
Most lists comparing e-discovery platforms are useless marketing fluff. They regurgitate feature lists written by sales teams, ignoring the friction of production environments. The truth is, the “best” tool is a myth. The right tool is the one that fails the least for your specific data type, case size, and technical debt. This is about selecting the right tool for the job, not the one with the glossiest brochure.
The core bottleneck in any discovery workflow is ingestion and processing. A platform can have a beautiful UI, but if it chokes on a corrupted PST or mis-extracts metadata from a Bloomberg chat, your review team is dead in the water. We are looking at these platforms not as monolithic solutions, but as a collection of APIs, processing engines, and data models that we must force into our existing workflows.
1. Relativity: The Legacy Behemoth
Relativity is the default choice for a reason. It has a massive feature set and an ecosystem of third-party developers that bolt on functionality. It is the closest thing to an industry standard, which means finding experienced contract reviewers or project managers is straightforward. The platform’s extensibility is its greatest strength and its most significant weakness.
You can build almost anything inside Relativity using its APIs and custom applications. This power comes at a cost. A self-hosted Relativity instance requires a dedicated, skilled IT team to manage the complex web of SQL servers, agent servers, and web servers. Without proper hardware provisioning and constant monitoring, performance degrades from sluggish to unusable. RelativityOne, the SaaS version, abstracts away the infrastructure burden but introduces its own set of constraints and costs.
Technical Benefits & Faults
- Processing Engine Control: The Relativity Processing engine gives you granular control over ingestion. You can define specific rules for handling different file types, de-duplication methods (global vs. custodial), and metadata extraction. This is critical when you know your data set has specific quirks that a black-box processor would miss.
- Scripting and APIs: The platform exposes multiple APIs. The older, SOAP-based services are clunky but necessary for certain legacy scripts. The newer REST-based Kepler APIs are better but still have maddening inconsistencies in object model representation between endpoints. You will spend time debugging undocumented behaviors.
- Active Learning (TAR): Relativity’s Technology Assisted Review (TAR) engine, called Active Learning, is powerful but requires careful setup. A poorly configured project with a bad sample set will produce garbage results, and a project manager without statistical knowledge can easily misinterpret the recall and precision metrics. It is not a fire-and-forget solution.
The real issue with Relativity is its technical debt. The object model shows its age, and building complex, performant queries against the SQL backend requires a deep understanding of its table structures. Simple tasks can become needlessly complex, requiring multi-step scripting operations where a modern platform would use a single API call. It’s powerful, but it makes you work for it.
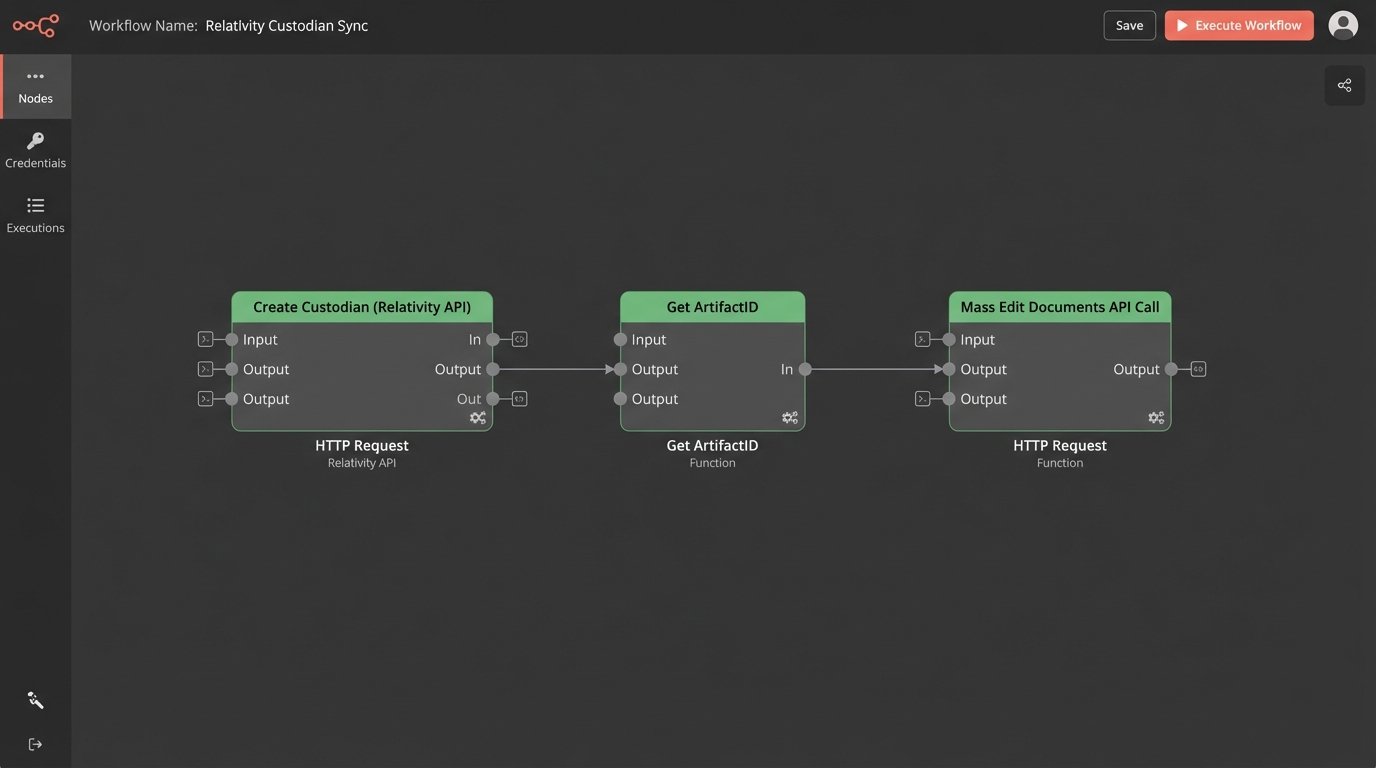
