
The core problem wasn’t time. It was data drift. Our commercial litigation group was running on a patchwork of Word templates, some dating back a decade. Associates would copy-paste clauses, tweak terms, and save new versions to a shared drive that looked like a digital landfill. The result was a constant, low-grade risk of using outdated boilerplate or introducing contradictory terms into a simple non-disclosure agreement.
Management saw a workflow inefficiency. We, the people who had to support the systems, saw a ticking time bomb of unforced errors. Every manually drafted document was a new, untracked data fork. The initial request was to “find a solution to make drafting faster.” Our internal diagnosis was that we needed to force a single source of truth and kill the copy-paste workflow entirely.
Deconstructing the Manual Process
Before any tech was evaluated, we had to map the existing chaos. We shadowed five attorneys for a week, logging every step of their drafting process for a standard Master Services Agreement (MSA). The process was fundamentally broken. It relied on institutional memory, with senior lawyers telling junior associates which “golden” version of a template to use from the shared drive. Version control was a filename convention: `MSA_ClientName_v4_FINAL_use_this_one.docx`.
This qualitative analysis exposed three critical failure points:
- Variable Error Rate: Manually finding and replacing placeholders like `[CLIENT NAME]` or `[EFFECTIVE DATE]` was prone to error. We found executed contracts where placeholders were left in.
- Clause Drift: An attorney would modify an indemnification clause for one specific deal, and that modification would become the new, unofficial boilerplate for their next five drafts, without review.
- Data Re-entry: Client data was keyed into the Client Relationship Management (CRM) system, then re-keyed into the document. Billing information was keyed into the practice management system, then re-keyed into the MSA. There was no data cohesion.
The situation was untenable. We weren’t just slow. We were actively injecting risk into the work product.
Solution Architecture: Bridging Legacy and Logic
The executive team wanted an off-the-shelf, cloud-based solution. We knew this would be a painful integration. Our core practice management system is a fifteen-year-old on-premise beast with a poorly documented SOAP API. Shoving data from that relic into a modern web app isn’t a simple integration. It’s more like performing a data transplant with rusty tools.
We settled on a platform that offered a robust API and a templating engine that separated content from logic. This was key. It allowed our paralegals and knowledge management team to update clause text without ever touching the code that assembled the documents. The architecture was designed in three layers: the data source, a middleware processing layer, and the document generation engine.
1. Data Source Connection: The first step was to bypass direct user input wherever possible. We built a connector that polled the practice management API for core matter data: client legal name, address, governing law jurisdiction, and key dates. Getting this data out was slow and ugly. The API would frequently return null values for required fields, forcing us to build a validation and fallback layer.
