The marketing around AI in e-discovery is deafening. Vendors promise a push-button solution that eradicates manual review. This is a dangerous fiction. In reality, these systems are brittle statistical models bolted onto legacy review platforms. They don’t think. They calculate probability vectors based on training data. The core challenge is not buying the right tool, but wrestling your firm’s chaotic data into a format the machine can even begin to parse.
Forget the sales pitches. The real work starts when you try to bridge the gap between a lawyer’s definition of “responsive” and a machine’s mathematical representation of a document. It’s a lossy translation process, and every dropped signal is a potential point of failure in your case strategy.
Deconstructing the “AI” Label in E-Discovery
The term “AI” is mostly a branding exercise for a collection of older technologies. The two pillars you will actually encounter are Technology Assisted Review (TAR) and concept clustering. These are not new ideas, but their effectiveness has grown with raw compute power. Understanding their mechanical limitations is the only way to deploy them without inviting a motion to compel.
TAR has evolved. We started with TAR 1.0, a static process where a senior attorney coded a “seed set” of documents. The system would then extrapolate from that initial set to score the rest of the corpus. The model was fixed. If you discovered a new issue mid-review, you had to stop, retrain, and rerun everything. It was a wallet-drainer and horribly inefficient.
Modern platforms run on Continuous Active Learning (CAL), or TAR 2.0. As attorneys review documents, their coding decisions are fed back into the model in near real-time. The system continuously refines its understanding of relevance. This is more flexible, but it introduces its own set of validation problems. The model is a moving target, making it difficult to explain to a judge exactly why a document was scored a certain way on a specific date. Defensibility becomes a chase.
From Words to Vectors: How the Machine Reads
A machine does not understand context, sarcasm, or intent. It sees a document as a bag of words. It first strips out common “stop words” like “the,” “and,” and “is.” Then it performs stemming, reducing words to their root form (e.g., “running” and “ran” both become “run”). What’s left is a collection of tokens that the system counts and weighs for frequency and rarity across the entire document set.
This process, called vectorization, converts each document into a numerical array, a point in a high-dimensional space. The system then calculates the cosine similarity or Euclidean distance between these points. Documents that are “close” to each other in this space are deemed conceptually similar. This is the entire foundation of “AI” review. It’s geometric, not cognitive. This entire pipeline is a process of forcing unstructured human language through a rigid mathematical filter. It’s like shoving a firehose through a needle. You will lose pressure and a lot of water will spray everywhere.
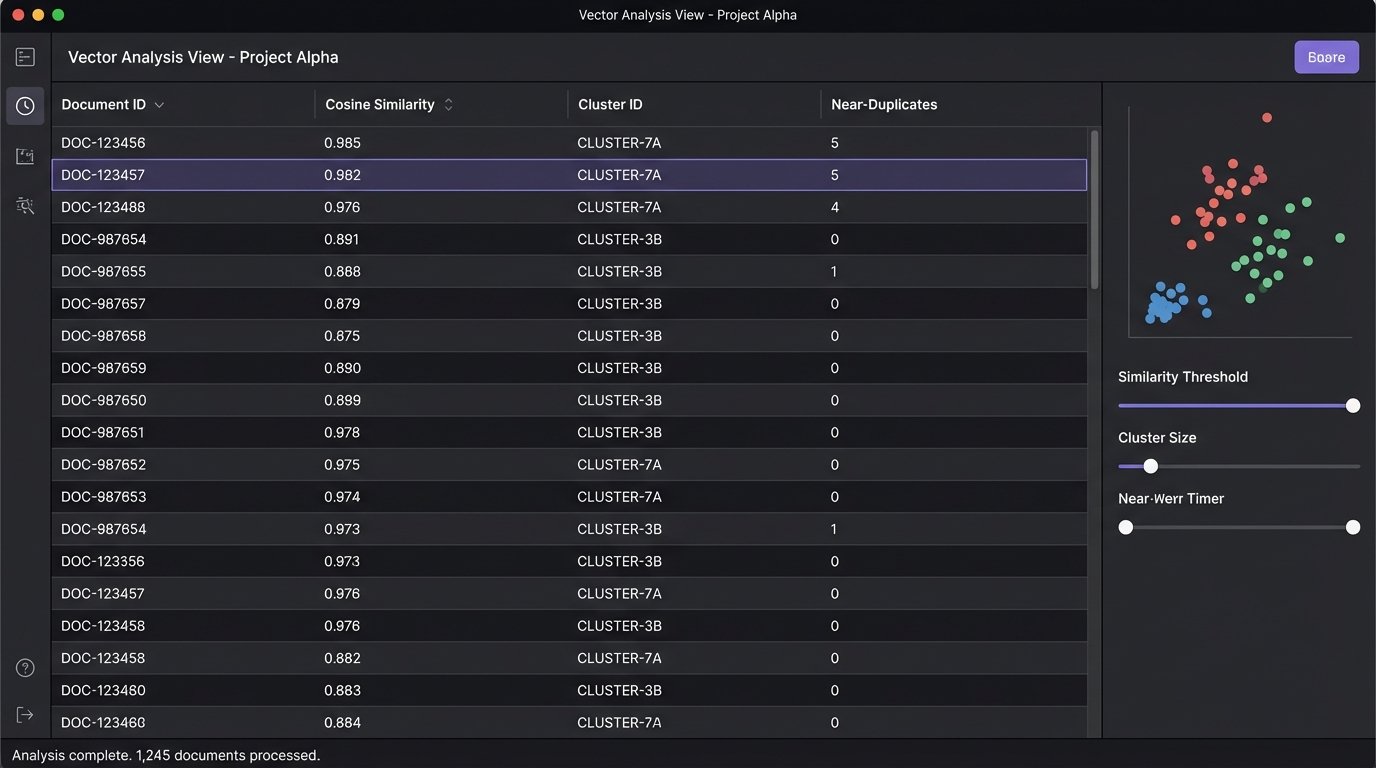
