
Most document automation initiatives fail before a single line of code is written. They fail because the objective is framed as “go faster” instead of “enforce consistency.” Speed is a byproduct of a system that eliminates deviation. Manual drafting, by its nature, invites deviation through copy-paste errors, outdated clause libraries, and paralegals making ad-hoc edits at 11 PM. The goal is to build a system that forces the right data into the right template, every single time.
Achieving this requires a choice between two fundamentally different architectures. The first is classic document assembly, a deterministic process that merges structured data with a predefined template. The second involves injecting Large Language Models (LLMs) to generate dynamic text. Picking the wrong tool for the job doesn’t just lead to a failed project; it creates a maintenance nightmare that poisons the firm against future automation.
Deconstructing the Source: Templates and Data Primitives
Your firm’s existing documents are not templates. They are artifacts, littered with hard-coded values, track-changed comments from three years ago, and formatting overrides that will break any parsing engine. The first step is to gut these documents down to a clean, logical shell. Every piece of information that changes on a per-matter basis, from a client name to a notice period, must be ripped out and replaced with a variable placeholder.
A standardized naming convention for these placeholders is non-negotiable. A simple format like {{matter.client.name}} or {{agreement.effective_date}} provides clarity and maps directly to the data structures we will eventually build. Avoid cryptic names like {{var1}}; you will thank yourself during the inevitable late-night debugging session.
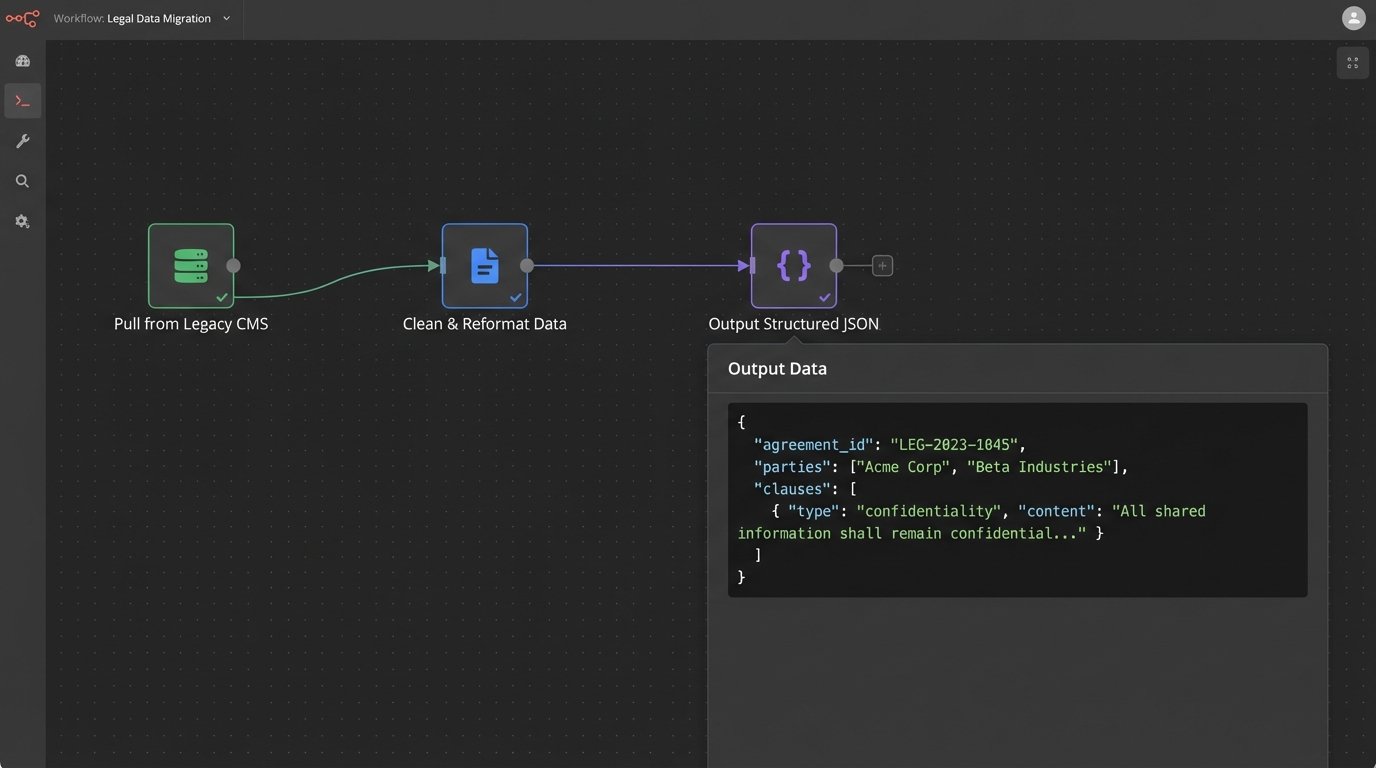
This templating process exposes the rot in your data hygiene. If you cannot definitively identify the single source of truth for the client’s registered address, the automation will fail. The system needs to pull from a reliable source, typically the firm’s Case Management System (CMS) or a dedicated client intake database. If that data is a mess of duplicates and typos, any automation built on top of it will simply generate garbage at an accelerated rate.
The Data Source Is Not Optional
The automation engine needs structured data, typically in a format like JSON. This data object is the payload that will be merged with your template. A well-defined data structure is the blueprint for the entire operation. It forces you to identify every required data point before any generation logic is built.
Consider a simple Non-Disclosure Agreement. The JSON payload might look something like this:
{
"agreement": {
"effective_date": "2024-08-01",
