
The core failure of modern e-discovery is not data volume. It is workflow inertia. We shovel terabytes of unstructured data through a linear, human-gated process built for paper, then act surprised when costs balloon and deadlines slip. The problem is architectural. Relying on armies of junior associates for first-pass review is a brute-force attack on a problem that requires surgical precision. The entire model is predicated on the most expensive and error-prone component in the chain: manual human intervention.
This isn’t about better review platforms. It’s about building an intelligent orchestration layer that sits above them. A system that automates the rote, mechanical tasks of collection, processing, and initial analysis frees up legal minds to focus on strategy, not document triage. The goal is to force a state change, moving from a reactive review process to a proactive data intelligence operation.
Deconstructing the Collection and Processing Choke Point
Collection is the first point of failure. Manual exports from platforms like Slack, Microsoft Teams, or legacy email archives are notoriously inconsistent. They create chain of custody vulnerabilities and rely on custodians or IT staff who are not forensics experts. The process is sluggish, difficult to audit, and generates data in a dozen different formats that must be manually normalized before ingestion. This initial friction introduces delays that compound through the entire discovery lifecycle.
The only defensible and efficient method is direct, programmatic collection via API. This approach bypasses manual exports entirely, creating a repeatable and logged connection to the data source.
Scripting Direct Ingestion
Connecting directly to a source like the Microsoft Graph API or the Slack Discovery API allows you to pull data in a structured format. We use Python scripts to handle authentication, scope the data pull to specific custodians or date ranges, and perform an initial integrity check on the retrieved data. This method provides a clear, auditable trail from the source to the processing engine.
The primary challenges are API rate limiting and undocumented changes to endpoints. Your scripts must be built with defensive logic, incorporating exponential backoff for rate limit errors and robust logging to flag failed data pulls. Assume the platform’s documentation is at least six months out of date.
Shoving terabytes of raw data into a review platform without automated pre-culling is like trying to force a firehose through a needle. The pressure builds, the system breaks, and most of a mess gets made outside the target.
Automating the Pre-Processing Filter
The most significant cost savings in e-discovery occur before the data ever touches a per-gigabyte hosting platform. Once data is collected, a series of automated scripts should execute to gut the data set of irrelevant content. This is not a strategic analysis. It is a mechanical culling based on objective criteria.
This pre-processing layer should perform several key functions:
- De-duplication: Use hash values (MD5 or SHA-256) to identify and remove exact duplicate documents and emails across the entire custodian set. This is a simple but powerful step to reduce document count immediately.
- De-NISTing: Filter out known system files and application files from the National Institute of Standards and Technology (NIST) list. There is no reason for lawyers to ever see a .dll or .exe file in a standard document review.
- Metadata Culling: Apply hard filters based on custodian-provided date ranges or known irrelevant file types. If the litigation scope ends on a specific date, any document created after that date can be programmatically segregated.
Executing these steps with a simple script before uploading to a review platform can reduce data volume by 30-50 percent. This directly translates to lower hosting fees and a smaller, more manageable data set for the substantive review stages.
Gutting the Linear Review Model
The traditional linear review workflow is an anachronism. It forces reviewers to look at documents one by one, often with minimal context, making decisions in a vacuum. Technology-Assisted Review (TAR) was an improvement, but it still relies on a feedback loop where senior lawyers must train the system with example documents. This still creates a bottleneck and keeps expensive human resources engaged in a low-level classification task.
A truly automated system moves beyond simple predictive coding. It uses a combination of rule-based logic and machine learning models to perform a comprehensive first-pass analysis, separating the junk from the potentially relevant and flagging key document types without initial human input.
Beyond Basic Predictive Coding
While TAR and Continuous Active Learning (CAL) are useful for ranking documents by relevance, they are not the end of the line. The real efficiency gain comes from automated categorization that operates independently. We can deploy pre-trained models to identify specific document types like invoices, contracts, or presentations. We can also use rule-based classifiers to find documents containing specific patterns, like language indicating a joint defense agreement or a settlement discussion.
This approach splits the document population into logical buckets. The vast majority of documents, such as newsletters, spam, and system notifications, can be bulk-tagged as non-responsive by the machine with a very high degree of confidence. This leaves human reviewers with a much smaller, enriched data set of potentially relevant material to analyze for nuance and strategic value.