The problem is that legal relevance is often found in nuance, not word frequency. A single sentence like “We will not proceed with the acquisition” can flip the entire meaning of a 20-page contract that is otherwise identical to 50 other drafts. The AI, focused on the 99% of overlapping text, is very likely to cluster that critical document with all the others, burying the key evidence in a sea of near-duplicates. The human reviewer, exhausted from seeing the same document for the tenth time, might miss it too.
The Operational Drag of Data Ingestion and Normalization
Before any learning model can run, you have to feed it data. This is the least glamorous and most failure-prone stage of any e-discovery project. The source data is never clean. You get a chaotic mix of PST archives, Slack JSON exports, Box folders, and legacy database dumps. Each source has its own metadata structure, character encoding, and file format quirks.
Your first job is to force this chaos into a uniform structure. This involves extracting text, normalizing metadata fields, and handling exceptions for corrupted files or encrypted attachments. The AI platform doesn’t do this for you. It expects a clean, indexed data set. Your processing vendor or internal team bears this burden. A failure here poisons the entire process downstream. If the text from a critical PDF isn’t extracted correctly, the AI will never see its contents. For the model, that document simply does not exist.
A Practical Example: The Slack Data Problem
Modern collaboration data is a prime example of this challenge. A Slack export is not a collection of linear documents. It’s a JSON file containing nested conversations, edits, deletions, and reactions. A simple keyword search is insufficient because context is spread across multiple messages and threads.
To prepare this for an AI review tool, you have to write scripts to reconstruct conversations. You must decide on a unit of review. Is a single message a “document,” or is an entire day’s worth of conversation in a channel the “document”? Each choice has consequences for how the model will interpret the data.
Here is a basic Python snippet illustrating the problem of just grabbing text. It completely ignores context like threads, user IDs, or timestamps.
import json
def extract_slack_messages(json_file_path):
"""
A crude function to pull text from a Slack JSON export.
WARNING: This logic ignores threading, users, and all critical context.
It is for illustration of the data problem only.
"""
messages = []
with open(json_file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for message in data:
if 'text' in message:
# This logic is too simple. It misses edits, reactions, file attachments.
# A real-world parser is hundreds of lines long.
messages.append(message['text'])
return messages
# This is the simplified output the AI would see, stripped of all context.
# The model has no idea who said what or in what order.
# simplified_texts = extract_slack_messages('channel_export.json')
Feeding this decontextualized text into a TAR model is asking for trouble. The model will find keyword correlations but will completely miss the conversational flow that determines actual meaning.
Human-in-the-Loop: You Are the Auditor, Not the Laborer
The promise of AI is to reduce human effort. The reality is that it changes the nature of that effort. Instead of deploying an army of associates for first-pass review, you now need a smaller team of sharp, technically-minded attorneys to act as auditors of the machine’s output.