"term_months": 24,
"jurisdiction": "Delaware"
},
"disclosing_party": {
"name": "Innovate Corp.",
"address": "123 Tech Avenue, Silicon Valley, CA 94000",
"signer": {
"name": "Jane Doe",
"title": "CEO"
}
},
"receiving_party": {
"name": "Stealth Solutions LLC",
"address": "456 secrecy Lane, Wilmington, DE 19801",
"signer": {
"name": "John Smith",
"title": "Managing Director"
}
}
}
This structure is rigid. It ensures that every generated NDA has a term, a jurisdiction, and full details for both parties. Building this structure requires bridging the gap between your CMS API and the automation tool. This often involves writing a middleware script to pull data from a sluggish, decade-old CMS endpoint, clean it, and reformat it into the clean JSON the document engine expects.
This is the unglamorous, critical work that determines success or failure.
Path A: Deterministic Logic with Classic Document Assembly
Classic document assembly engines are the workhorses of legal tech. Tools like HotDocs, Contract Express, or the assembly features within platforms like Litera operate on a simple principle: merge a data payload with a template containing conditional logic. The output is predictable down to the last comma. You use this when you need absolute certainty that a specific clause appears if, and only if, a specific condition is met.
The logic is embedded directly into the template. For example, in your Word template, you might have a block of text wrapped in conditional tags:
[IF agreement.jurisdiction == "California"]
This agreement shall be governed by the laws of the State of California, and any disputes shall be resolved in the state or federal courts located in San Francisco County.
[ENDIF]
The engine parses this logic against the incoming JSON payload. If the condition is true, the text block is included. If false, it’s stripped out. This allows for complex documents with dozens of optional clauses to be generated from a single master template. The control is absolute.
The weakness of this approach is its inflexibility. If a new scenario emerges that the original logic did not anticipate, a developer must intervene. The business wants to add a new jurisdiction? That requires a code change to the template. This makes the system powerful but brittle, and it creates a dependency on technical resources for ongoing maintenance.
Path B: Probabilistic Generation with LLMs
Large Language Models offer a completely different path. Instead of merging data into a fixed template, you provide the LLM with a prompt containing the raw data and instructions for how to structure the document. The model generates the text from scratch. This introduces immense flexibility but trades deterministic control for probabilistic output. You are asking, not telling.
