
Most attempts at contract automation fail because they start with the document. They fixate on the Word template, the fonts, and the clause library. This is a foundational error. Effective automation begins with the data model. Without a rigid, well-defined data structure, you are not automating, you are just building a more complicated mail merge that will break under the slightest pressure.
The core problem is treating contract data as a flat list of variables. A counterparty name, an effective date, a contract value. This approach ignores the relational nature of legal agreements. Your system must understand that a “Party” is an object with properties like `name`, `address`, `entityType`, and `signer`, not just a text string you inject into a placeholder. A weak data model guarantees a brittle system.
Dissecting the Data Model First
Before you write a single line of template code, you must define the data schema. This is the non-negotiable prerequisite. The schema acts as a contract between your data source (intake form, CRM, API) and your document generation engine. It forces consistency. Most teams skip this, opting to pull data ad-hoc from various systems, which results in a tangled mess of data transformation logic embedded directly within the document templates.
A proper data model is hierarchical. It groups related information into logical objects and arrays. For instance, instead of `party1_name` and `party2_name`, you should have an array of `parties`, where each element is an object containing that party’s full details. This structure allows you to loop through signatories for a signature block or list all involved entities in an appendix without writing custom logic for every possible number of parties.
An Example Data Structure
Consider a simple MSA. A flat structure would be a long list of disconnected variables. A structured approach, using JSON for illustration, looks entirely different. It organizes the chaos.
{
"agreementTitle": "Master Services Agreement",
"effectiveDate": "2024-10-01",
"termInMonths": 36,
"parties": [
{
"role": "Service Provider",
"legalName": "Innovate Corp.",
"address": {
"street": "123 Tech Avenue",
"city": "Logicville",
"state": "CA",
"zip": "90210"
},
"signer": {
"name": "Jane Doe",
"title": "Chief Executive Officer"
}
},
{
"role": "Client",
"legalName": "Global Solutions Ltd.",
"address": {
"street": "456 Commerce Drive",
"city": "Metropolis",
"state": "NY",
"zip": "10001"
},
"signer": {
"name": "John Smith",
"title": "General Counsel"
}
}
],
"services": [
{
"serviceId": "S-001",
"description": "Cloud Infrastructure Management",
"monthlyFee": 15000.00
},
{
"serviceId": "S-002",
"description": "Quarterly Security Audits",
"monthlyFee": 5000.00
}
],
"governingLaw": "State of Delaware",
"isAutoRenew": true
}
This structure is predictable. It’s machine-readable and allows for powerful logic inside the template. You can now calculate the total contract value or generate a detailed service description table by iterating over the `services` array.
