
Manual document review is a data integrity liability. The core problem isn’t the hourly rate of a contract attorney, it’s the non-deterministic, error-prone process of having humans eyeball millions of documents under pressure. Automation injects logic and repeatability into a process defined by fatigue and human bias. It forces a structured workflow onto unstructured chaos.
This isn’t about buying a single piece of software. It’s a fundamental shift in how a firm processes data from preservation to production.
Deconstructing the Ingestion and Processing Pipeline
The initial stage of any e-discovery matter is a chaotic data dump. You receive PST files from one custodian, a Slack JSON export from another, and a raw file share from a third. A manual approach involves technicians wrestling with each format individually, a slow and inconsistent process. An automated ingestion pipeline is built to normalize these disparate sources into a uniform, searchable format. We script workflows to strip container metadata, extract text and embedded objects, and map source fields to a standardized schema.
This is where most of the upfront engineering work lives.
The goal is to force every document, email, or chat message into a predictable structure. We use scripts to detect file types, route them to the correct text extraction engine, and handle the inevitable exceptions and corrupted files without halting the entire batch. This process generates detailed logs, creating a defensible audit trail from the moment data enters the system. Without this, you cannot prove chain of custody or processing integrity.
Text Extraction and Metadata Integrity
Every file carries two stories: its content and its metadata. Manual processing often degrades or destroys critical metadata fields like creation dates or author information. An automated system is configured to preserve these fields meticulously. We write rules to map, for example, the “Creation-Date” from a Word document’s EXIF data and the “Sent” time from an EML file header into a single, canonical “DocumentDate” field in the review database.
Losing this data cripples your ability to build a timeline.
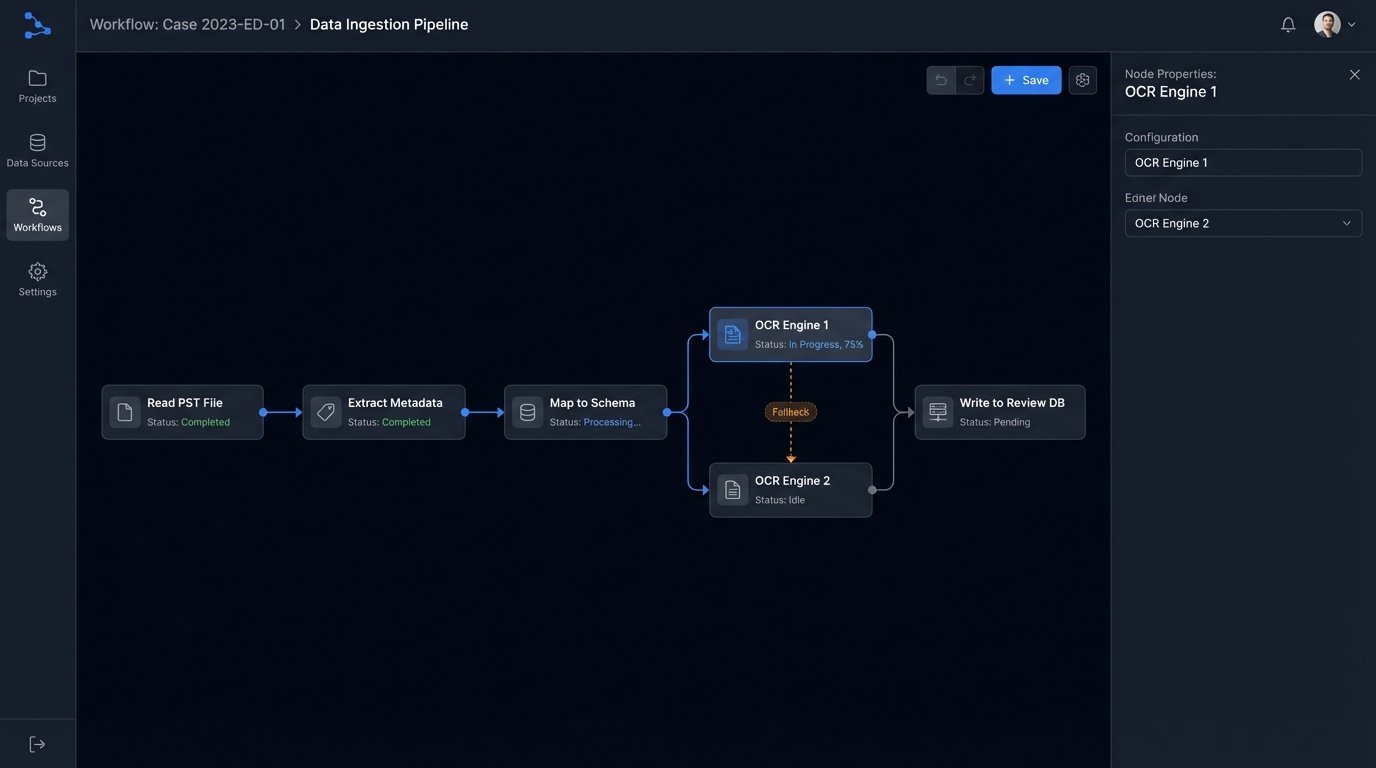
The text extraction process itself is another failure point. Different tools render text from a complex PDF or a password-protected spreadsheet with varying degrees of success. Automation allows us to chain multiple optical character recognition (OCR) and text extraction engines. If the primary engine fails or returns low-confidence text, the file is automatically re-routed to a secondary, more resource-intensive engine. This fallback logic maximizes text recovery without manual intervention.
