
The average Non-Disclosure Agreement took our junior associates 55 minutes to draft. Forty of those minutes were spent copying client data from Salesforce, pasting it into a Word template, and manually deleting inapplicable clauses. This process produced an average of three substantive errors per week that required partner-level intervention, burning high-cost hours on work that should have been mechanical. The manual process was not just inefficient; it was a consistent source of risk and a drain on our most expensive resources.
Deconstructing the Failure Points
Our legacy workflow was a textbook example of process debt. It relied on a series of Word documents stored on a shared drive, with naming conventions like “NDA_Template_FINAL_v2_use_this_one.docx.” Version control was non-existent. An associate would open the supposed master template, save a new copy, and then begin the painstaking task of finding and replacing placeholder text like “[PARTY A NAME]” and “[EFFECTIVE DATE]”.
The primary points of failure were predictable:
- Data Entry Errors: Manual transcription of entity names, addresses, and signatory details from our CRM was the leading cause of mistakes. A typo in a legal name could invalidate the entire agreement.
- Clause Selection Logic: Associates had to follow a separate PDF guide to decide which clauses to include or exclude based on jurisdiction or the nature of the confidential information. Forgetting to remove a clause specific to EU data protection for a purely domestic agreement was a common and embarrassing error.
- Formatting Inconsistencies: Copying and pasting text often broke the document’s formatting, leading to unprofessional-looking final drafts that required extra time to fix. Numbering, indentation, and font styles would drift with each new iteration.
This system turned bright, expensive legal talent into glorified typists. The cost was not just in their wasted time but also in the partner hours spent correcting their low-level mistakes. The situation was untenable.
Architectural Approach: A Pragmatic Stack
We evaluated several document automation platforms. The decision came down to a direct conflict between modern, cloud-first solutions and our firm’s dependency on an ancient, on-premise case management system (CMS). The CMS had a barely documented SOAP API that most SaaS platforms refused to touch. We needed a tool that could live on our servers and speak the same archaic language as our core infrastructure.
We selected a platform known for its robust on-premise deployment options and a flexible API, even if its user interface was less polished than its cloud-native competitors. The choice was not about finding the “best” tool on the market, but the right tool for our specific, technically constrained environment. The solution required three core components: a web-based intake form for data collection, the document generation engine itself, and a connector module to bridge the gap between our CRM and the engine.
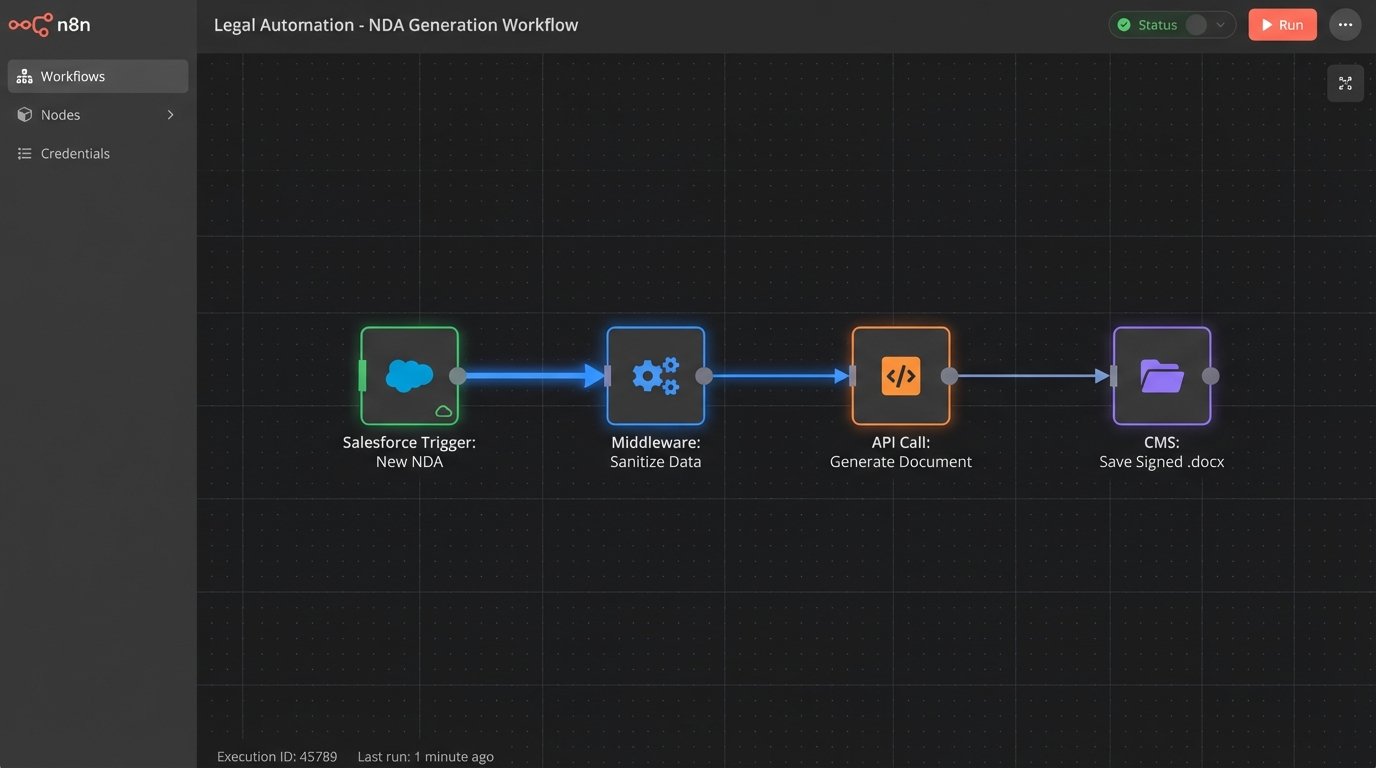
