
Forget the sales pitch. E-discovery automation isn’t a magic button you press to win cases. It is a disciplined engineering practice designed to force consistency and speed into a process plagued by human fatigue and error. When you are staring down a production order for two terabytes of unstructured data, the precision of a script is infinitely more defensible than the bleary eyes of a third-year associate on their tenth pot of coffee.
The core problem is scale. Human review does not scale linearly with data volume. The cost balloons and the error rate climbs. Automation is the only logical response, but it requires that you stop thinking like a lawyer and start thinking like an architect. This is about building a defensible, auditable machine to process evidence.
Groundwork: Pre-Flight System Checks
Diving into automation without a clean foundation is a direct path to failure. You cannot automate a chaotic, undefined process. The first job is to impose order on the mess you have been handed. This is non-negotiable groundwork.
Data Structuring and Ingestion
Your automation scripts will choke on inconsistent data formats. The initial step is to hammer all incoming data into a uniform structure. This means cracking open PST containers, recursively scanning nested ZIP files, and standardizing file naming conventions. You need a single, predictable entry point for your entire data universe before any analysis can begin. Any script you write will assume a consistent input, and if it gets garbage, it produces garbage.
This phase is about brute-force normalization. It is not glamorous, but a failure here poisons every subsequent step.
API Handshakes and Security
Your scripts need to talk to your review platform. This means getting familiar with the platform’s API, assuming it has a functional one. You will spend an inordinate amount of time dealing with authentication, usually OAuth 2.0, and wrestling with API keys. Get these credentials sorted and stored securely before you write your first function. Do not hard-code them into your scripts. Use environment variables or a secrets management system.
Many legal tech APIs are sluggish and poorly documented. Assume the documentation is five years out of date and that you will encounter undocumented rate limits at the worst possible moment.
Mapping the Manual Agony
Before you can automate a workflow, you must document the existing manual workflow with painful precision. Shadow a paralegal. Interview a junior associate. What are the exact clicks, filters, and decisions they make from the moment a document is ingested to the moment it is tagged for production? This map becomes the blueprint for your code. You are not reinventing the wheel. You are building a machine to turn it faster and more reliably.
This map exposes the repetitive, low-value tasks that are prime targets for automation.
Predictive Coding: Teaching the Machine to Read
Predictive coding, or Technology-Assisted Review (TAR), is not artificial intelligence in the cinematic sense. It is a statistical classification engine. You feed it examples of what is responsive and what is not, and it builds a mathematical model to categorize the rest of the document population. The goal is to elevate human reviewers from sifting through junk to confirming the model’s borderline decisions.
Building the Seed Set
The model is only as good as its training data. The process begins with a “seed set,” a small, statistically valid random sample of the document collection. A senior attorney, someone with deep case knowledge, must review and code this set. Their decisions form the ground truth from which the machine will learn. A biased or poorly coded seed set will build a useless model that confidently finds the wrong documents.
Your first script’s job is to pull this random sample. It must be truly random to be defensible.