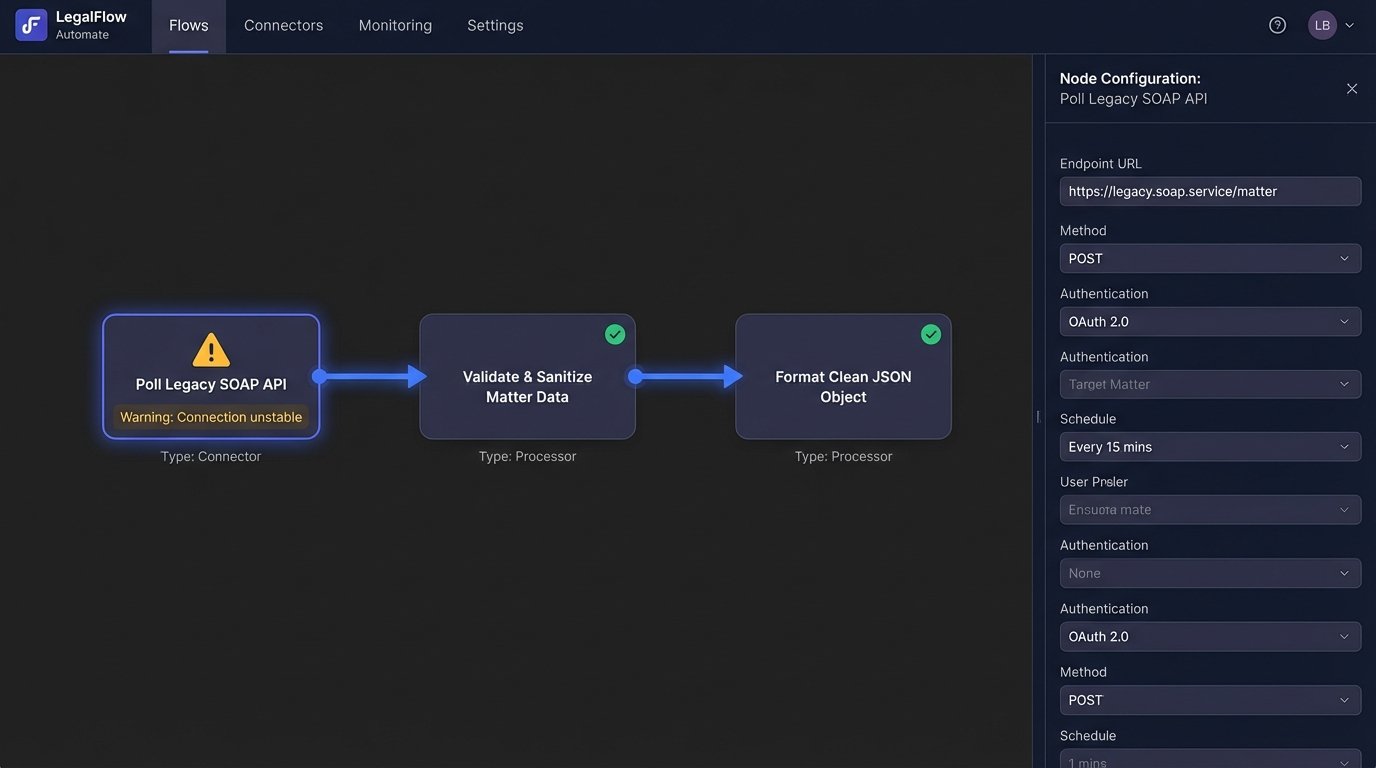
2. Middleware and Data Sanitization: A simple Python script running on a cron job served as our middleware. It fetched the raw data, stripped out weird formatting characters common in old database fields, and transformed it into a clean JSON object. This was the most critical piece. Without this sanitation layer, garbage data from the source system would have consistently broken the document assembly logic. The API output was a disaster, but the structured JSON we created was pristine.
// Raw API response snippet - note inconsistent casing and nulls
{
"client_Name": "MegaCorp Solutions, inc.",
"Jurisdiction": "DE",
"contractValue": "50000",
"internal_ID": null
}
// Sanitized JSON object for the document engine
{
"clientName": "MegaCorp Solutions, Inc.",
"governingLaw": "Delaware",
"contractValue": 50000,
"internalId": "N/A"
}
This transformation logic prevented countless downstream failures. It was our shield against the legacy system’s decay.
3. The Document Generation Engine: Inside the automation platform, we deconstructed our top 20 most-used documents into a clause library. Each clause was a standalone component. The templates themselves became simple instruction sets, essentially a list of clauses to include based on a series of questions presented to the user. A question like “Is this a US-based client?” would trigger conditional logic to include or exclude entire sections of the document.
The Template Conversion Ordeal
Converting two dozen master Word documents into a structured clause library was a brutal process. It took two paralegals and one engineer three months. We had to identify every variable, every optional paragraph, and every jurisdictional nuance. This process revealed just how inconsistent our own “standard” documents were. We found five different versions of the limitation of liability clause circulating in active templates.
The knowledge management team had to make hard decisions and declare one version as the official text. The automation tool didn’t just automate the workflow. It forced the firm to clean its own house from a content perspective. This was an expensive and politically charged side effect nobody had planned for.
Implementation Challenges and Hard Truths
The go-live was not smooth. The first week was a firefight. The primary issue wasn’t the technology, but the human element. Attorneys are creatures of habit, and we had just taken away their familiar Word documents.
User Resistance and Forced Adoption
Adoption was painfully slow at first. Many senior lawyers simply refused to use the new system, delegating the task to their assistants or continuing to use their old templates. The argument was always the same: “It’s faster for me to just do it the old way.” This was demonstrably false, but it was their comfort zone.
We couldn’t win with persuasion. We had to win by making the old way impossible. We worked with IT to archive the entire shared drive of old templates, making them read-only. We then integrated the new system directly into the matter intake process. To get a matter number, you had to generate the initial engagement letter through the system. We blocked the old path and made the new one mandatory.
It was a heavy-handed approach, and it didn’t win us any friends. But it worked.
