
The firm was processing an average of three terabytes of new data per month for a single multi-district litigation matter. Their existing workflow was a manual click-path, stitched together with CSV exports and a team of 40 contract attorneys. The primary bottleneck was the initial data culling and privilege review, where human error rates for identifying attorney-client communication hovered around 8%. This wasn’t just inefficient. It was a quantifiable risk.
Each document passed through at least four manual checkpoints before promotion to a senior associate. This sequential process meant that a single misclassification early on could poison the entire downstream review set, forcing costly re-work. The cost-per-gigabyte for first-pass review was unsustainable, and the timeline for producing discovery was stretching into territory that invited motions to compel from opposing counsel. They needed to bypass the human latency factor without gutting their entire case strategy.
Deconstructing the Legacy Workflow
The client’s process was a classic example of technical debt in legal operations. Data ingestion from forensics was dumped into a shared network drive. A junior paralegal would then manually create a batch in their on-premise review platform, a sluggish system with an API that hadn’t been updated in five years. Search term reports were run as monolithic queries, often timing out and requiring the IT team to intervene.
Privilege screening was entirely manual. Reviewers applied tags based on a 50-page PDF protocol document. The lack of standardized tagging logic resulted in inconsistent application of “Attorney-Client Privilege” versus “Attorney Work Product.” Quality control involved a random sampling of 5% of the documents, a statistically insignificant sample size given the document volume. This created a recursive loop of corrections and re-reviews.
Their approach to Personally Identifiable Information (PII) was even more brittle. It relied on reviewers visually spotting social security numbers, bank account details, and other sensitive strings. This method is notoriously unreliable and exposed the firm and its client to significant data breach risks during discovery production. The entire system was a series of failure points waiting for a large enough data set to collapse under its own weight.
Architecture of the Automated Solution
We rejected a full platform migration. A rip-and-replace approach would have torpedoed the case timeline and budget. The strategy was to build a lightweight, automated pre-processing layer that would sit between data ingestion and the existing review platform. This layer would function as an intelligent filter, enriching the data and culling the noise before a human ever saw it.
The core of this solution was a series of Python scripts, orchestrated by a Jenkins server for scheduling and dependency management. We chose Python for its robust data manipulation libraries like Pandas and its ability to interface with various APIs. The workflow was broken down into discrete, auditable stages.
Step 1: Ingestion and Metadata Extraction
Instead of manually loading data, a script now polls the forensics ingestion point. Upon detecting a new load file, it triggers the process. The first action is to use a library to parse the raw data files, extracting all available metadata and text content. We bypass the review platform’s own clunky processing engine, which gives us direct control over the data stream.
This direct parsing allows us to normalize the data immediately. We corrected inconsistent date formats, resolved character encoding issues, and generated a unique, persistent hash for every single document. This hash became the primary key, ensuring data integrity throughout the entire lifecycle. This part of the process is about creating a clean, predictable foundation. You can’t automate chaos.
Step 2: Automated Tagging and PII Identification
With clean data, the real automation begins. We developed a rules engine to systematically tag documents based on objective criteria. This is where we replace the 50-page PDF with code. The engine used a combination of regular expressions and dictionary lookups to perform its tasks.
- Privilege Flagging: A script cross-references participant metadata (From, To, Cc, Bcc) against a curated list of all internal and external counsel domains and names. Any communication involving these parties was automatically flagged as “Potentially Privileged” for priority human review. This simple filter immediately isolated the highest-risk documents.
- PII Detection: We used advanced regular expression patterns to identify common PII formats, such as social security numbers, credit card numbers, and bank routing information. Documents with positive hits were tagged “Contains PII,” triggering a separate redaction workflow.
- Junk and System File Culling: The script identifies and flags documents based on file type and hash value. Common system files, logos, and irrelevant embedded images are isolated from the primary review set using a blocklist of known hash values from the NIST National Software Reference Library. This alone reduced the initial review volume by nearly 15%.
This automated first-pass review doesn’t replace attorneys. It augments them by letting them focus on documents that actually require legal analysis instead of repetitive, low-value classification tasks. It’s the difference between asking a surgeon to sort screws and asking them to perform surgery.