The architecture was straightforward. A paralegal or associate initiates the process from a custom button within the Salesforce Opportunity record. This action triggers a call to our middleware, which pulls key data points like party names, addresses, and deal type. The data pre-populates a secure web form. The user then answers a series of conditional questions that dictate the contract’s structure. Once submitted, the form data, packaged as a JSON object, is posted to the document generation engine’s API endpoint. The engine merges the data with the correct template and returns a .docx file, which is then automatically saved back to the relevant record in our CMS.
This closed-loop system was designed to eliminate manual data entry and enforce logical consistency. It also provided a clear audit trail, logging who created which document and with what input data.
Building the Logic Core
The heart of the project was translating our firm’s paper-based drafting guide into a machine-readable logic tree. We started with the Mutual NDA, our most frequent and standardized agreement. We broke the document down into static boilerplate and dynamic components. The dynamic parts were clauses that could change based on specific inputs from the intake form.
For example, the choice of governing law was not a simple text field. It was a dropdown menu that, when a user selected “California,” would automatically insert a specific waiver of Civil Code Section 1542. If the user selected “New York,” a different clause regarding jury trial waivers was injected. This was handled with simple conditional logic within the template itself.
Trying to pull unstructured data from emails or notes fields directly into template variables was a non-starter. It’s like shoving a firehose through a needle. You need a rigid intake form to structure the data correctly before it ever hits the generation engine. The form forces discipline and data hygiene, which was a massive secondary benefit.
The data structure we passed to the API was lean and specific. We stripped out any information not directly required for the document to keep the payload small and the process fast. A typical JSON request body for an NDA looked like this:
{
"templateID": "NDA_Mutual_v3.1",
"caseRef": "SF-004815",
"partyA": {
"legalName": "Global Tech Innovations Inc.",
"jurisdiction": "Delaware",
"address": "100 Market Street, San Francisco, CA 94105"
},
"partyB": {
"legalName": "Secure Data Solutions LLC",
"jurisdiction": "Nevada",
"address": "3500 Las Vegas Blvd, Las Vegas, NV 89109"
},
"termInMonths": 36,
"governingLawState": "New York",
"includeArbitrationClause": true
}
This clean, predictable structure was the key. The template engine knew exactly what to expect, eliminating the ambiguity that plagued the manual process.
Implementation Hurdles and Fixes
The initial deployment was not smooth. The first major problem surfaced during user acceptance testing. Our data in Salesforce was a mess. The “State” field for client addresses sometimes contained “CA,” other times “Calif.,” and occasionally “California.” Our logic, which expected a standardized two-letter abbreviation, broke repeatedly. The jurisdiction clause defaulted to the wrong state or failed to appear at all.