The core of this method is prompt engineering. A poorly constructed prompt will yield inconsistent, and often incorrect, results. A precise prompt acts as a set of constraints, guiding the model toward the desired output. It’s not just about what you ask, but how you structure the request.
Prompt Architecture Is Key
A robust prompt for document drafting has several components:
- Role Priming: “You are a senior paralegal specializing in corporate law. Your tone is formal and precise.”
- Instruction Set: “Draft a standard one-way Non-Disclosure Agreement. Do not include any provisions for mutual disclosure.”
- Contextual Data: “Here is the data for the agreement in JSON format: { … insert JSON payload here … }”
- Output Formatting: “The final output must be a clean text document. Do not include any commentary or introductory phrases. Start directly with the document title.”
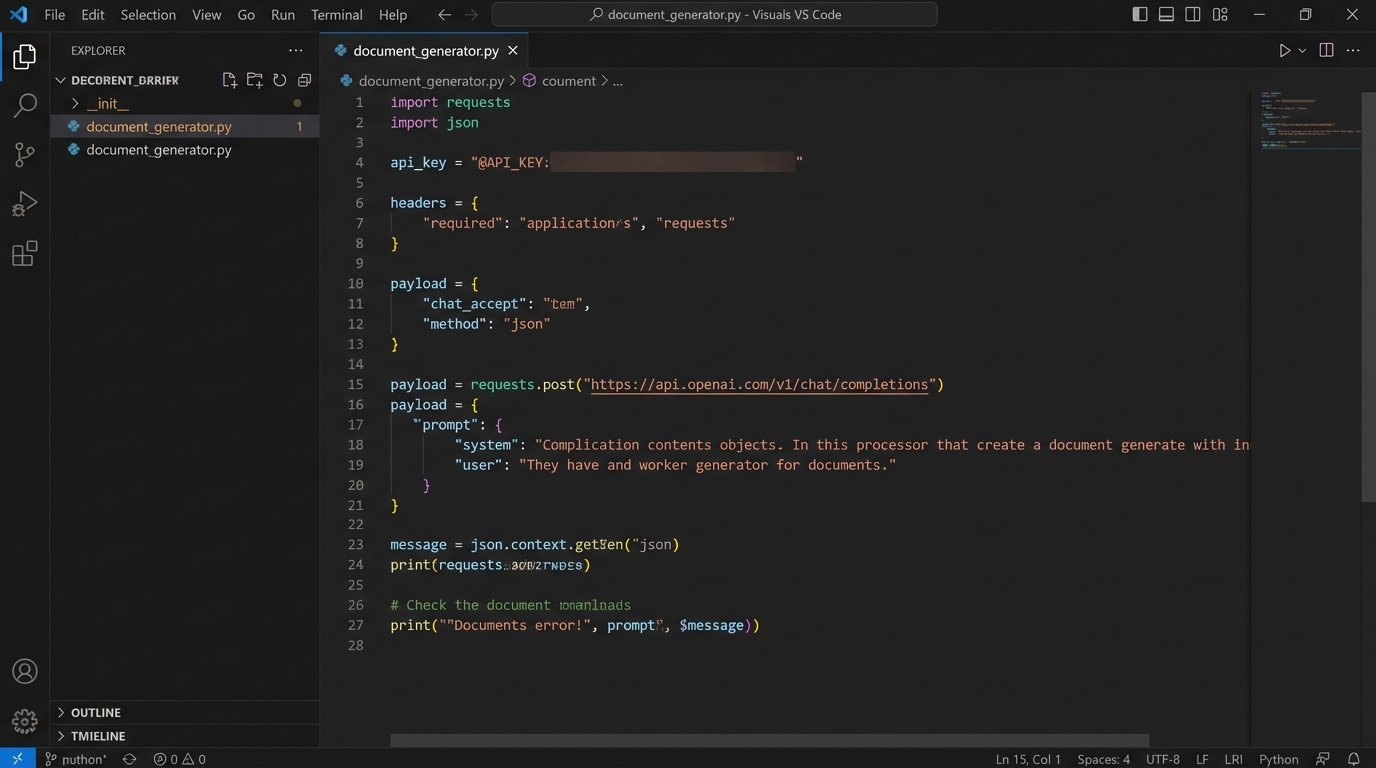
Sending this to an API endpoint is straightforward. A simple Python script using the requests library can handle the job:
import requests
import json
api_key = "YOUR_API_KEY"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "You are a senior paralegal specializing in corporate law..."},
{"role": "user", "content": "Draft an NDA using this data: { ... }"}
]
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, data=json.dumps(payload))
generated_text = response.json()['choices'][0]['message']['content']
The glaring risk here is hallucination. The LLM might invent a clause or misinterpret a piece of data, especially with complex instructions. For high-stakes legal documents, relying purely on an LLM to generate the entire text is a liability minefield. The output is not guaranteed to be identical even when given the same input twice.