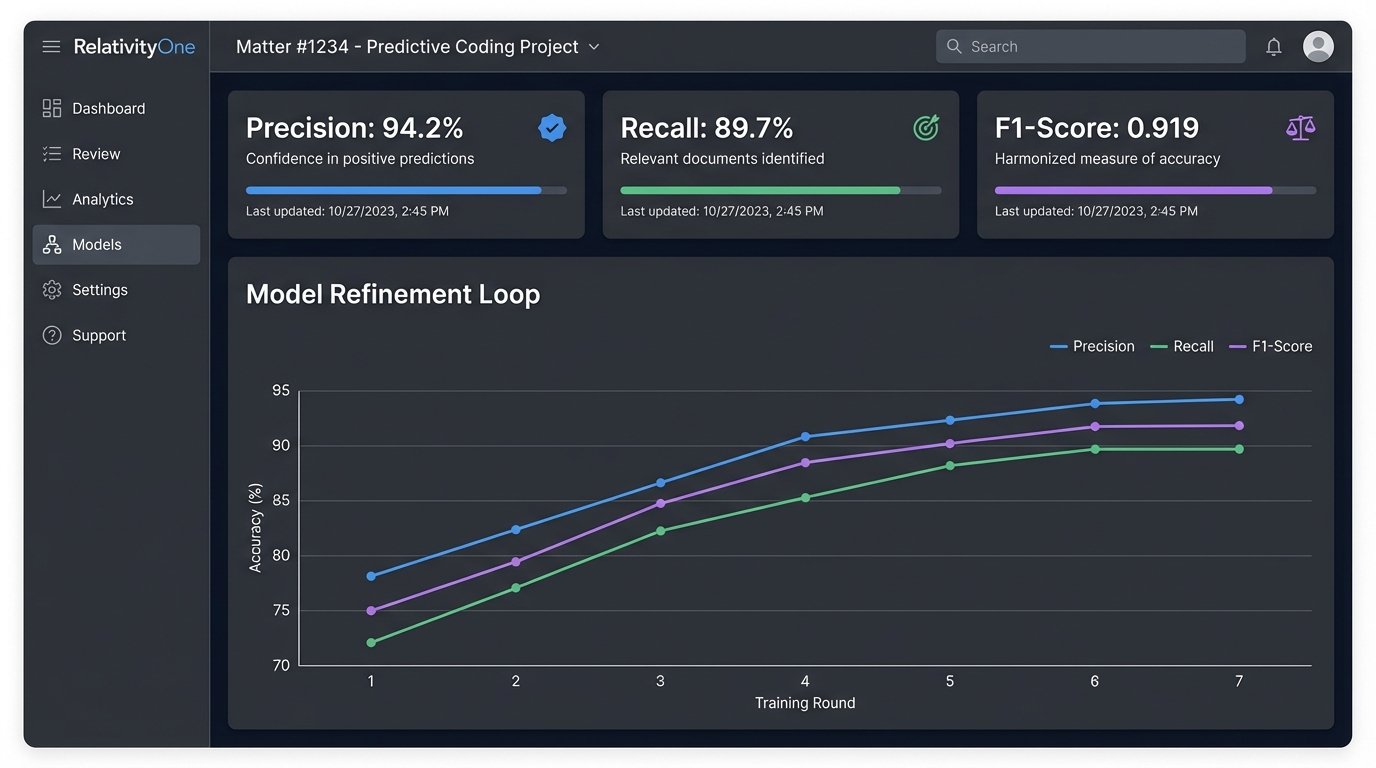
The Training and Refinement Loop
Once the seed set is coded, the training begins. The system converts the text of the documents and the attorney’s decisions into numerical vectors and trains a classification model. The model then scores the entire document population, predicting the likelihood that each document is responsive. The real work is in the refinement loop. The system identifies documents where its confidence is low, the “gray area” documents, and presents them to the attorney for review. Each human decision is fed back into the model, making it progressively smarter.
This is not a one-and-done process. It is an iterative cycle of machine prediction and human validation.
A simplified Python example shows the core logic. This is not production code, but it demonstrates the mechanical process of training a basic text classifier using scikit-learn.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Assume 'documents' is a list of document texts
# Assume 'labels' is a list of 0s (not responsive) and 1s (responsive) from the seed set
documents = ["The contract is signed.", "Invoice for services.", "Project plan is attached.", "lunch menu"]
labels = [1, 1, 1, 0] # From senior attorney review
# Define the model pipeline
text_classifier = Pipeline([
('vectorizer', TfidfVectorizer()),
('classifier', LogisticRegression())
])
# Train the model on the seed set
text_classifier.fit(documents, labels)
# Now, predict on new, unseen documents
new_docs = ["Please find the executed agreement.", "Can we reschedule our tee time?"]
predictions = text_classifier.predict(new_docs)
# predictions would be array([1, 0])
print("Predictions for new documents:", predictions)
This script vectorizes text and runs it through a simple logistic regression model. The actual implementation requires robust error handling, data connections, and a proper validation framework.
