
The legal tech market pitches AI as a replacement for the junior associate. This is a fundamental misunderstanding of the technology. Generative models are not knowledge-retrieval systems; they are probabilistic text generators that are exceptionally good at sounding plausible. Treating a large language model as a fact database is like using a grammar checker to verify the laws of physics. It can assemble a syntactically correct sentence about gravity, but it has no underlying model of mass or acceleration.
This core fallacy leads to dangerous implementations where firms pipe raw user queries directly to a model and present the output as verified legal research. The real, defensible role of AI in case law analysis is not as a front-end oracle but as a back-end data-processing engine. It is a tool for structuring unstructured data, identifying semantic relationships, and reducing the initial search space for a human expert. Anything else is malpractice waiting to happen.
Deconstructing the Standard Workflow: From Keywords to Vectors
Traditional legal research is a keyword-driven brute-force attack. You string together Boolean operators, pray your terminology matches the judge’s, and manually sift through hundreds of marginally relevant cases. It is a process of filtering a massive dataset based on exact string matches. The objective is to find the needle. The problem is you start with a continent of haystacks.
AI-driven analysis flips this model. Instead of matching strings, we match concepts. The process begins by gutting case law documents, stripping away headers, footers, and procedural boilerplate. The cleaned text is then broken into manageable chunks, typically a few paragraphs long. We are not just splitting a file; we are creating discrete units of legal reasoning that can be evaluated independently.
Each chunk is then converted into a high-dimensional vector, a numerical representation of its semantic meaning. This is done via an embedding model. The result is a massive collection of vectors stored in a specialized database, a vector database, that can calculate the “distance” or “similarity” between them. A query is no longer a set of keywords; it is its own vector. The system returns the chunks whose vectors are closest to the query vector.
This is a computationally expensive but conceptually direct way to find relevance. It bypasses the keyword problem entirely.
The Brittle Nature of Pure Vector Search
A pure vector search is a powerful tool for finding conceptually similar documents. If you ask about “corporate liability for faulty products,” it will find cases that discuss “manufacturer negligence” and “enterprise accountability for defects,” even if the exact query words are absent. This is its primary strength.
Its primary weakness is a lack of precision. Vector search struggles with specifics: case numbers, specific statutes, names, and legal terms of art that have no semantic synonym. The model might see “res ipsa loquitur” as conceptually similar to “obvious negligence,” but a litigator needs the document that contains the specific Latin phrase. It smooths over the sharp edges of legal language, which is often where the entire argument lies.
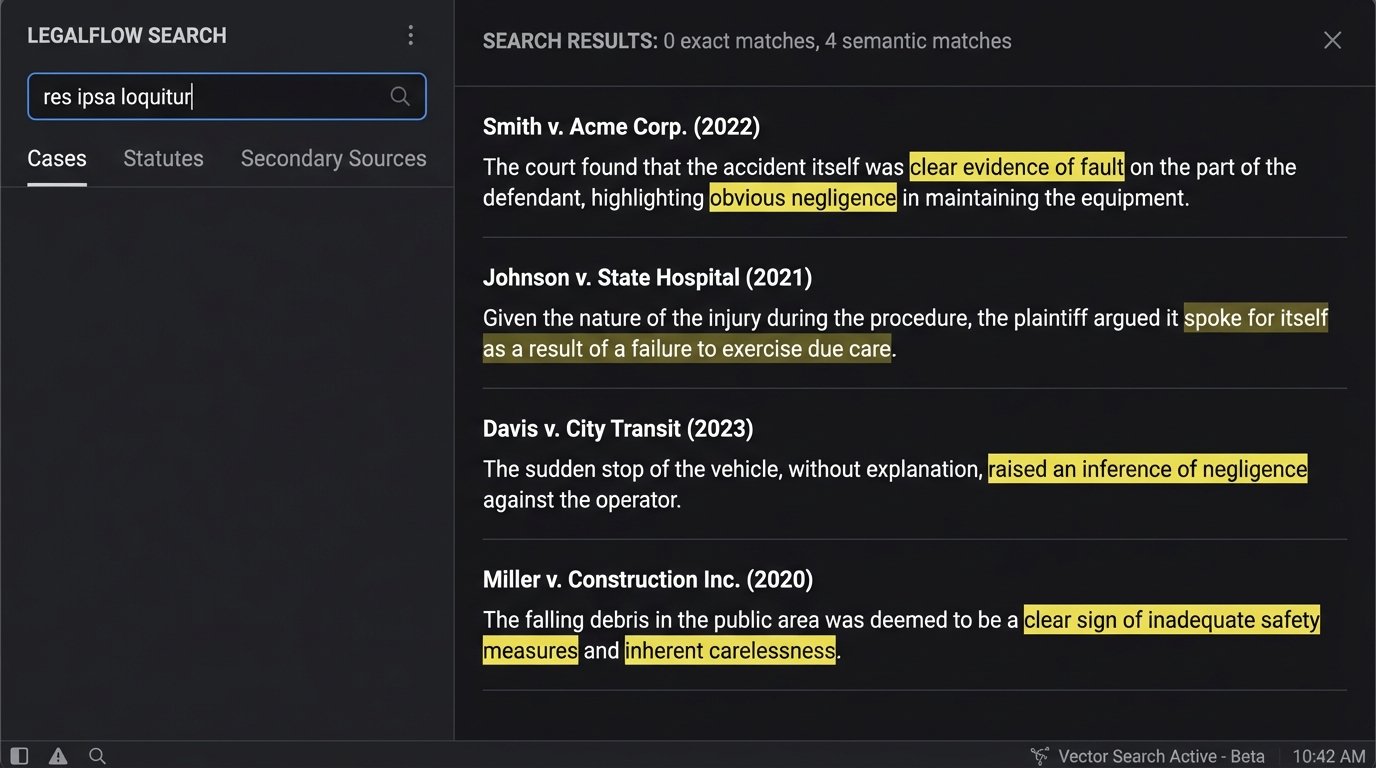
