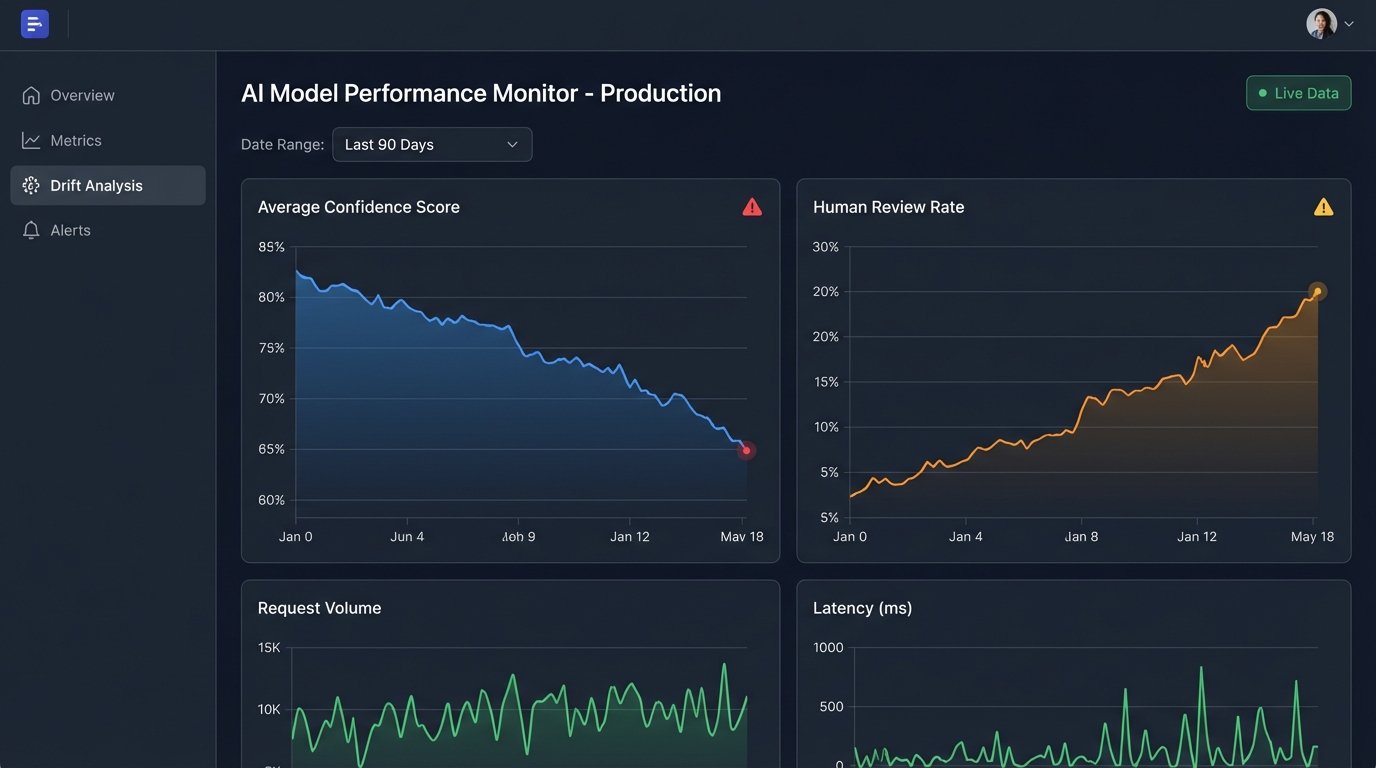
Failing to budget time and resources for this continuous maintenance cycle is a critical strategic error. An unmaintained automation system becomes legacy software the day it launches. Its value decays over time until it becomes more trouble than it’s worth, and the entire expensive project is eventually abandoned. Build for evolution, not for a static endpoint.