
The entire conversation around AI in case law research is stuck on a fantasy. The marketing pitches promise a digital oracle that digests a case file and spits out a winning motion. The reality is a set of glorified search filters bolted onto decade-old databases. These tools are faster, but they do not change the fundamental, brute-force mechanics of legal research. They still rely on you, the human, to bridge the conceptual gaps that keyword matching can never cross.
The real transformation is not about finding documents faster. It is about deconstructing them into quantifiable, relational data points. It is about turning a library of unstructured text into a queryable graph of legal logic. This is not a plug-and-play software update. It is a fundamental shift in infrastructure that most firms are completely unprepared to build or manage.
The Brittle Foundation of Boolean Search
For decades, legal research has been anchored to Boolean logic and keyword searching. We string together terms with AND, OR, and NOT, hoping the syntax correctly captures legal nuance. This system is functional but incredibly brittle. It operates on the explicit presence of words, not on the implicit meaning or concepts they represent. A search for “corporate veil piercing” might miss a pivotal ruling that discusses “alter ego liability” if the exact keyword phrase is absent.
This method forces the attorney to act as a human thesaurus, brainstorming every possible synonym and permutation of a legal concept. The process is inefficient and prone to gaps. You find what you explicitly ask for, and nothing more. The risk of missing a dispositive case because it was phrased unconventionally is always present.
Every major legal research platform is built on this aging foundation. Their “AI” features are often just layers of Natural Language Processing (NLP) that attempt to guess your intent and suggest better keywords. It’s a patch, not a solution. It makes a bad system slightly more tolerable.
Vectorization: The Engine for Conceptual Analysis
The first real architectural shift is moving away from keyword indexing to vector embeddings. This process guts the old search model entirely. Instead of indexing words, a machine learning model converts entire documents, paragraphs, or sentences into a multi-dimensional array of numbers called a vector. This vector represents the semantic, or conceptual, meaning of the text. The specific words become less important than their collective context.
Documents with similar meanings will have vectors that are mathematically close to each other in this multi-dimensional space. A search query is also converted into a vector. The system then finds the documents whose vectors are closest to the query vector. This is called semantic search or vector search. It finds results based on conceptual relevance, not keyword density.
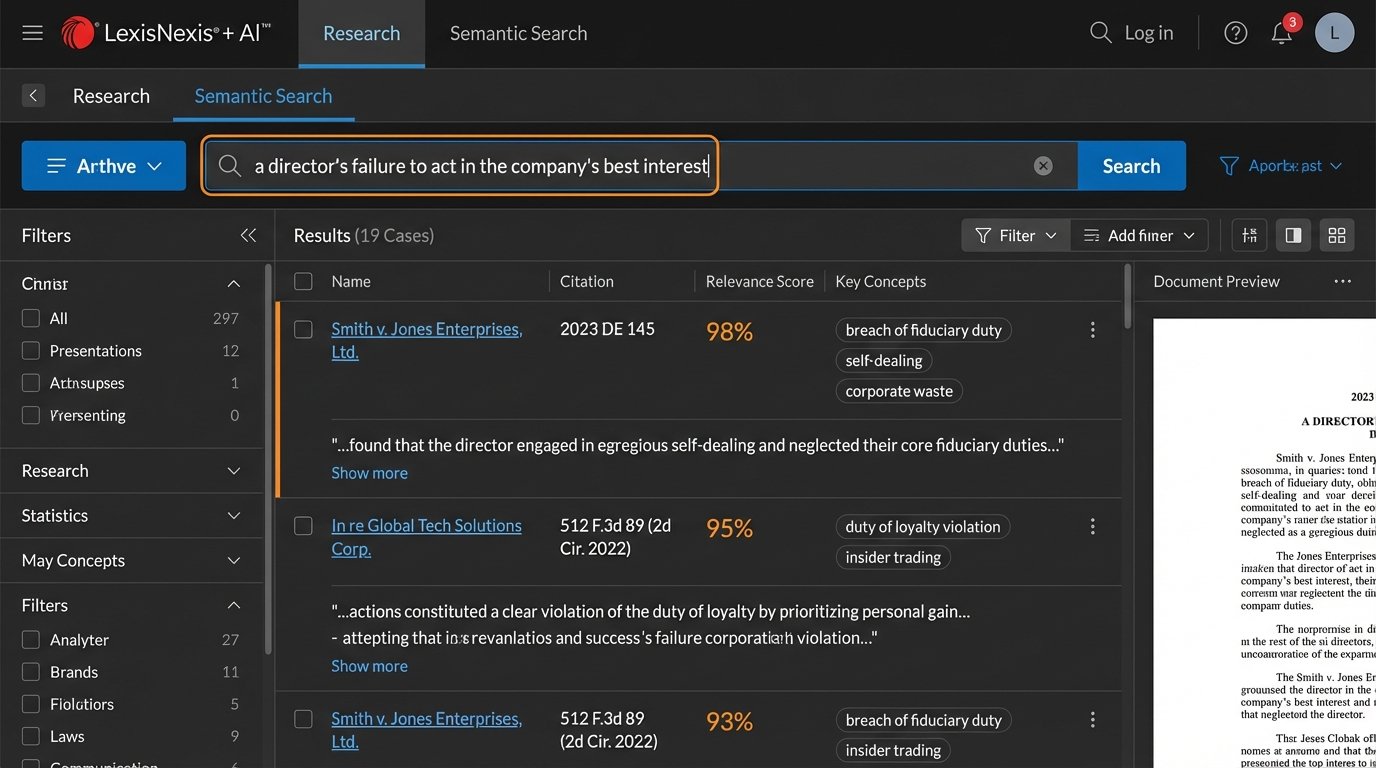
This is not a theoretical concept. It is the core technology behind modern recommendation engines and image search. In a legal context, it means you can search for the concept of “a director’s failure to act in the company’s best interest” and find cases that discuss “breach of fiduciary duty,” “self-dealing,” or “corporate waste,” even if your exact search terms never appear. The model understands the relationships between these ideas.