The Hybrid Model: Building a Controlled Assembly Line
A pure-play approach, whether classic assembly or pure LLM, is a flawed strategy. The optimal architecture is a hybrid that leverages the strengths of both. This involves using the deterministic document assembly engine as the chassis for the document, handling the critical, high-risk legal language that must be perfect. The LLM is then used as a specialized tool for specific, lower-risk tasks within that structure.
This approach is like trying to force a firehose of unstructured data through the eye of a needle. The assembly engine provides the needle, a highly structured and controlled aperture, while the LLM manages the high-volume, less-structured flow of information that needs to be summarized or rephrased.
A practical application of this hybrid model:
- Base Document Assembly: A classic engine generates 80% of the contract. This includes the parties block, term, jurisdiction, indemnification, and limitation of liability clauses. All this data is pulled directly from the CMS. It is non-negotiable text.
- LLM for Dynamic Sections: For a section like “Background” or “Purpose,” the system can make a separate API call to an LLM. The prompt would include key facts from the matter notes and ask the model to generate a concise, two-paragraph summary.
- Clause Injection: The LLM-generated text is then injected back into a specific placeholder in the master template, like
{{llm.generated.background}}. - Final Rendering: The assembly engine performs a final pass, rendering the complete document with both the hard-coded clauses and the dynamically generated text.
This architecture provides the legal team with the safety of vetted, approved language for critical sections while still gaining the efficiency of AI for summarizing complex narratives. It contains the risk of the LLM to non-binding, descriptive parts of the document.
Rollout and The Inevitable Validation Phase
Deploying this system is not just a technical challenge; it’s a process re-engineering project. The first gate is forcing attorneys and paralegals to use the structured intake forms or update the CMS correctly. If they continue to put critical deal terms in a free-text “Notes” field instead of the designated `agreement.value` field, the automation is dead on arrival.