Defensibility and Validation Metrics
You will have to defend this process in court. That defense rests on statistical validation. Before you begin, you must sequester a “control set,” another random sample of documents that is never shown to the model during training. After the model is finalized, you run it against the control set and compare its predictions to a meticulous human review of that same set.
The key metrics are:
- Precision: Of the documents the model called responsive, what percentage were actually responsive? (Minimizes false positives).
- Recall: Of all the truly responsive documents, what percentage did the model find? (Minimizes false negatives).
- F1-Score: The harmonic mean of precision and recall, providing a single score for model quality.
These numbers are your proof. They replace subjective arguments about reviewer quality with cold, hard data.
Automating the Pre-Review Culling
Before you even get to expensive predictive coding, you can surgically remove huge volumes of junk data with simple, high-speed scripts. This is about eliminating irrelevant files before a human ever has to look at them.
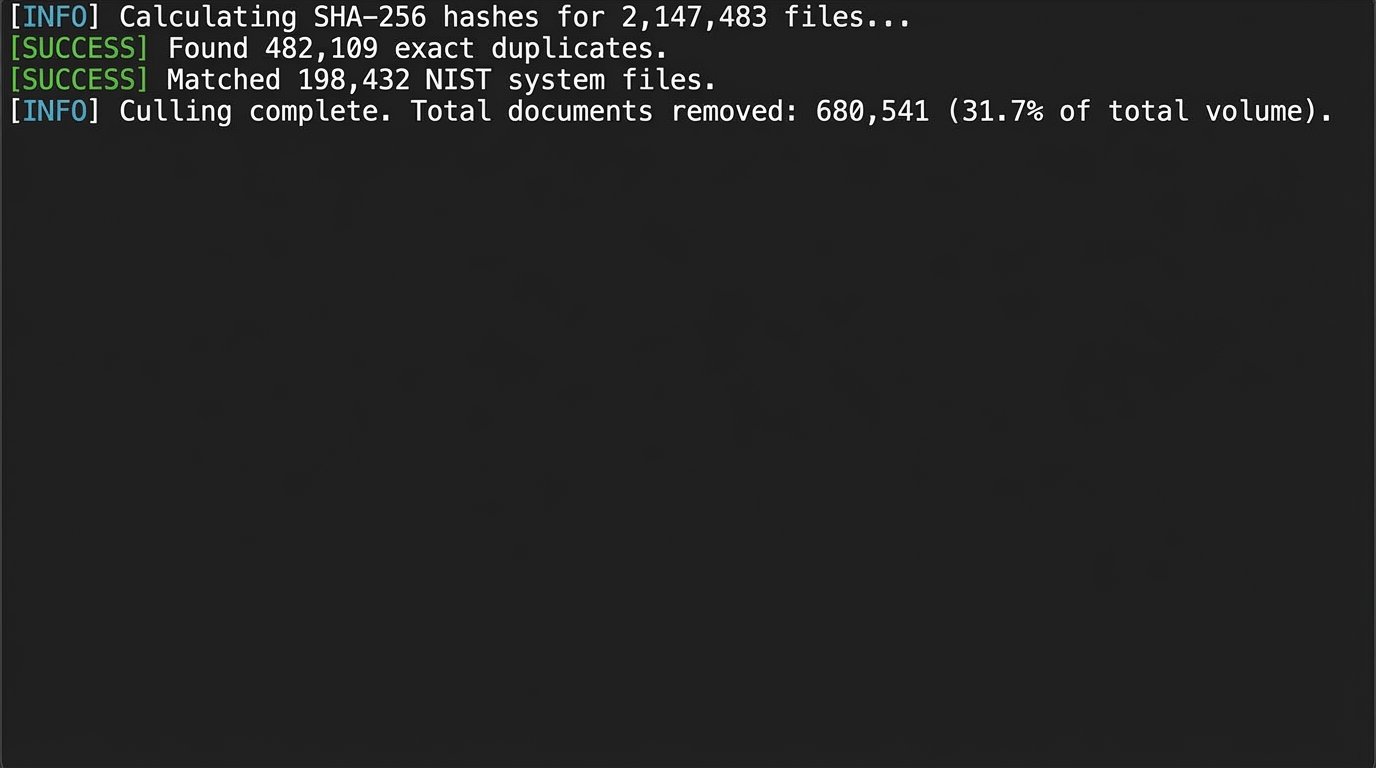
De-Duplication and De-NISTing
This is the most basic form of culling. First, you calculate a cryptographic hash (like SHA-256) for every single file. Identical files will produce identical hashes. You can instantly identify and set aside exact duplicate files, keeping only one copy for review. Second, you compare your file hashes against the National Institute of Standards and Technology (NIST) list, which contains the hashes of millions of known, common system files (e.g., DLLs, EXEs). Any file that matches a NIST hash is irrelevant operating system clutter and can be safely removed from the review set.