Implementing this requires a vector database, a specialized system designed to store and query these high-dimensional data points efficiently. Think Pinecone, Milvus, or Weaviate. This is not your standard SQL server. It is a new piece of the technology stack that needs to be managed, secured, and scaled.
Connecting Vectors to Generative Models
Generative AI, like GPT-4, is powerful but dangerous when used in isolation for legal work. Asking a public model to “find cases supporting my argument” is an invitation for it to invent, or “hallucinate,” citations. The models are not databases of truth. They are prediction engines that assemble statistically probable text. They have no concept of legal validity.
The correct architecture bridges a high-quality vector search with a generative model. The workflow is sequential and controlled.
- Step 1: Embed and Search. The user’s query is converted into a vector. Your system performs a semantic search against your private, curated vector database of case law. This returns a list of the top 10 or 20 most conceptually relevant case text blocks.
- Step 2: Inject Context. These text blocks are injected directly into the prompt for a large language model (LLM). You are not asking the model a general question. You are giving it a specific, pre-vetted corpus of text and instructing it.
- Step 3: Constrained Synthesis. The prompt instructs the LLM to “Summarize the key arguments from the following texts only” or “Based on the provided case excerpts, identify the common legal standard for negligence.”
This technique, known as Retrieval-Augmented Generation (RAG), dramatically reduces the risk of hallucination. The LLM is forced to ground its response in the specific, verifiable sources you provided. Its job shifts from “knowing” to “synthesizing.” The quality of the output is now a direct function of the quality of your vector search results. Garbage in, synthesized garbage out.
A Simplified Data Structure
To make this concrete, imagine what a vectorized case snippet might look like in a system. It is not just the text. It is the text accompanied by its vector and critical metadata for filtering.
{
"case_id": "civ-2023-4589",
"citation": "123 F. Supp. 3d 456",
"court": "S.D.N.Y.",
"judge": "John E. Doe",
"chunk_id": "p_12",
"text": "The court finds that the defendant's actions constituted a clear breach of fiduciary duty, as the transactions were not disclosed to the board...",
"text_vector": [0.021, -0.345, ..., 0.189],
"keywords": ["fiduciary duty", "disclosure", "board"],
"outcome": "summary_judgment_granted"
}
This structure allows you to perform hybrid searches. You can do a semantic search for a concept using the `text_vector` and then filter the results by court, judge, or outcome using the metadata. This is far more powerful than a simple keyword search bar.
The Proprietary Advantage: Your Firm’s Knowledge Graph
Relying solely on vendors for this technology is a path to commoditization. Every firm will have access to the same tools and the same public case law data. The durable competitive advantage comes from vectorizing your firm’s own private data, your work product. This includes briefs, memos, motions, deposition transcripts, and expert reports.
The objective is to build an internal, private knowledge graph that bridges public case law with your firm’s unique experience and analysis. When a new associate searches for precedents on a specific trade secret issue, the system should return not only public court opinions but also the firm’s own successful summary judgment motion from three years ago on a similar case, along with the partner’s internal memo analyzing the judge’s prior rulings. Trying to connect these systems with off-the-shelf middleware is like trying to plumb a skyscraper with a garden hose. You will get water on the first floor, but the rest of the structure remains dry and useless.