Furthermore, the entire system’s effectiveness is shackled to the quality of the embedding model. If the model was trained on a general web corpus, it will lack the domain-specific understanding of legal terminology. It might map “discovery” closer to the space shuttle than to the legal process of exchanging information. Using an off-the-shelf embedding model without fine-tuning is an exercise in generating noise.
You are trading the tyranny of the keyword for the ambiguity of the vector.
Building a Hybrid Search Engine: The Only Defensible Approach
A functional, reliable system does not force a choice between keyword and vector search. It uses both. A hybrid architecture first runs a query through a traditional keyword search index (like BM25) to retrieve documents with exact-match terms. It then runs the same query through a vector search index to find semantically related documents. The results are then combined and re-ranked to produce a single, unified list.
This architecture provides a crucial backstop. It ensures that specific, must-have terms are respected while still allowing for the conceptual discovery that vector search enables. The keyword search anchors the results in facts and specifics, while the vector search explores the periphery for related ideas the researcher might not have considered.
Implementing this requires maintaining two separate indexes for the same source data. One is a classic inverted index for keywords, and the other is a vector index. Query logic becomes more complex, as you need a re-ranking algorithm to merge the two result sets intelligently. You might weigh the keyword results higher for queries heavy with proper nouns or citations, and weigh the vector results higher for broad, conceptual queries.
{
"caseId": "CV-2023-987123",
"chunkId": 42,
"sourceText": "The doctrine of respondeat superior holds an employer vicariously liable for the wrongful acts of an employee...",
"metadata": {
"court": "Ninth Circuit",
"citation": "452 F.3d 1040",
"date": "2023-05-18"
},
"embedding_vector": [0.012, -0.045, ..., 0.089]
}
The above JSON object shows a simplified schema for a single chunk ready for indexing. It contains the raw text, the critical vector, and filterable metadata. The metadata is the key to bridging the gap. It allows you to run a vector search and then apply hard filters, for example, “find concepts related to ‘respondeat superior’ but only in cases from the Ninth Circuit after 2020.”
This is how you build a precision tool, not a search grenade.
Retrieval-Augmented Generation (RAG): Summarization with Guardrails
Once the hybrid search retrieves a set of relevant case law chunks, the next step is often summarization. This is where generative models like GPT-4 are genuinely useful, but they cannot be left unchecked. The technique to control them is Retrieval-Augmented Generation, or RAG.
Instead of just asking a model, “Summarize the findings on corporate liability from these cases,” you construct a highly specific prompt. This prompt injects the retrieved text chunks directly into the context window along with the original query. The instruction becomes: “Using ONLY the following provided text, summarize the key arguments related to corporate liability.”