Step 3: Intelligent Data Grouping
The system then groups documents to accelerate human review. Email threading analysis was critical. The script reconstructs conversations, identifying the final, most inclusive email in a chain. This allows reviewers to assess an entire conversation at once, rather than looking at dozens of individual, duplicative messages. We also implemented near-duplicate detection to cluster substantively similar documents, like different drafts of a contract.
This grouping logic is complex. It’s not just about matching text. It requires a nuanced understanding of document structure and context. Trying to push this much data through the old platform’s native tools was like shoving a firehose through a needle. Building it externally gave us the processing power to do it right.
Step 4: Controlled Injection into the Review Platform
Once the pre-processing is complete, the final stage is to load the enriched data into the legacy review platform. We reverse-engineered their dated API to allow for programmatic data injection. The script pushes the documents, along with all the new metadata and automated tags, into the system as a structured, pre-organized batch.
A manifest file is generated for every batch, creating an audit trail that details every action taken on every document by the automation. This level of traceability was impossible in the old manual workflow and became a critical component for defending the process.
Here is a simplified Python snippet demonstrating the logic for a basic privilege check against a document’s metadata. This is a conceptual example, not production code.
import re
# Pre-compiled list of attorney email domains for performance
ATTORNEY_DOMAINS = {‘@clientlawfirm.com’, ‘@opposingcounsel.com’}
def flag_privileged_communication(document_metadata):
“””
Checks participant fields for known attorney domains.
`document_metadata` is a dict with keys like ‘from_email’, ‘to_emails’, etc.
“””
participants = []
participants.append(document_metadata.get(‘from_email’, ”))
participants.extend(document_metadata.get(‘to_emails’, []))
participants.extend(document_metadata.get(‘cc_emails’, []))
for email in participants:
if not isinstance(email, str):
continue
# Extract domain from email string
match = re.search(r’@([\w.-]+)’, email)
if match:
domain = ‘@’ + match.group(1).lower()
if domain in ATTORNEY_DOMAINS:
# Found a match, flag and exit early
document_metadata[‘is_potentially_privileged’] = True
return document_metadata
document_metadata[‘is_potentially_privileged’] = False
return document_metadata
This function logic-checks each document’s participants against a master list. It’s a simple binary check, but when applied across millions of documents, it saves tens of thousands of hours of manual work.
Implementation Hurdles and Adjustments
The project was not a straight line. The initial deployment exposed weaknesses in the source data. We found thousands of documents with missing or corrupted metadata from the forensic collection, which caused our parsing scripts to fail. We had to build in more resilient error handling and a quarantine process for documents that could not be parsed automatically.
There was also significant pushback from the legal team. They were conditioned to trust human review and were skeptical of automated tagging. To build trust, we ran the automated system in parallel with the manual workflow for two weeks. We then presented a detailed analysis comparing the results. The automation correctly identified 99.7% of the privileged documents that the human reviewers found, and it also flagged 2% that the humans had missed. The data resolved the debate.
The legacy platform’s API was another source of pain. The documentation was incomplete, and the API had undocumented rate limits. Our initial high-volume data injections caused the server to become unstable. We had to throttle our scripts and implement a queueing system to feed data to the platform at a rate it could handle without crashing. It was a tedious process of trial, error, and watching log files at 2 AM.
Quantifiable Results and New Realities
After three months of operation, the metrics showed a radical transformation of the e-discovery process. The results were not just improvements. They were order-of-magnitude changes.