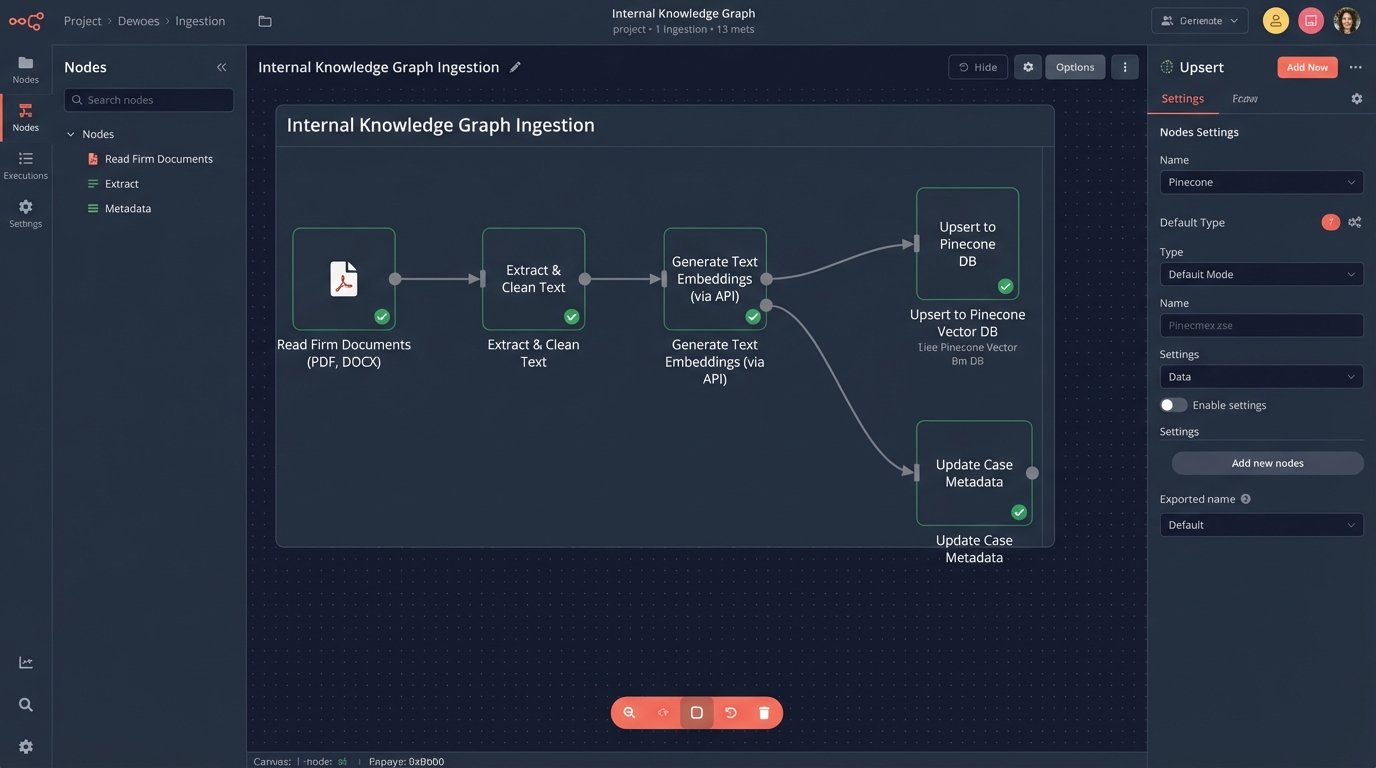
Building this is a data engineering project. It requires setting up a pipeline to extract text from Word documents, PDFs, and your case management system. It demands a rigorous process to clean and normalize that text, stripping out irrelevant formatting and boilerplate. Then, you must run it through an embedding model and load it into your private vector database with rich metadata. This is not a weekend project.
The Emerging Role of the Legal Data Engineer
This technological shift forces a change in legal team composition. The classic role of the junior associate or paralegal spending days in a research database will diminish. Their time is too expensive to be spent on tasks that a well-tuned algorithm can perform in seconds. A new role is needed: a hybrid legal data analyst or engineer.
This person understands both the legal concepts and the data architecture. Their job is not to find the needle in the haystack. Their job is to build a better haystack. They are responsible for curating the datasets, evaluating the quality of the semantic search results, and fine-tuning the prompts used for synthesis. They validate the AI’s output, checking the generated summaries against the source texts to ensure accuracy and fidelity. They become the keepers of the firm’s institutional knowledge, ensuring it is structured, queryable, and leveraged effectively.