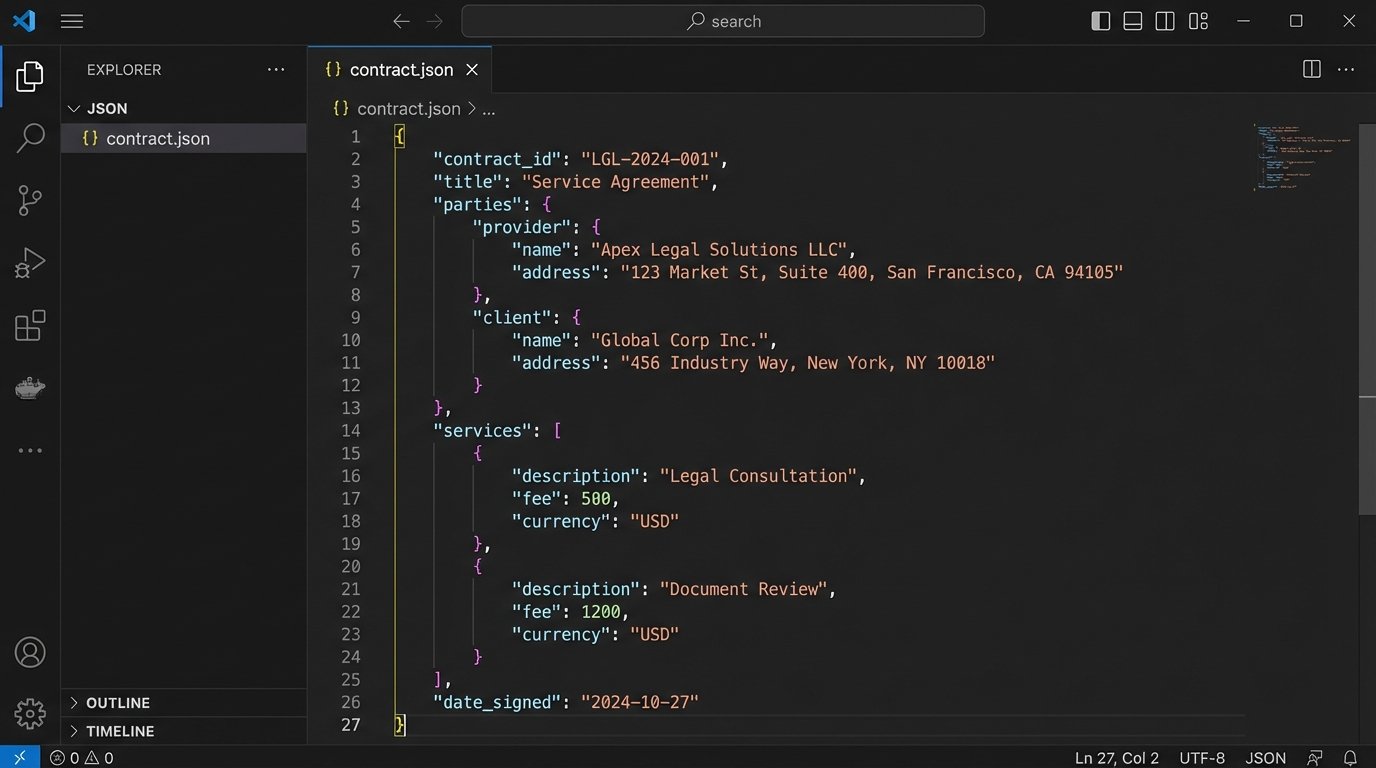
Building this model forces conversations about what data is actually required and where it lives. It’s a diagnostic process that often reveals serious gaps in a firm’s data hygiene long before a single document is generated.
The Template Engine: Your Logical Framework
Once the data model is solid, you can select a templating engine. These are not proprietary legal tech platforms that lock you in. They are battle-tested open-source libraries like Jinja2 (Python) or Handlebars (JavaScript). They do one thing well: merge a structured data object with a template file to produce an output. They are the engine, not the entire car.
Their syntax is intentionally simple. You use placeholders for variables and tags for logic. For example, to insert the client’s name from our JSON example, the syntax in a Jinja2 template might be `{{ parties[1].legalName }}`. The power comes from control structures: conditionals and loops.
Injecting Logic without Creating a Monster
Conditional logic is fundamental. You need to insert an arbitration clause only if the contract value exceeds a certain threshold, or change the governing law based on the client’s location. This is handled with if/else blocks directly in the template.
<p>
This Agreement shall be governed by and construed in accordance with the laws of the {{ governingLaw }}.
</p>
{% if totalContractValue > 100000 %}
<h3>Arbitration</h3>
<p>
Any dispute, claim or controversy arising out of or relating to this Agreement...
</p>
{% else %}
<h3>Dispute Resolution</h3>
<p>
The parties agree to resolve any disputes through mediation before pursuing litigation.
</p>
{% endif %}
This looks clean, but it’s a slippery slope. Overloading templates with complex business logic makes them impossible to maintain. A junior paralegal can no longer update a clause without risking a syntax error that breaks the entire generation process. The rule is to keep the logic in the template strictly related to presentation. Data transformation and complex business rules belong in the code that prepares the data object *before* it’s sent to the templating engine.
Connecting the data from your case management system or CRM to this process is often the most painful part. Many legacy legal platforms have poorly documented, sluggish APIs. Trying to pull clean, structured data from them in real-time is like trying to shove a firehose through a needle. You need an intermediary layer, a microservice, to fetch, clean, and structure the data into your predefined schema before passing it to the generator.
From Generation to Validation
Generating the document is not the final step. You must validate the output. Automation at scale introduces the risk of generating thousands of incorrect documents in minutes. A manual review process does not scale. You need automated checks.