Consider a basic automation task: adding a new custodian and associating them with a set of documents. In a modern system, this might be a single REST call. In Relativity, you might have to first create the custodian object, get its ArtifactID, then perform a separate mass edit operation on the document objects, referencing the new ID. This adds latency and points of failure.
2. Logikcull: The Drag-and-Drop Ingester
Logikcull exists on the opposite end of the spectrum from Relativity. It was built for teams that do not have dedicated litigation support or IT staff. Its primary design goal is simplicity, sometimes at the expense of control. The user interface is clean, and the workflow is opinionated: upload your data, let it process, and start reviewing.
This simplicity is its selling point. You can hand it off to a paralegal with minimal training, and they can start culling a data set within hours. The processing is a complete black box. You drop a zip file into the browser, and documents appear. You cannot tweak OCR settings, adjust TIFF conversion parameters, or intercept processing errors with custom logic. The system either works, or you file a support ticket.
Technical Benefits & Faults
- Fast Ingestion for Standard Data: For standard business documents like PDFs, Office files, and emails in PSTs or MBOX formats, Logikcull is fast. The cloud architecture is designed to spin up resources and tear through this kind of data quickly.
- Predictable Pricing Model (Initially): The per-GB pricing model seems straightforward. This clarity can be deceptive. For matters that remain active for years, these storage costs accumulate. A case with 500GB of data can become a significant recurring expense.
- Limited Data Types: The platform struggles with non-standard data. Trying to ingest forensic container files (like an EnCase E01), Slack JSON exports with complex threading, or mobile device data is asking for trouble. It is not designed for the forensic complexity common in IP theft or white-collar cases.
Logikcull’s API is functional for basic tasks like creating projects and uploading data, but it lacks the depth for serious automation. You cannot programmatically manage review batches, script complex productions, or integrate with external case management systems in a meaningful way. It is a closed garden, designed to keep you inside its simple workflow.
3. Everlaw: The Reviewer-Focused Collaborator
Everlaw’s core strength is its user experience, specifically for the attorneys and paralegals conducting the document review. The interface is intuitive, fast, and packed with tools designed to build a case narrative. Features like the Storybuilder and Chronology builder allow legal teams to organize key documents and facts directly within the platform, bridging the gap between review and trial preparation.
From an engineering perspective, the platform is a mix of impressive frontend work and a sometimes opaque backend. The search interface is incredibly responsive, but the underlying search syntax is a proprietary abstraction over a standard search engine like Lucene or Elasticsearch. This makes it easy for non-technical users but can frustrate a technical operator trying to write a complex, nested query that is trivial in a system exposing the native search syntax.