Gutting the Linear Review Queue with Analytics
Technology Assisted Review (TAR), or predictive coding, is the engine that breaks the back of linear document review. The concept is straightforward: train a machine learning model on a small set of human-coded documents to predict the responsiveness of the remaining population. This is not a black box. The defensibility of TAR hinges on the transparency of the training process and the statistical validation of its results.
Your associates are not machine learning models. Stop using them like they are.
The process starts with a senior attorney reviewing a random sample of documents, coding them as responsive or non-responsive. This “seed set” is used to train a classification model. The model then scores every other document in the collection based on its probable relevance. Reviewers are then served documents with the highest relevance scores first, ensuring they are looking at the most critical information immediately. This is an iterative feedback loop. As reviewers code more documents, their decisions are fed back into the model, continuously refining its accuracy.
# Pseudocode for a basic TAR feedback loop
model = train_initial_model(seed_set)
document_queue = score_all_documents(corpus, model)
while model_accuracy < 0.95:
# Get the next batch of highest-scoring, unreviewed documents
review_batch = document_queue.get_next_batch(size=500)
# Human reviewers code the batch
human_decisions = human_review_interface(review_batch)
# Append new human decisions to the training set
training_set.append(human_decisions)
# Retrain the model with the new data
model = retrain_model(training_set)
# Recalculate model accuracy against a control set
model_accuracy = validate_model(model, control_set)
# Rescore the remaining unreviewed documents
document_queue.rescore(corpus, model)
print("TAR process complete. Final model accuracy:", model_accuracy)
This approach transforms document review from a brute-force marathon into a targeted, intelligence-driven exercise. Manually assembling this workflow is like trying to build a car engine from spare parts in the dark. You need a platform designed for this iterative logic.
Beyond Relevance: Email Threading and Near-Duplicate Detection
Analytics also automates the structural organization of data. Email threading algorithms identify the chain of replies and forwards, grouping them into conversations. This prevents reviewers from reading five different versions of the same message. Only the most inclusive email in a thread, along with any messages with unique attachments, needs to be reviewed. This alone can reduce the email review population by 20-40%.