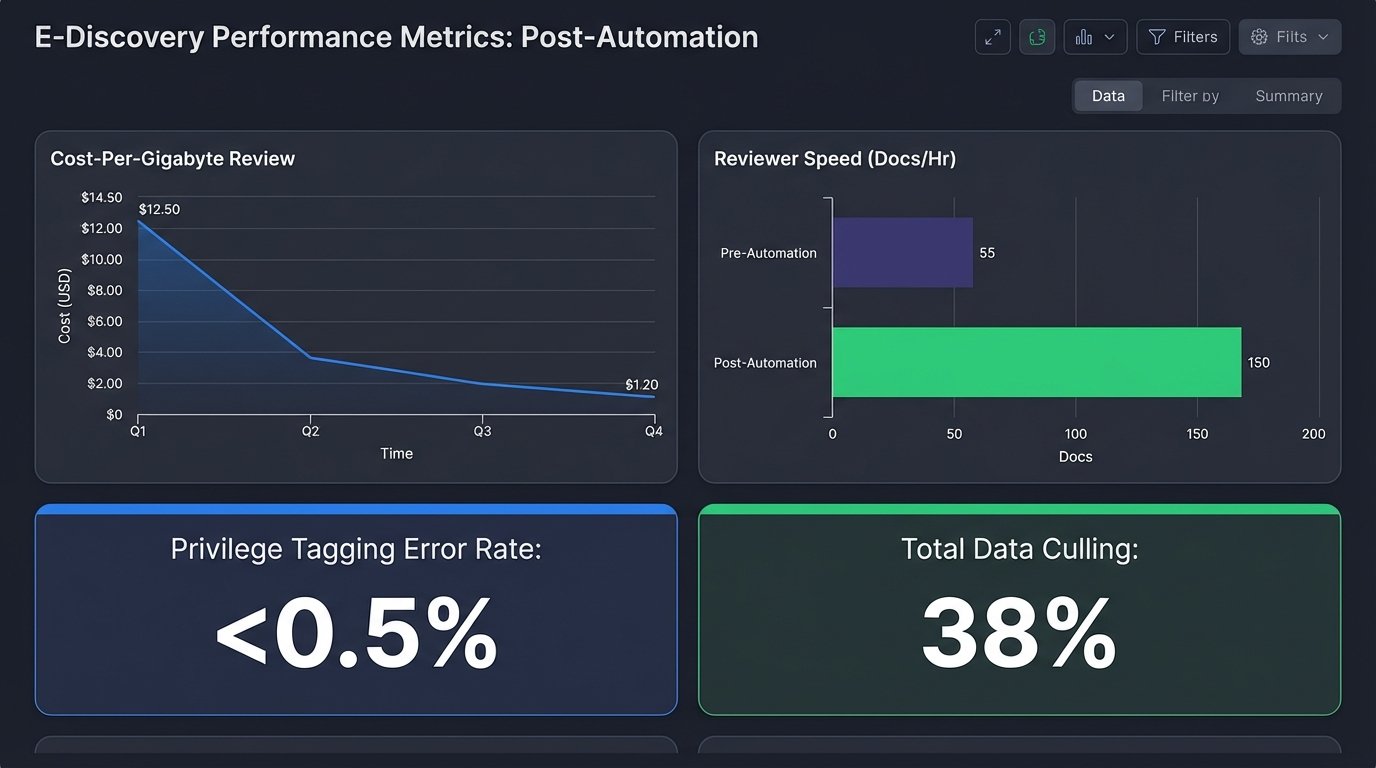
- Data Volume Reduction: Automated de-duplication and system file culling reduced the volume of data requiring human eyes by 38% before review even began.
- Review Speed: The average document-per-hour review rate for the contract attorneys increased from 55 to over 150. This was a direct result of the data grouping and pre-tagging, which provided reviewers with better context.
- Accuracy and Consistency: Tagging consistency for objective criteria like privilege and PII reached over 99%, up from an inconsistent baseline. The error rate on privilege calls dropped from 8% to less than 0.5%.
- Cost Reduction: The firm reduced its monthly contract attorney spend for this specific matter by 62%. The total cost-per-gigabyte for the entire discovery lifecycle, including the automation infrastructure, was cut in half.
This automation did not eliminate the need for human lawyers. It refocused their efforts on high-value work. The contract attorney team was downsized, but the remaining reviewers were able to concentrate on the most complex and nuanced documents. The senior associates spent less time on quality control and more time on case strategy, using the clean, structured data to find key evidence faster.
The new reality is that the firm now has a dependency on this technical infrastructure. It requires maintenance, monitoring, and a person who understands how the scripts work. They traded a massive payroll problem for a smaller, more focused technical operations problem. For any firm operating at scale, that is a winning exchange.