Here is a concrete example. A standard dtSearch query in Relativity to find “apple” within 5 words of “pie” but not in the same sentence as “turnover” is straightforward:
"apple" w/5 "pie" NOT (apple AND pie AND turnover)
Translating that precise proximity and negative condition into a graphical search builder can be difficult or impossible. Everlaw’s system simplifies the process for common searches but removes power from the expert user. You trade granular control for ease of use.
Technical Benefits & Faults
- Collaboration Tools: The real-time messaging, assignments, and Storybuilder features are best-in-class. For cases that require a large, distributed team of reviewers, this can significantly reduce communication overhead compared to managing the process via email and spreadsheets.
- Cloud Native Performance: Like Logikcull, the platform is built on modern cloud infrastructure. Document rendering and search are typically very fast. They have invested heavily in frontend engineering, and it shows.
- Opaque Backend: Processing and data management are largely black boxes. While their support is generally good, you are dependent on them to resolve ingestion issues with problematic data. The API is improving but historically has lagged behind competitors in terms of functional coverage for administrative tasks.
Everlaw is the tool you choose when the primary success metric is the speed and efficiency of the human review team. It prioritizes the end-user experience. The cost is a loss of direct control over the underlying data processing and query execution. For many cases, this is a perfectly acceptable arrangement.

4. DISCO: The AI-Driven Platform
DISCO markets itself heavily on its use of artificial intelligence. While most platforms now have some form of TAR, DISCO integrated it more deeply into the core of the platform from the beginning. Their AI-powered review prioritization and quality control metrics are genuinely effective and often require less manual tuning than competing systems.
The system excels at quickly identifying patterns in large data sets. The user interface is clean and minimal, stripping away many of the legacy configuration menus that clutter older platforms. This focus on a streamlined experience makes it fast to get a review started. However, this streamlining can also feel restrictive when you need to deviate from their prescribed workflow.
Technical Benefits & Faults
- Effective TAR 2.0: The continuous active learning model is solid. Reviewers tag documents, and the model refines its understanding in near real-time, constantly re-ranking the remaining documents. This feedback loop is tighter than in systems that require explicit batching and index rebuilds.
- Fast UI and Search: Similar to Everlaw, DISCO is built on a modern tech stack. The user experience is responsive. Search performance is excellent for standard keyword and metadata queries.
- Workflow Rigidity: The platform’s greatest strength is also a liability. It is designed around a specific, AI-centric review methodology. If your case requires a different approach, like complex manual batching based on external criteria or a multi-stage review with custom permissions, you will fight the platform. Custom export and production formats can also be a pain point, sometimes requiring manual intervention from DISCO support.
The API is competent for standard integrations, but the platform’s core logic is not designed to be externally manipulated. You can push data in and pull data out, but you cannot easily script and automate the internal review management process to the same degree as you can in a more open system like Relativity. You are buying into their vision of how e-discovery should be done.
5. Nuix Workstation: The Forensic Processing Engine
Nuix is not a hosted review platform like the others. It is a powerful, desktop-bound data processing tool used by forensic investigators and high-end e-discovery service providers. Its inclusion here is critical because for certain types of data, you need Nuix to process it *before* it ever touches a review platform. Trying to ingest a 2TB forensic image of a hard drive or a collection of corrupted Lotus Notes databases directly into a cloud tool is an exercise in futility.
The Nuix engine is famous for its ability to brute-force its way through almost any file type you can throw at it. It processes data at a very low level, bypassing file system APIs to read data directly from disk images. This allows it to recover deleted files and handle data corruption that would choke other systems. It is the tool you use when the data is a complete mess.