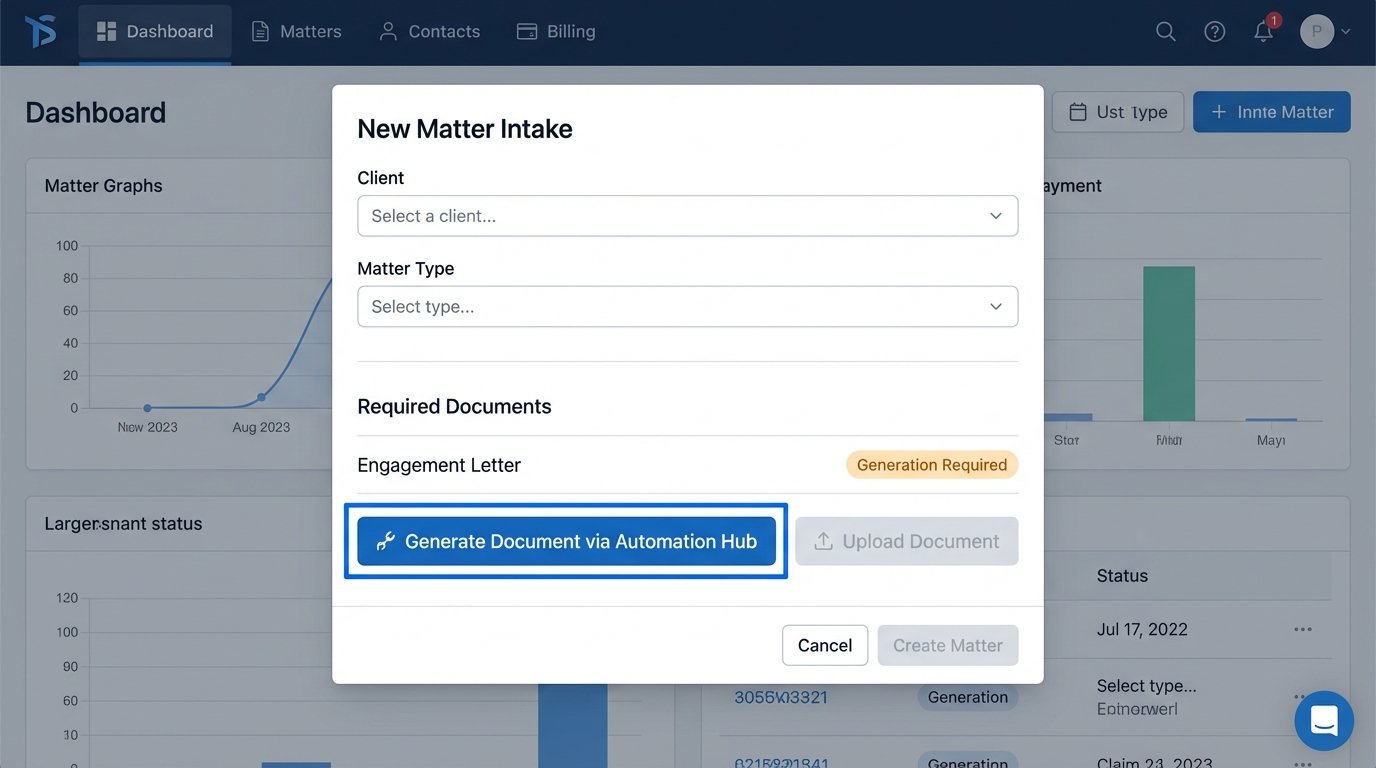
Performance Bottlenecks and API Timeouts
The second major hurdle was performance. Our middleware script pulling data from the legacy API was sluggish. For complex clients with dozens of associated contacts and matters, the API call could take up to 30 seconds. A user sitting there watching a loading spinner for that long is a user who is going to complain.
We couldn’t make the old API faster. It was what it was. The solution was to introduce a caching layer using Redis. The middleware would pre-fetch and cache data for all active matters every 15 minutes. When a user initiated a document, our system would pull from the Redis cache instantly instead of making a live, slow API call. This dropped the initial data-loading time from 30 seconds to under 200 milliseconds.
It was another technical bandage on a deeper problem, but it solved the user experience issue.
Quantifiable Results: Beyond “Time Savings”
After six months, the data was conclusive. We measured the impact across three key axes: speed, quality, and compliance.