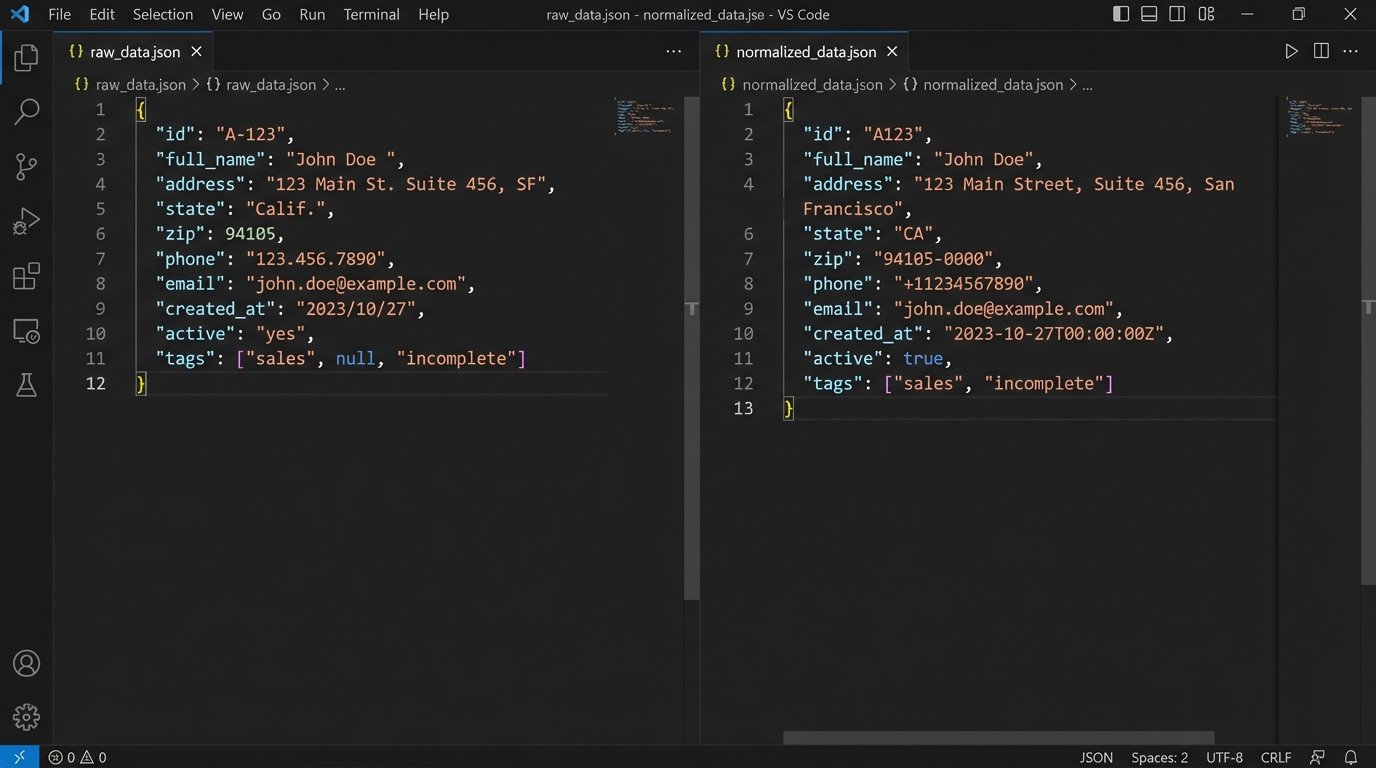
The fix was a two-pronged attack. First, we implemented stricter validation rules on the Salesforce side to enforce data consistency moving forward. Second, we built a data normalization layer in our middleware. This script intercepted the data from Salesforce, cleaned it up by mapping variations to a standard format, and only then passed the sanitized JSON to the document engine. It was an extra layer of complexity we hadn’t planned for, but it was necessary to make the system resilient to years of inconsistent data entry.
Another issue arose from edge cases. Our initial logic assumed both parties were standard corporations. The first time a partner tried to generate an NDA with a trust as one of the parties, the system failed because the signature block logic was hardcoded for a “Title” field (e.g., CEO, President) that doesn’t exist for a trust. We had to refactor the template logic to accommodate different entity types, adding a new question to the intake form to identify the party structure upfront and render the correct signature block dynamically.
The Human-in-the-Loop Validation
We deliberately did not build a fully autonomous system. The goal was to augment our lawyers, not replace their judgment. The automation generates a first draft, not a final, client-ready document. The output is a fully-formatted Word document, not a locked PDF, allowing for final review and modification.
The system also includes a flagging mechanism. If the user selects a combination of options that represents a significant deviation from our standard terms, such as an unusually long term or the exclusion of the arbitration clause, the system attaches a warning note to the record in our CMS. It also routes the document to a mid-level associate for review instead of directly to the paralegal who initiated it. This ensures that a qualified lawyer examines any non-standard agreement before it proceeds.
This final review step is critical. It preserves the necessary layer of professional oversight while still eliminating 90% of the manual labor. It strikes a balance between pure automation and the practical realities of legal risk management.