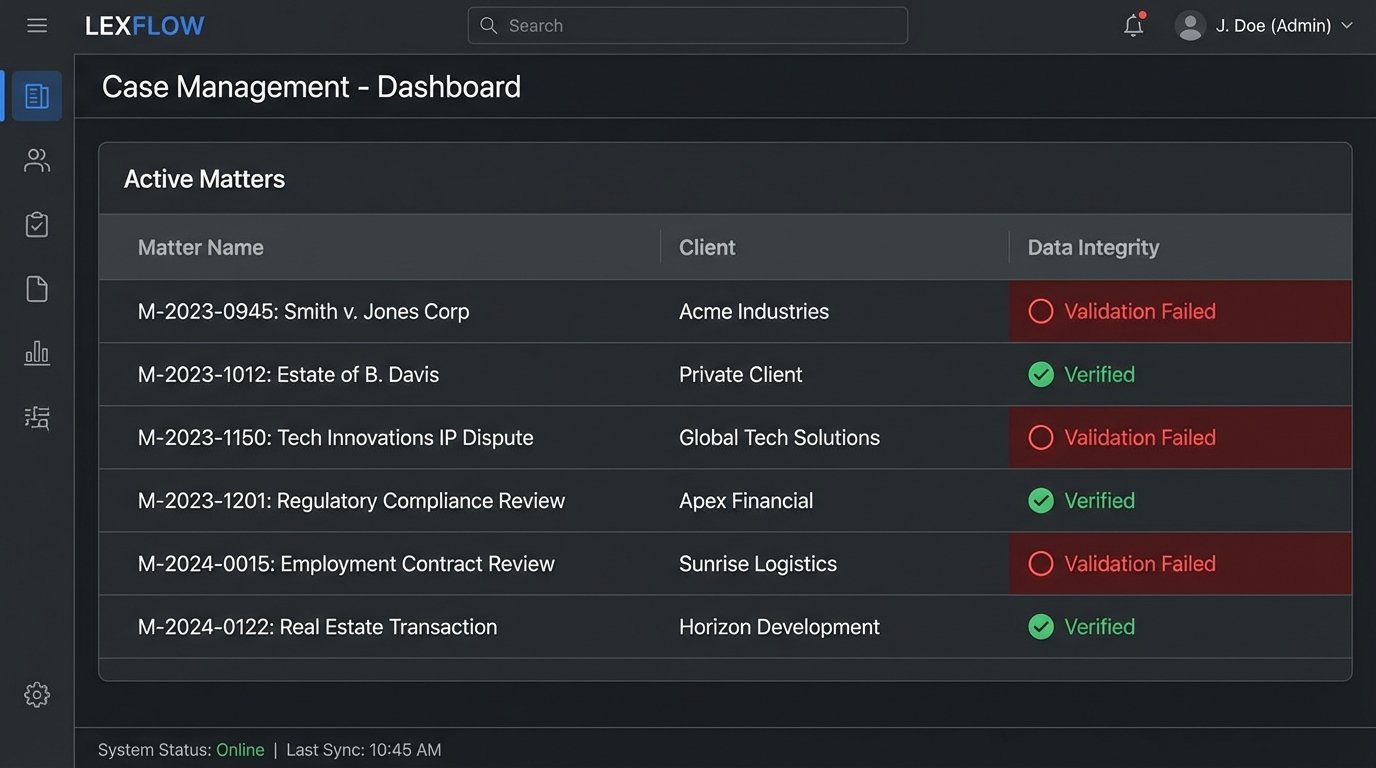
Building the Logic-Check Bouncer
Before any document is presented to a user, it must pass through a gauntlet of automated checks. These are simple, rule-based scripts that run after the document is generated but before it’s delivered. This validation layer acts as a bouncer, catching obvious errors that the core engines might miss.
A simple Python script can perform these checks. For instance, it can parse the generated document to ensure key sections exist and conform to firm policy.
def validate_contract(document_text, contract_value):
errors = []
if "Limitation of Liability" not in document_text:
errors.append("CRITICAL: Limitation of Liability clause is missing.")
if contract_value > 500000 and "Senior Partner Approval" not in document_text:
errors.append("WARNING: High-value contract lacks Senior Partner approval clause.")
return errors
# Usage
generated_doc = render_document(data)
contract_value = get_value_from_cms(matter_id)
validation_errors = validate_contract(generated_doc, contract_value)
if validation_errors:
route_to_manual_review(generated_doc, validation_errors)
else:
send_to_client(generated_doc)
This script doesn’t need to understand the law. It just needs to perform pattern matching and simple numerical comparisons. It’s a low-cost way to prevent high-cost mistakes. This layer is your last line of defense before a flawed document reaches a human reviewer.
Ultimately, automating document drafting is not about replacing legal professionals. It is about augmenting them by building a system that eliminates low-value work and enforces standards. The technology is a mirror that reflects the quality of your existing processes. If your manual workflow is a tangled mess, the automated version will just help you produce that mess more quickly.