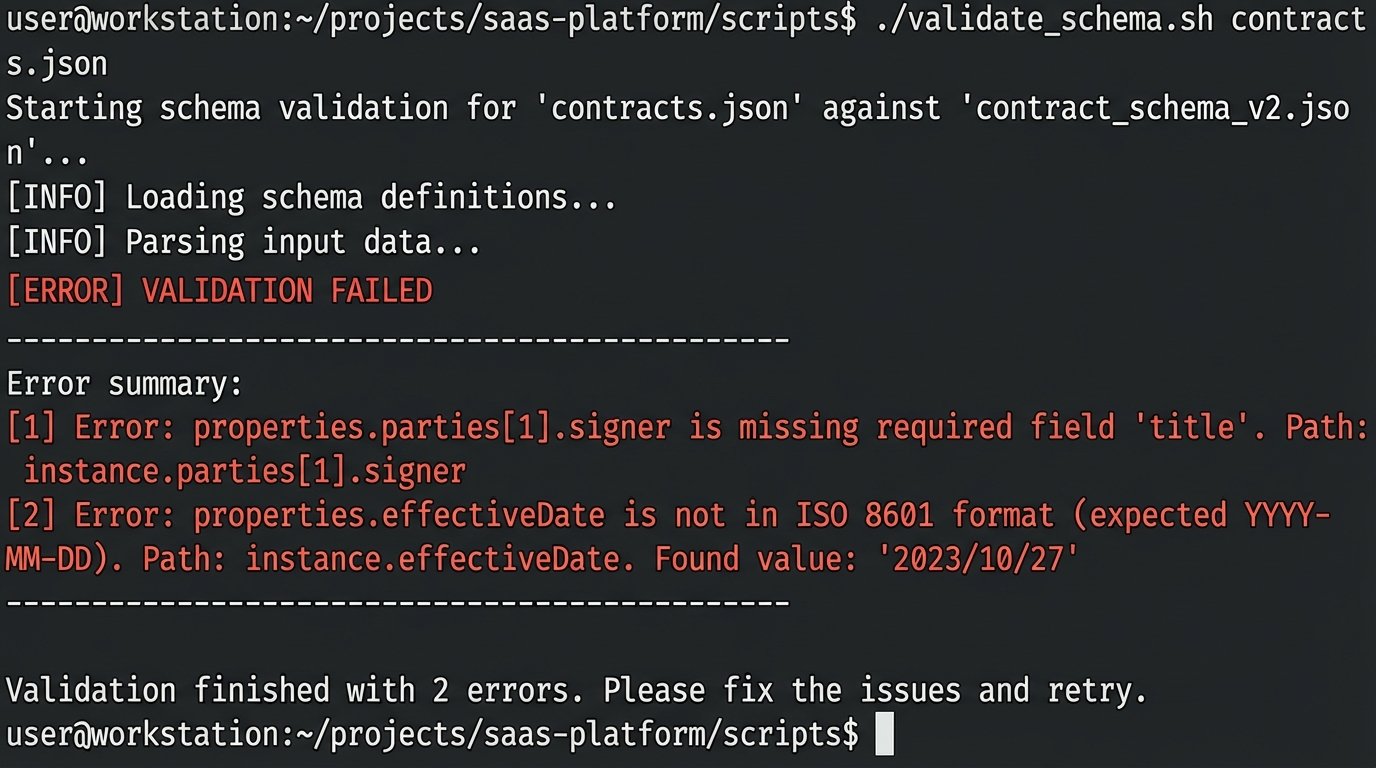
The first line of defense is schema validation on the input data. Before the data object even touches the template, run it against your predefined schema. Tools like JSON Schema can check for required fields, data types, and value formats. If an `effectiveDate` is malformed or a `party` object is missing, the process fails immediately, preventing a bad document from ever being created.
The second layer is template testing. You can create a suite of unit tests for your templates. Each test feeds the template a specific data object (a test case) and then inspects the output for expected content. For example, a test could feed a data object where `isAutoRenew` is `true` and then programmatically check that the generated document text contains the phrase “This Agreement shall automatically renew.” This catches regressions when someone modifies a template and inadvertently breaks existing logic.
The Overhyped Role of AI
AI-driven tools are now being aggressively marketed for contract drafting. They are powerful for specific tasks, but they are not a replacement for the structured automation we’ve discussed. Treating them as a magic box that takes a vague prompt and outputs a perfect contract is a recipe for disaster.
AI models excel at generating first drafts from natural language prompts (“Draft an NDA between a tech company and a contractor in California”). They can also be used to analyze existing contracts to extract key terms and convert them into a structured data object. This can be a useful starting point, a way to bootstrap the data entry process. It is not the endpoint.
The fundamental problem is that Large Language Models (LLMs) are probabilistic, not deterministic. They guess the next most likely word. They will hallucinate clauses, invent legal concepts, and misinterpret instructions with complete confidence. The output requires rigorous human review and, more importantly, must still be fed through a deterministic validation and assembly process.
A Saner Approach to AI Integration
A practical architecture uses AI for what it’s good at: unstructured-to-structured transformation. An attorney uploads a third-party paper. An AI model scans the document, extracts entities like parties, dates, and liability caps, and populates your predefined JSON schema. A human then reviews and corrects this structured data. Once validated, that clean data object is fed into the deterministic templating engine described earlier to generate your standard addendums or response letters.
This hybrid approach uses AI as an accelerator for the data capture phase, not as the core drafting engine. It bypasses the risk of hallucinated legal prose by keeping the final document generation within a trusted, testable, and deterministic system. Relying solely on an AI to draft from scratch for anything beyond a trivial agreement is a serious malpractice risk. The cost of these API calls is also a factor. Running thousands of contracts through a top-tier LLM is a wallet-drainer compared to a lightweight, self-hosted templating engine.
Ultimately, contract automation is a data engineering problem with a legal wrapper. Firms that recognize this and invest in building a solid data foundation will create reliable, scalable systems. Those that just buy the next shiny AI tool and hope for the best will be stuck debugging broken templates at 3 AM.