Quantifiable Results and Second-Order Effects
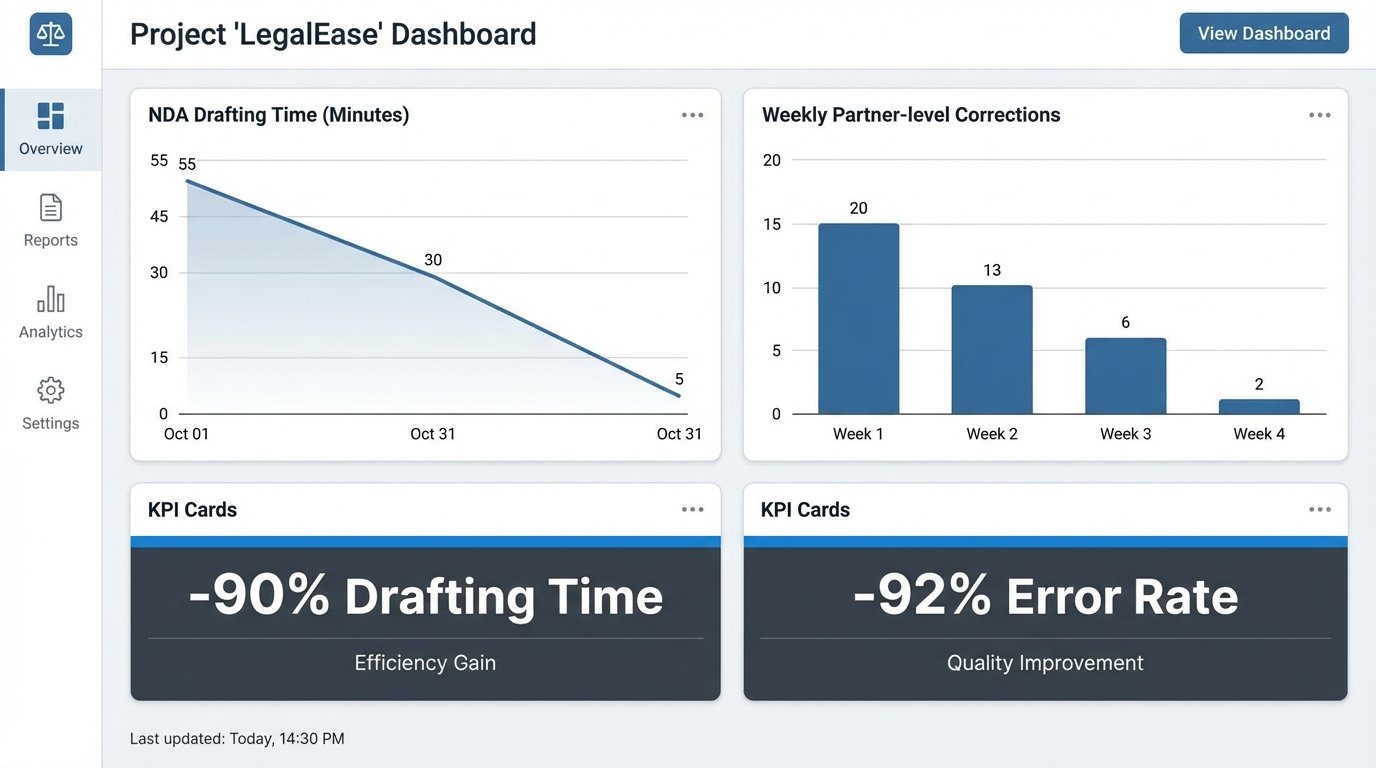
The numbers speak for themselves. After a three-month stabilization period, we measured the impact across the commercial law practice group.
- Drafting Time: The average time to generate a first-draft NDA dropped from 55 minutes to 5 minutes. This represents a 90% reduction in direct labor for this task.
- Error Rate: Data-entry and clause-selection errors that required partner review fell from an average of three per week to less than one per month. This was a 92% reduction in costly rework.
- Partner Review Time: Because the drafts were more consistent and reliable, the time partners spent reviewing them was cut in half. They could focus on the substantive legal points, not on catching typos.
The total project cost, including software licensing and our internal development time, was recouped in just under seven months through the reclaimed associate and partner hours. But the benefits went beyond the raw numbers. Junior associates were freed from mind-numbing clerical work and could be assigned to more valuable tasks like legal research and due diligence support. Their job satisfaction improved measurably.
An unexpected benefit was the project’s effect on our data quality. Because the automation required clean, standardized data from Salesforce to function, it forced the entire team to be more disciplined about data entry. The project acted as a catalyst for improving data hygiene across the firm, which has had positive downstream effects on our marketing and business intelligence efforts.
The system isn’t perfect. It requires ongoing maintenance to update clauses as laws change and to add new templates. But it has fundamentally altered the economics of producing our most common legal documents. It successfully converted a high-risk, low-value manual task into a low-risk, high-efficiency automated workflow.