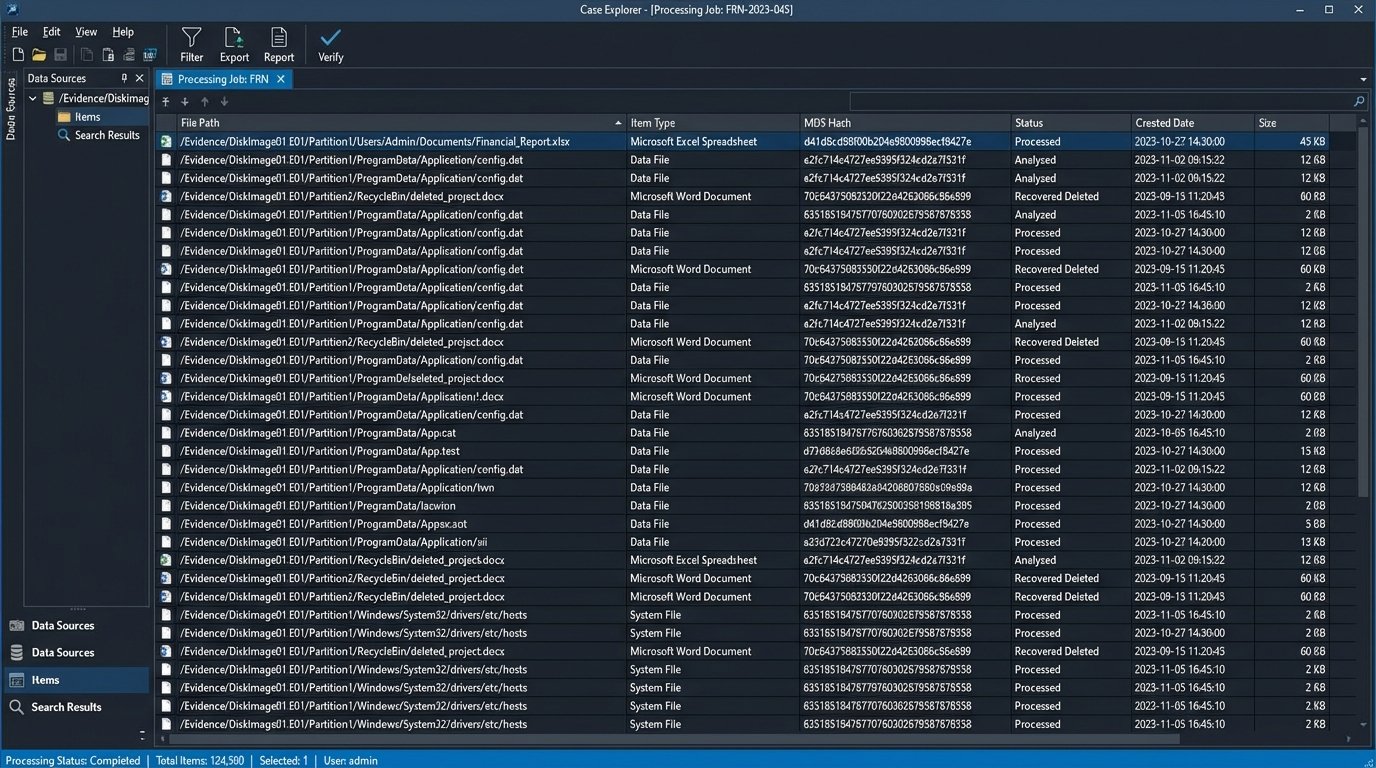
The workflow is to use Nuix Workstation to perform the initial ingestion, culling, and metadata extraction on the most difficult data sources. Then, you export a clean, normalized load file (like a DAT file with accompanying images and text) for import into a review platform like Relativity or Everlaw. This multi-step process adds complexity and time, but it is unavoidable for forensically complex matters. Forcing the highly structured, forensically sound output of Nuix into the rigid data model of a simplified cloud review platform often feels like shoving a firehose through a needle. The schemas do not always align, and you spend hours mapping metadata fields and troubleshooting import errors.
Technical Benefits & Faults
- Unmatched Data Type Support: From mobile device dumps (Celebrite UFDR files) to legacy email archives and enterprise chat logs, Nuix can parse it. Its library of file format support is the most extensive in the industry.
- Forensic Integrity: The tool is designed to maintain a chain of custody and provide detailed logging of the entire processing workflow. This is essential when the integrity of the evidence is likely to be challenged in court.
- Not a Review Platform: The interface is dense and built for a technical operator, not an attorney. It requires significant training to use effectively. It is a specialized tool for one part of the e-discovery lifecycle.
No single platform solves every problem. The modern legal tech stack is not about finding one perfect tool. It is about building a process that bridges the gaps between multiple, specialized systems. Your choice depends on whether your biggest problem is messy data, review team efficiency, budget predictability, or the need for deep customization. Choose the platform that best mitigates your primary point of failure, and have a plan for handling the data that it will inevitably fail to process.