Automated PII and Privilege Flagging
Manually redacting personally identifiable information (PII) and identifying privileged communications is one of the most expensive and mind-numbing tasks in discovery. It is also where automation provides the clearest return on investment. Using a combination of regular expressions (regex) and Named-Entity Recognition (NER) models, we can automatically flag documents containing sensitive information.
For example, a regex pattern can instantly identify Social Security numbers or credit card numbers with near-perfect accuracy. An NER model can be trained to recognize names of attorneys from a case list and flag emails between them for privilege review. Below is a conceptual example of a Python function using regex to find potential Social Security numbers in a block of text.
import re
def find_ssns(text):
"""
Identifies potential Social Security Number patterns in a string.
This pattern is a basic example and should be refined for production use.
"""
ssn_pattern = re.compile(r'\b(?!000|666|9\d{2})[0-8]\d{2}-\d{2}-\d{4}\b')
potential_matches = ssn_pattern.findall(text)
return potential_matches
# Example Usage:
document_text = "The employee's SSN is 123-45-6789 and the start date was 01/01/2022. Contact was made to 987-65-4321 for verification."
found_ssns = find_ssns(document_text)
if found_ssns:
print(f"Found potential SSNs: {found_ssns}")
# Output: Found potential SSNs: ['123-45-6789', '987-65-4321']
This script does not replace a lawyer. It acts as a tireless assistant, highlighting every potential instance of PII for human verification. The workflow shifts from hunting for needles in a haystack to simply confirming the items the machine has already found. This reduces the risk of inadvertent disclosure and drastically cuts down on review hours.
The Production Phase: Automating the Final Mile
The production stage is often a chaotic scramble to assemble documents, apply Bates numbers, and generate privilege logs under intense deadline pressure. This manual process is ripe for error, leading to clawback agreements and costly re-productions. Automation injects discipline and repeatability into this critical final stage.
Scripting Production Set Generation
Once the review is complete and documents are tagged for production, a script can take over the entire assembly process. This script reads the final tag status from the review platform’s API, gathers the corresponding native files and text, and uses a library like PyPDF2 to apply endorsements, Bates numbers, and confidentiality stamps. It can then generate the necessary load files (e.g., .dat, .opt) required by opposing counsel.
This automated workflow ensures every production is consistent. It eliminates the risk of a paralegal forgetting to endorse a specific page range or using the wrong Bates prefix. The entire process can be run, validated, and documented in a fraction of the time it takes to do it manually.
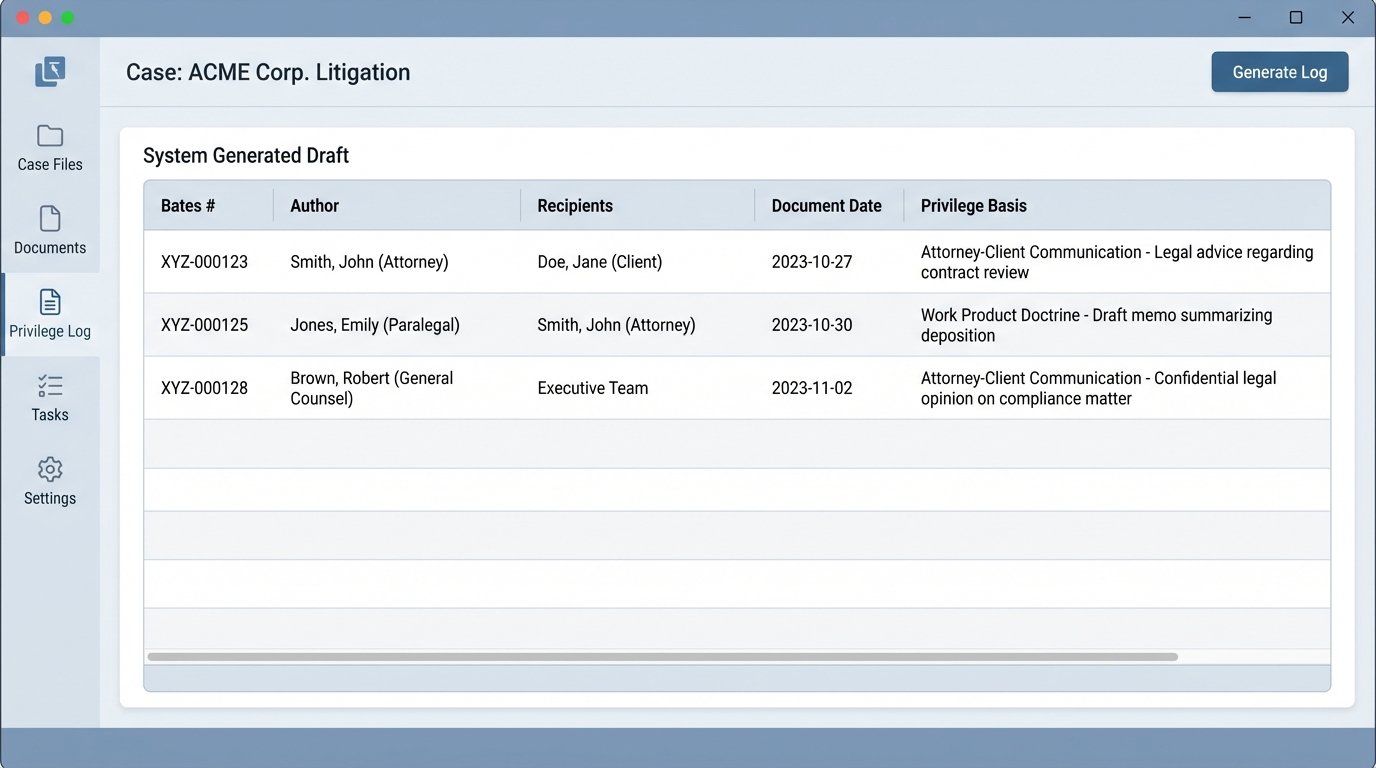
Logic-Checking Privilege Logs