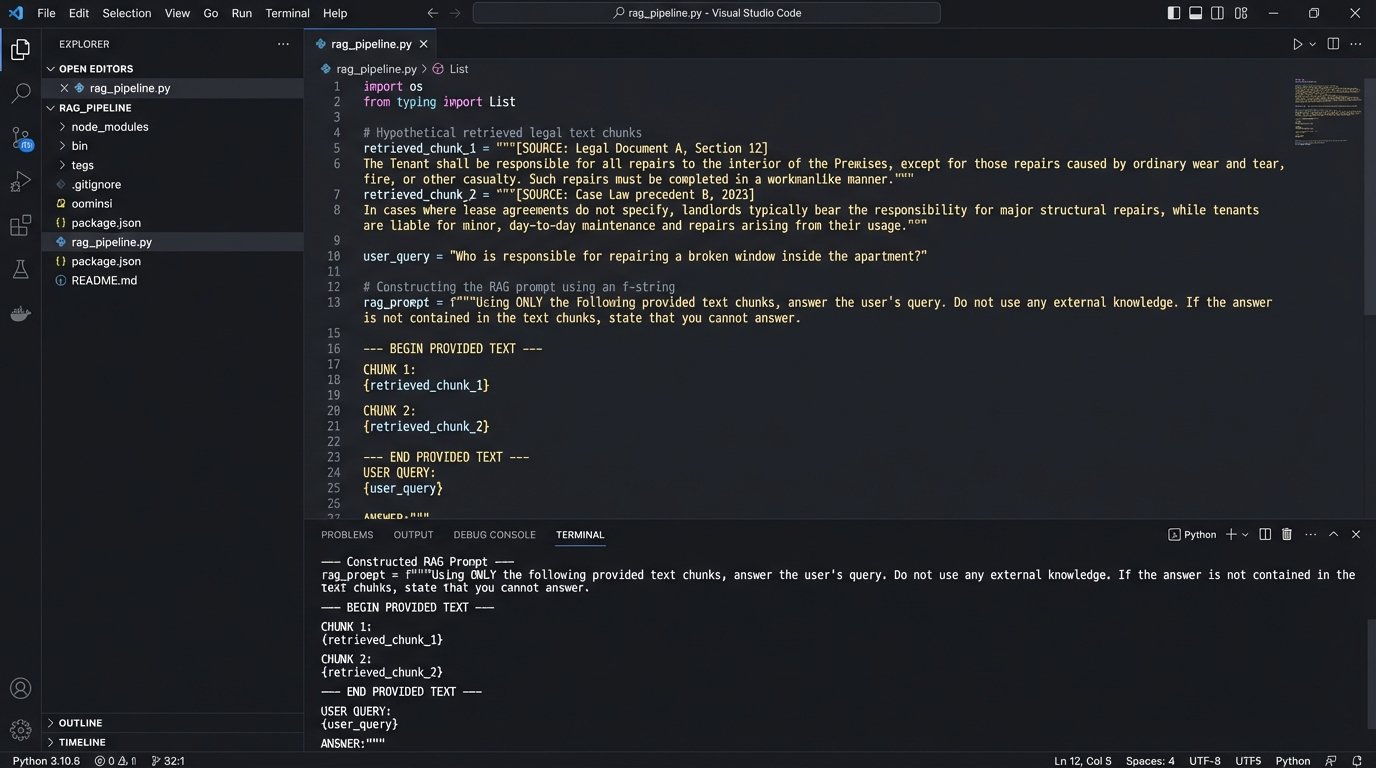
This forces the model to ground its answer in the source material you provided. It dramatically reduces the risk of “hallucination,” where the model invents facts or citations. The model’s role shifts from a know-it-all oracle to a sophisticated text-processing engine that can synthesize information from a trusted, pre-vetted source. It is the difference between an open-book and a closed-book exam.
The process is straightforward:
- User submits a query.
- The hybrid search engine retrieves the top N relevant text chunks.
- A prompt is programmatically constructed, stuffing these chunks and the original query into the model’s context.
- The model generates a summary based only on that context.
- The summary is presented to the user along with direct links to the source chunks.
Every single statement in the generated summary must be traceable back to a specific piece of retrieved text. Without that traceability, the output is legally worthless.
The Ugly Reality of Integration and Maintenance
Building this pipeline is not a one-off project. The value of a case law analysis system decays over time if it is not maintained. New case law is published daily. This requires a robust data ingestion pipeline that can monitor sources, download new documents, clean them, chunk them, embed them, and update two separate search indexes.