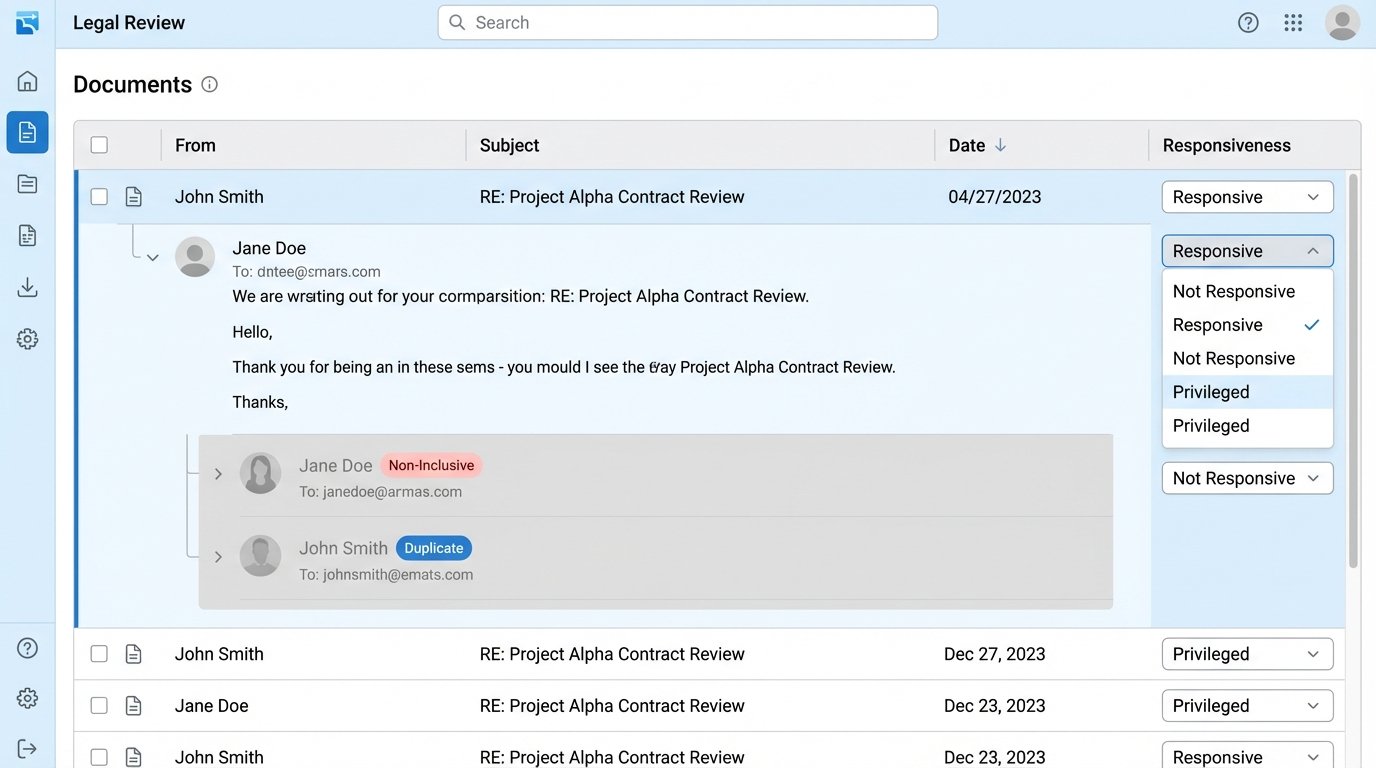
Near-duplicate detection is another computational workhorse. It identifies documents that are textually similar but not identical, like different drafts of a contract. By grouping these documents, a reviewer can look at the original, assess the differences in subsequent versions, and apply coding decisions to the entire group at once. This prevents inconsistent coding and saves an immense amount of time.
Automating Privilege Review and Log Generation
Identifying privileged documents is the most sensitive part of any review. It is also a wallet-drainer. Automating this process focuses on pre-culling the document set to minimize the amount of material that requires expensive partner-level review. We build complex search queries that flag documents containing names of attorneys, law firm domain names, or specific legal terminology.
These are not simple keyword searches. They are structured queries using regular expressions and proximity operators to identify patterns indicative of legal advice or work product. For example, a script can flag any document where a name from a predefined “Attorney List” appears within 50 words of terms like “legal advice,” “confidential,” or “work product doctrine.” This creates a high-priority queue for privilege review, leaving the rest of the population for a less intensive check.
Generating the Privilege Log
The privilege log is a notoriously painful deliverable to create manually. Automation tools can generate a draft log directly from the review database. When an attorney codes a document as privileged, the system can be configured to automatically pull the required metadata: author, recipients, date, and a pre-populated privilege reason based on the rules that flagged it. The attorney’s job then becomes validating and refining the log entries, not creating them from scratch.
This transforms a multi-week data entry project into a few days of quality control.
Building Defensible, Error-Free Production Sets
The final stage is producing the documents to the opposing party. A manual production process is a minefield of potential errors. Applying redactions, endorsing each page with a Bates number, and generating the correct load file format is exacting work. A single mistake, like producing a privileged document, can have catastrophic consequences for a case.
Automation imposes rigid quality control on this process. Production rules are configured once at the start. These rules dictate the Bates numbering format, the text of confidentiality endorsements, and the specific metadata fields to include in the load file. When the production set is finalized, the system executes these rules programmatically across thousands of documents in minutes. This is shoving a firehose through a needle, an operation that demands computational precision, not manual dexterity.