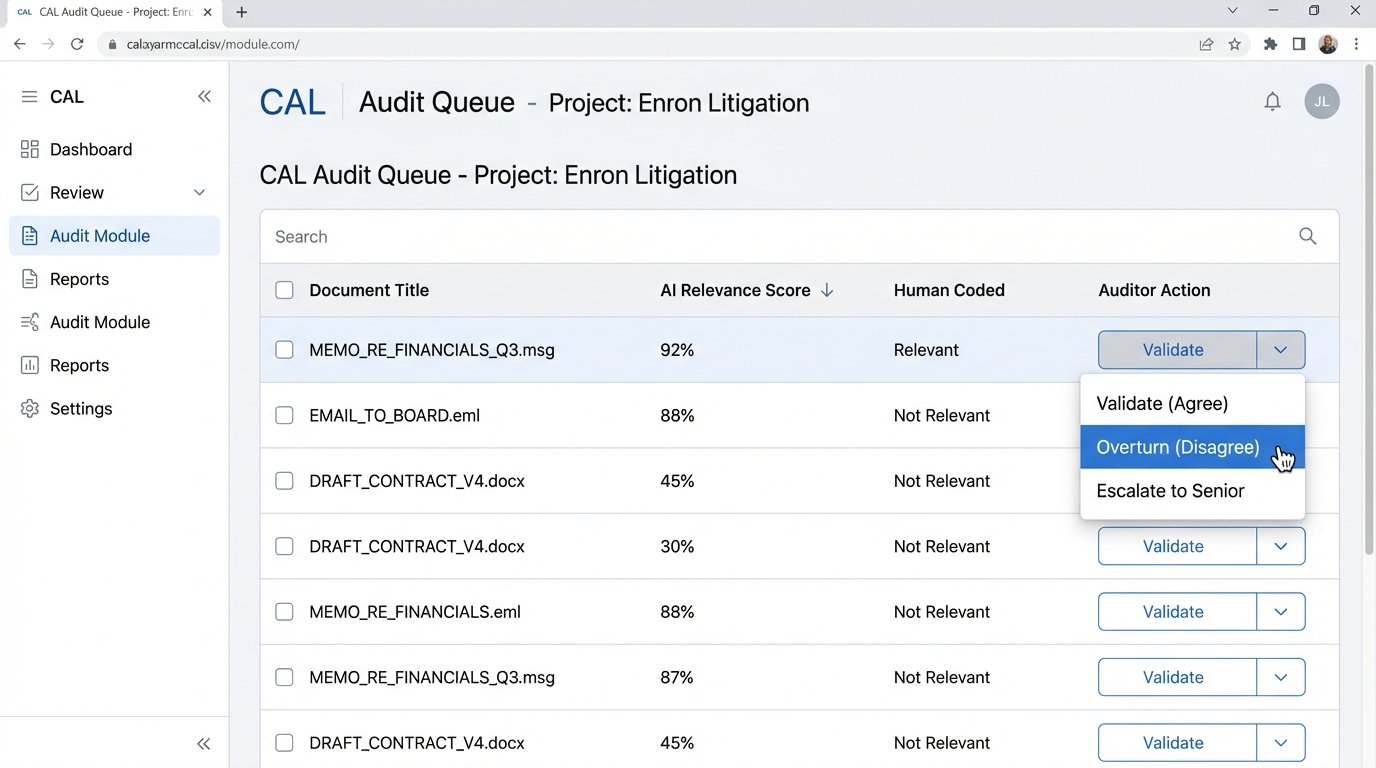
This team’s job is to constantly sanity-check the model. They perform quality control sampling on documents the AI has coded as non-responsive. They investigate anomalies. Why did the model suddenly start flagging documents about “Project Titan” as privileged? This requires a person who can diagnose if the model is overfitting on a few bad human decisions or if a genuine pattern has emerged. The skill set is different. It’s less about reading comprehension and more about systems analysis.
Validating the Black Box
One of the biggest fights is getting transparency from vendors. Many AI tools are a “black box.” They give you a relevance score from 1 to 100 but won’t show you the specific terms or factors that contributed to that score. This makes defending your process in court a nightmare. You must demand “reason codes” or “feature weighting” reports from your provider.
You need to be able to answer a judge who asks, “Why was this document, an email from the CEO, ranked as only 15% relevant and not reviewed by a human?” If your answer is “Because the algorithm said so,” you have already lost. Your answer must be, “The document was down-weighted because it lacked key terms A, B, and C that were consistently present in the 500 documents our senior partner validated as highly responsive.”
Beyond Relevance Ranking: The Next Tier of Tools
AI’s application in discovery is expanding beyond simple responsive vs. non-responsive coding. Tools for PII detection, privilege screening, and sentiment analysis are becoming common add-ons. These tools suffer from the same fundamental limitations.