Creating a privilege log is a high-stakes activity that is almost universally despised. A machine can generate the first draft of this log with perfect consistency. An automation script can be configured to pull all documents tagged as ‘Privileged’ and extract the required metadata fields: author, recipients, date, and subject line.
The script can cross-reference author and recipient names against a known list of in-house and outside counsel to auto-populate the basis for the privilege claim (e.g., ‘Attorney-Client Communication’). The result is a clean, formatted draft log. The lawyer’s role changes from data entry specialist to legal editor, reviewing the log for accuracy and refining the descriptions where necessary. This saves dozens, if not hundreds, of hours of expensive partner or senior associate time.
The Infrastructure and API Problem
The vision of a fully automated e-discovery pipeline runs into one hard reality: the fractured and often primitive state of legal technology infrastructure. There is no single platform that excels at every stage of the EDRM. The most effective systems are not monolithic applications but a constellation of best-of-breed tools connected by a custom-built automation layer.
The Myth of the All-in-One Platform
Vendors sell the dream of a seamless, all-in-one solution. The reality is that these platforms are often a collection of acquired technologies that are poorly integrated. The processing engine might be strong, but the review interface is sluggish. The analytics module might be powerful, but the production tool is inflexible. A service-oriented architecture is the only way to build a truly efficient system.
This involves using one tool for its superior processing capabilities, another for its advanced analytics, and a third for its review interface. The magic is in the plumbing. We build scripts and use middleware to bridge these platforms, moving data between them programmatically based on workflow triggers. This allows us to leverage the strengths of each component without being locked into the weaknesses of a single vendor’s ecosystem.
Wrestling with Legacy APIs
The biggest technical hurdle is the quality of the APIs provided by legal tech vendors. Many are slow, poorly documented, and lack features necessary for deep integration. Building a reliable automation workflow requires writing defensive code that anticipates failure. Every API call must be wrapped in error handling to manage timeouts, authentication failures, or unexpected changes in the data structure.
A simple `try-except` block in Python becomes your most critical tool. It allows your script to attempt an action, like fetching a document tag, and define a fallback behavior if the API fails, such as logging the error and retrying after a delay. Without this, a single network hiccup or a minor change on the vendor’s back end can bring your entire automated workflow to a halt.
The transition to an automated e-discovery model is not about buying new software. It is a fundamental shift in operational philosophy, backed by engineering talent. It requires firms to invest in developers who can write the code that bridges systems and automates decisions. The value is no longer in the platform itself, but in the intelligence of the custom logic that controls it.