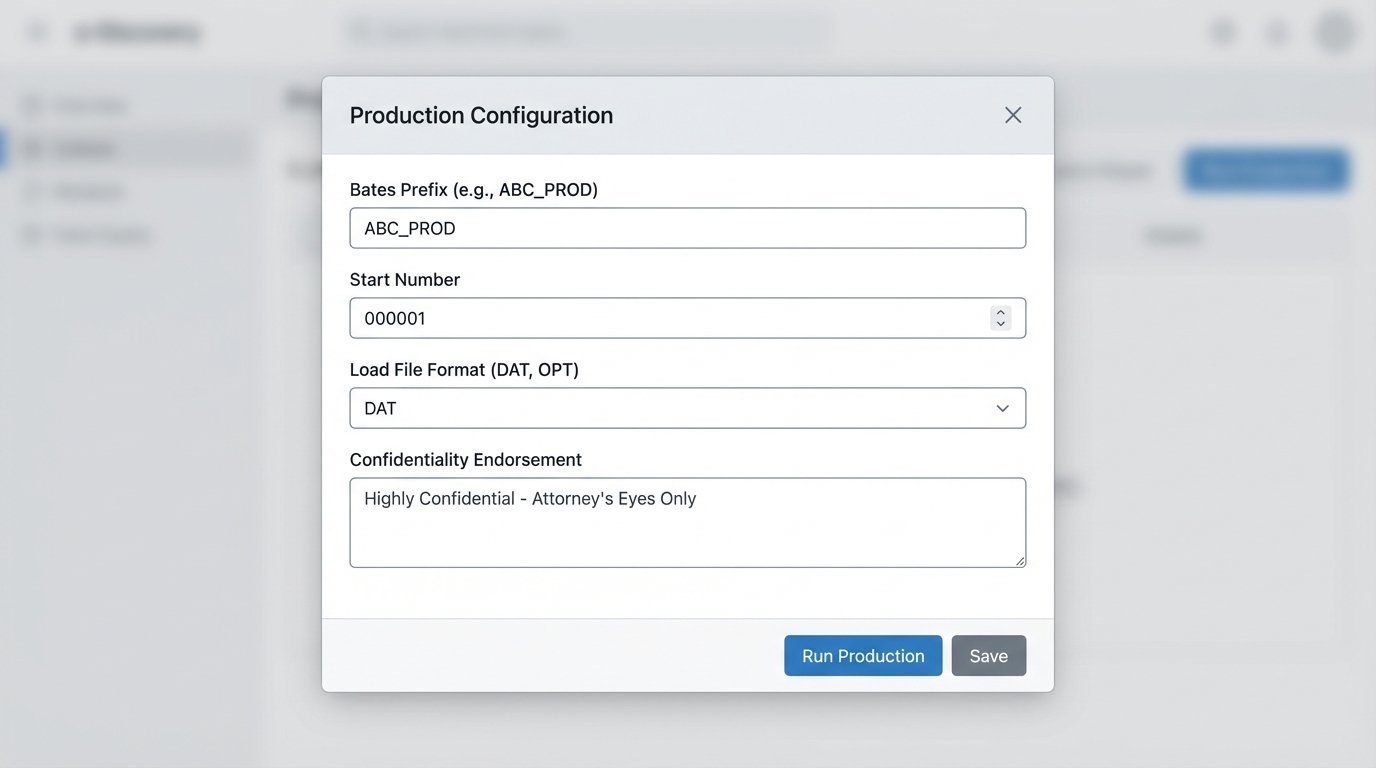
Every step is logged. The system records which documents were included, which redactions were applied, and the exact specifications of the generated load file. This creates an unimpeachable record of what was produced and how. If the opposing counsel claims a file is missing or a Bates number is skipped, you can point to the system logs to prove the integrity of your production.
Bridging Legacy Case Management Systems
Many firms run on older case management platforms with limited, often undocumented APIs. Automation projects frequently require building middleware to bridge these legacy systems with modern e-discovery tools. This often involves writing scripts to export data from the review platform into a generic format like CSV or XML, then transforming that data to match the import schema of the older system. It is not elegant, but it is necessary.
The documentation for that ten-year-old API is probably wrong. Plan for it.
The alternative is manual data entry, which is not a scalable solution. Investing in small, tactical integration scripts pays for itself by preventing the re-introduction of human error at the final stage of the process. This ensures that the coding decisions and metadata generated during the automated review are accurately reflected in the firm’s system of record.