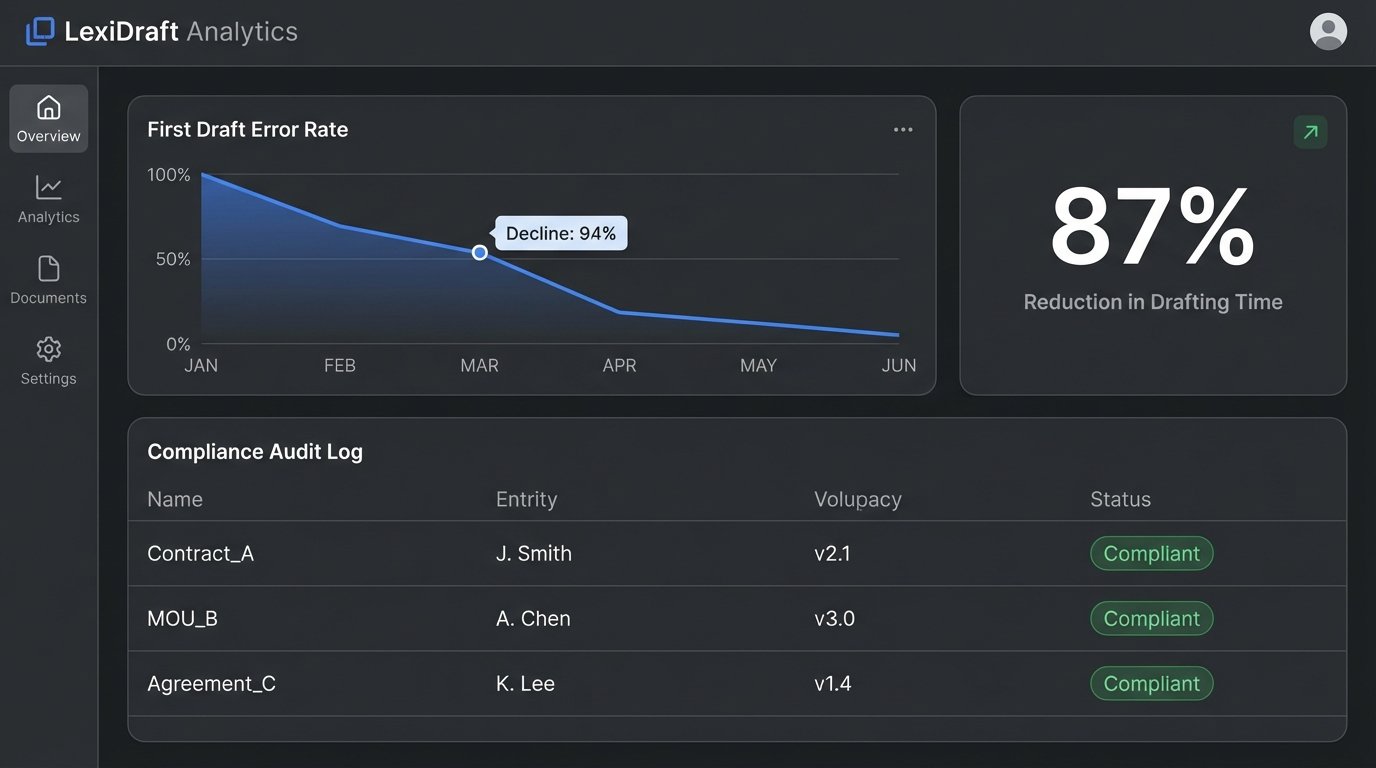
Speed: The metric management cared about most was pure time. For a standard MSA, the average drafting time, from opening the file to having a first draft ready for review, dropped from 45 minutes to 6 minutes. This was an 87% reduction. For simpler documents like NDAs, the time fell from 15 minutes to under 90 seconds. While impressive, this was the least important metric from a risk perspective.
Quality: This was the real win. We tracked the number of “redline” comments on first drafts that were related to formatting, typos, or incorrect client data. This category of errors dropped by 94%. The first drafts hitting the senior partner’s desk were clean. This meant their review time was spent on substantive legal issues, not on fixing clerical mistakes. The “review and revise” cycle for an average contract was reduced by two full days.
Compliance: The system provided an unbreakable audit trail. Every document generated was logged, along with the user who created it, the version of the template used, and the data piped in. We could prove, for the first time, that 100% of our new contracts were using the firm’s approved language for key clauses like indemnification and confidentiality. We completely eliminated the risk of clause drift.
The project ROI was calculated based on recovered billable hours and reduced risk. The initial cost of the software license and the internal engineering time was recouped in just under 11 months. More importantly, it fundamentally changed how the firm managed its intellectual property. Our contracts were no longer static Word documents, but dynamic assets assembled from a secure, version-controlled library.
This wasn’t a project about making lawyers faster. It was a project about injecting discipline and control into a chaotic, high-stakes process. The speed was just a welcome side effect of doing things right.