The Uncomfortable Financial Reality
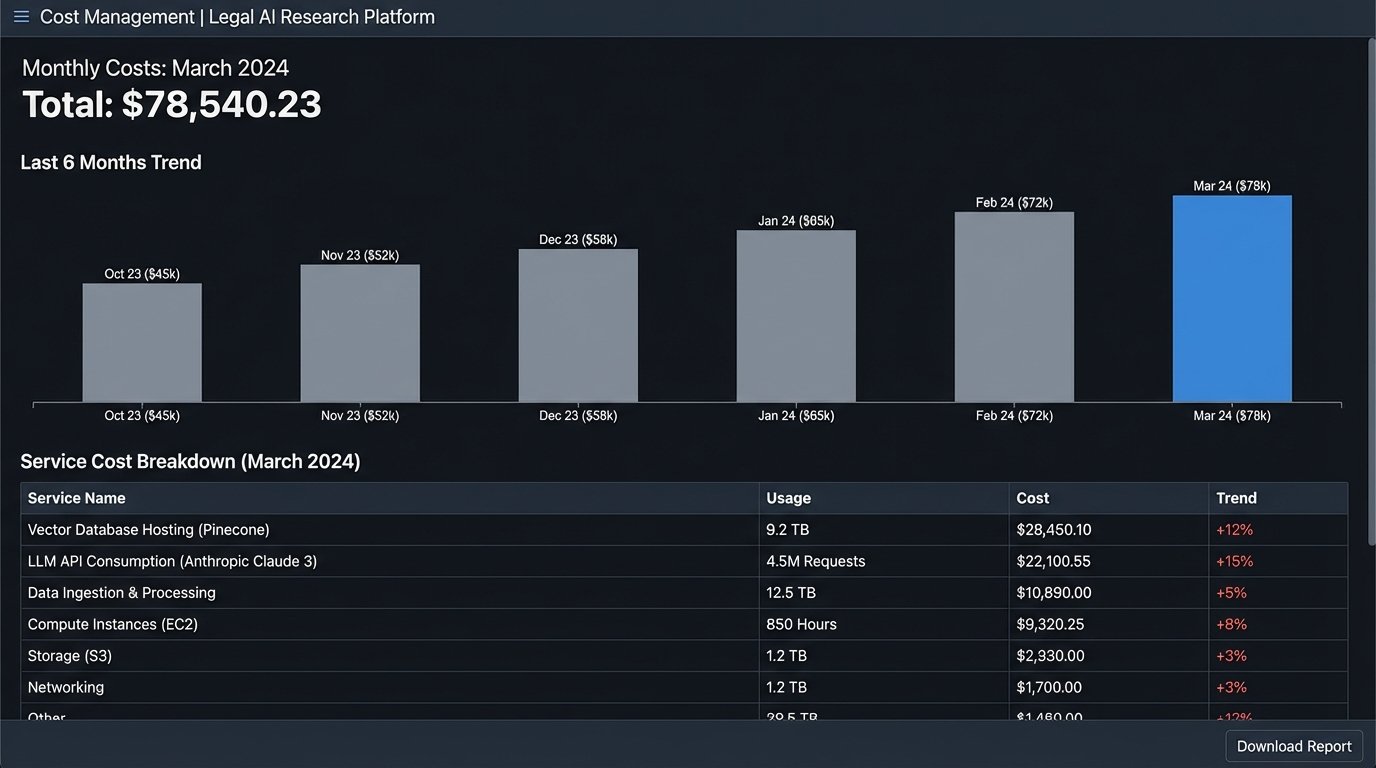
Implementing a proprietary research system is a significant capital and operational expense. The marketing from AI startups often hides the true total cost of ownership behind a simple per-seat license fee. That fee is just the entry ticket.
Here is a more realistic breakdown of the costs:
- Data Infrastructure: Hosting a vector database and the servers to run embedding models is not cheap. Doing this in a secure cloud environment that meets client data security requirements adds another layer of cost and complexity.
- API Consumption: Every query to a powerful generative model like those from OpenAI, Anthropic, or Cohere costs money. A firm with hundreds of lawyers running complex synthesis tasks can rack up a five or six-figure API bill every month.
- Engineering Talent: The legal data engineers and machine learning specialists needed to build and maintain these systems command high salaries. They are a permanent addition to the firm’s headcount, not temporary consultants.
- Data Ingestion and Cleaning: The initial project to process decades of the firm’s documents is a massive, one-time effort. Ongoing maintenance to process new documents is a perpetual operational task.
There is also a performance cost. A poorly configured vector search can be sluggish, returning irrelevant results that erode user trust. The system requires constant tuning and evaluation. It is not a “set it and forget it” appliance.
Firms face a clear choice. They can continue to rent commoditized tools from the big legal tech vendors, which will offer a baseline level of AI-powered search. Or they can invest in building a proprietary data asset that compounds in value over time. The first option is cheaper and easier. The second creates a defensible moat that cannot be easily replicated by competitors.
The future of case law research is not another subscription service. It is an in-house data intelligence platform. The firms that recognize this and begin the slow, expensive work of building that platform now will hold a decisive advantage. The rest will be left wondering how their competitors seem to know things they do not.