This is a constant, resource-intensive process. The API calls for embedding millions of document chunks are a significant operational expense. A popular model like OpenAI’s `text-embedding-ada-002` is cheap per-call, but the cost scales linearly with the volume of your document library. Vector databases are not cheap to host and require specialized expertise to tune for performance.
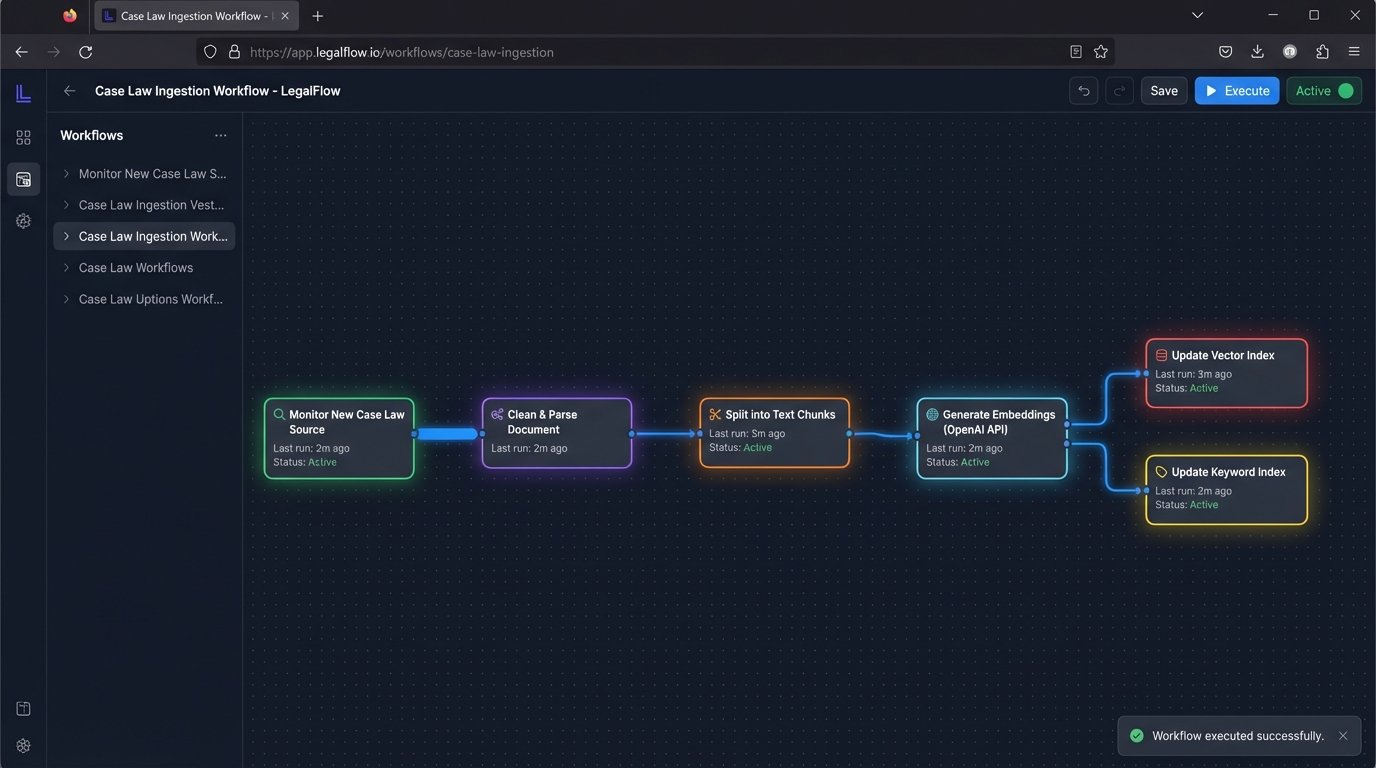
Integration with existing platforms is another nightmare. Most law firms run on legacy Case Management Systems (CMS) with rigid APIs, if they have APIs at all. Shoving the output of your new AI tool back into these systems often involves writing brittle screen-scraping scripts or batch-file exports. You might build a state-of-the-art search engine only to find the final step is a “generate PDF and email it to the paralegal” button because the CMS cannot accept the data directly.
The total cost of ownership is not the software license. It is the salary of the engineers required to babysit the data pipelines, the cloud hosting bills for the indexes, and the API token budget that gets consumed every time a new case is published. The advertised time savings for attorneys must be weighed against the very real and recurring engineering costs.
The promise of a simple search box hides a complex and expensive back-end infrastructure. That is the part the sales team never puts on their slides.