These two steps alone can often cull 20-30% of a data collection with near-perfect accuracy.
Keyword and Metadata Filtering
This is a cruder but faster tool. You can script a process to filter the collection based on simple criteria. This includes running a list of keywords against document text or filtering by metadata like date ranges, author, or file type. The main weakness is its lack of semantic understanding. A keyword search for “apple” will return documents about the fruit and the technology company without distinction. It’s a blunt instrument, but effective for initial, broad-stroke culling.
Trying to script against some of the older legal APIs is like performing remote surgery with rusty tools over a dial-up connection. You have to anticipate the connection dropping and the patient waking up mid-procedure.
Automated PII Redaction
Automating redaction is notoriously difficult. You can use regular expressions (regex) to find patterns that look like Social Security Numbers, phone numbers, or credit card numbers. This is fast but generates a high number of false positives. For example, any 9-digit number can be flagged as an SSN.
import re
text = "Call John at 555-867-5309. His SSN is 987-65-4321. Order number is 123456789."
# Regex for SSN (very basic, can have false positives)
ssn_pattern = r'\b\d{3}-\d{2}-\d{4}\b'
phone_pattern = r'\b\d{3}-\d{3}-\d{4}\b'
redacted_text = re.sub(ssn_pattern, '[REDACTED SSN]', text)
redacted_text = re.sub(phone_pattern, '[REDACTED PHONE]', redacted_text)
print(redacted_text)
# Output: Call John at [REDACTED PHONE]. His SSN is [REDACTED SSN]. Order number is 123456789.
A more sophisticated approach involves Named Entity Recognition (NER) models, which are trained to understand the context and identify entities like people, organizations, and locations. NER is more accurate but computationally expensive and requires significant setup. For most cases, regex provides a “first pass” that flags potential PII for human verification.
Integration and Deployment Realities
An automation script running on your laptop is a toy. A production system requires robust integration, logging, and maintenance. This is where most projects fail.