Automated PII redaction is a good example. A system can be trained to find patterns that look like Social Security Numbers or credit card numbers using regular expressions (RegEx). But it will struggle with unstructured PII. For example, a doctor’s clinical notes might contain sensitive health information that doesn’t follow a predictable pattern. The AI will miss it entirely. These features are assists, not solutions. They require 100% human QC for any production workflow.
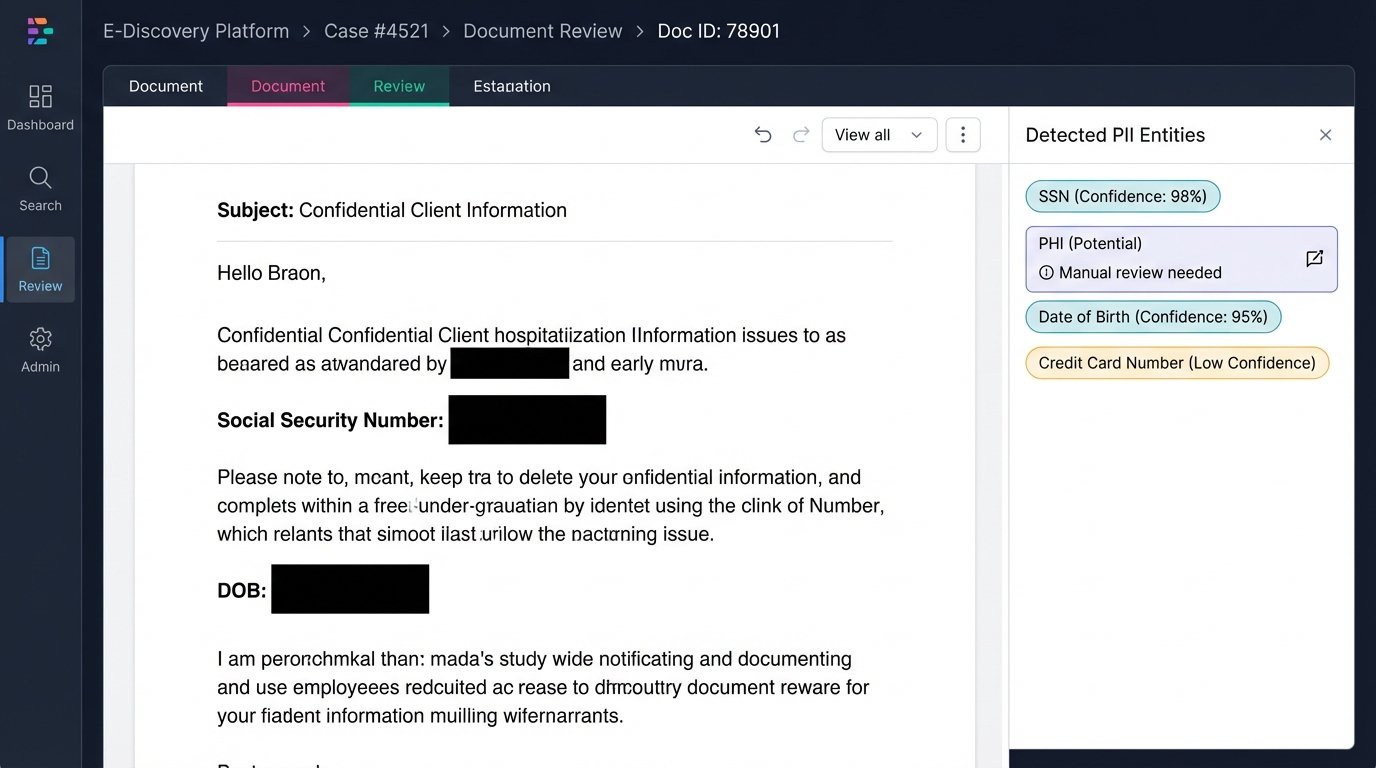
Privilege screening is even more problematic. A model can learn to flag documents containing the names of attorneys from the firm’s contact list. It can even learn to associate those names with phrases like “legal advice.” But it cannot understand the nuances of waiver or the complex relationships in a multi-party litigation. It will incorrectly flag thousands of emails where an attorney was merely copied for awareness. This creates a massive amount of false positives for the privilege review team to wade through, sometimes creating more work than it saves.
The role of AI is to automate the brute-force components of discovery, not the judgment. It is a powerful but dumb appliance. It can sort millions of items based on learned patterns, but it has no concept of legal strategy or evidentiary value. The future of discovery work belongs to professionals who can effectively manage these systems, diagnose their failures, and articulate their results to a court. The machine is a new kind of witness, and you need to be able to cross-examine it.