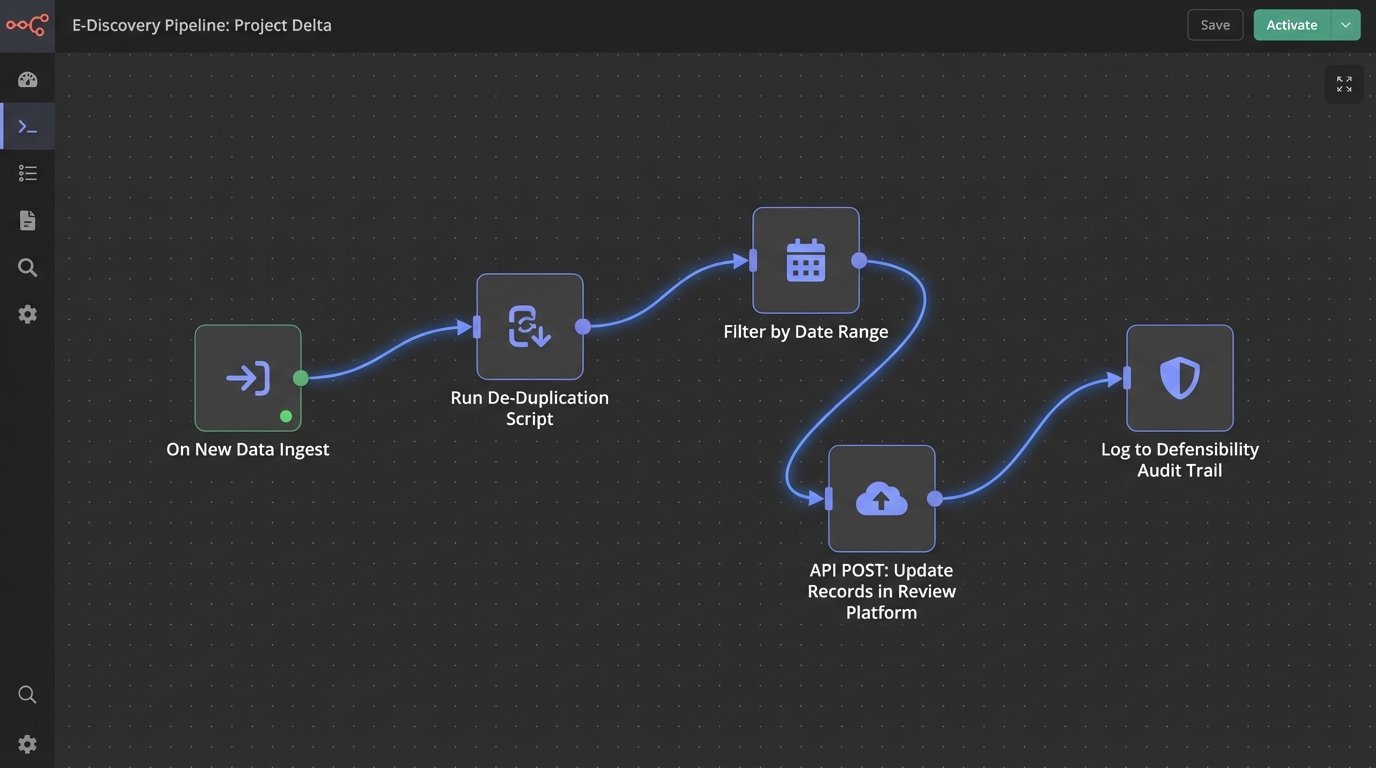
Connecting to the Review Platform
The goal is to inject your script’s findings back into the main review platform. This means using the platform’s API to update document records with new tags, responsiveness scores, or redaction markers. This process is often brittle. You are mapping the output of your code to specific field IDs in a system you do not control. If the platform is updated or a field is changed, your integration breaks. This requires constant monitoring.
The connection is a common point of failure, usually due to network timeouts or API rate limiting.
Logging for Defensibility
Your automation system must produce an immaculate audit trail. Every action taken on every document must be logged with a timestamp, the script that performed the action, and the rule that was triggered. If a document was culled because it was a NIST file, the log must show its hash and the match from the NIST database. This log is not for debugging. It is your primary evidence when you need to defend your process.
Without a log, you have an indefensible black box.
Maintaining the Machine
The work is not finished at deployment. Code dependencies must be managed. The production environment must be kept stable. More importantly, machine learning models experience “model drift.” A model trained on documents from the start of a case may become less accurate as new types of documents are discovered. You must have a process for periodically re-validating the model against newly human-coded documents and retraining it if its performance degrades.
An unmaintained automation system is a ticking liability. The value is not in writing the script, but in building a defensible and maintainable system that produces a reliable, auditable work product. It is about engineering a process that withstands technical scrutiny and legal challenges.