
The core problem in case law analysis is not retrieval. It is signal degradation. Decades of keyword-based systems have trained legal teams to accept a 95 percent noise-to-signal ratio as standard operating procedure. We sift through mountains of irrelevant documents, hoping to find a handful of on-point cases, burning associate hours to compensate for the technical debt of primitive search algorithms. This entire workflow is a patch for a fundamentally broken data access model.
Boolean search, the bedrock of Westlaw and Lexis for a generation, is a brittle instrument. It forces a lawyer to guess the exact phrasing a judge might have used. It has no concept of intent or semantic similarity. Searching for “corporate veil piercing” will miss a pivotal opinion that discusses “disregarding the corporate form” if the first phrase is absent. It is a system built on exact string matching in a profession that thrives on nuanced interpretation.
This forces a dependency on human middleware. An army of researchers executes dozens of query variations, manually aggregates the results, and then reads through hundreds of documents. The process is slow, expensive, and prone to error. It is not research. It is a brute-force attack on a poorly indexed dataset.
Deconstructing the Legacy Stack
Legacy case law platforms operate on an architecture designed for a different era of computing. At their heart is an inverted index, a data structure that maps content, like words or numbers, to its locations in a database. When you run a keyword search, the system performs a simple lookup in this index, retrieves a list of document IDs, and returns the corresponding text. It is fast for exact matches but entirely ignorant of context.
The logic is rigid. A query like "intellectual property" AND ("software patent" OR "business method patent") NOT "pharma" is just a set of logical operations on document tags. The system has no understanding that “IP” is related to “intellectual property” or that “pharmaceutical” is related to “pharma”. It only knows what it is explicitly told. This leaves the cognitive load of bridging conceptual gaps entirely on the user.
Attempts to fix this with “smart” features are often just layers of curated synonyms and taxonomies bolted onto the old index. These are manual, expensive to maintain, and always incomplete. They are a patch, not a solution. The underlying engine remains the same, forcing you to think like a machine instead of having a machine that understands your intent.
The Real Cost is Inefficiency, Not Subscription Fees
The visible cost is the monthly subscription. The invisible, and far larger, cost is the payroll hours spent wrestling with the system’s limitations. Every hour a paralegal or junior associate spends refining keyword queries and filtering irrelevant results is a direct, unrecoverable drain. These tasks are low-value and are a direct result of inadequate tooling. The firm bills for this time, but it builds a foundation of operational drag that erodes profitability.
This inefficiency creates a secondary risk. When faced with tight deadlines, the temptation is to stop after finding one or two “good enough” cases instead of the best cases. The limitations of the search tool directly impact the quality of the legal work product. An argument can be lost because a superior, but oddly phrased, precedent was never surfaced by a keyword-dependent query.
We have to gut the assumption that the researcher’s primary job is to formulate the perfect query. The researcher’s job is to analyze the law. The system’s job is to deliver the relevant law, regardless of how the query is phrased. This requires a fundamental shift in the underlying technology from lexical matching to semantic understanding.
The Architectural Pivot: From Keywords to Vectors
The alternative is to stop treating legal text as a simple bag of words and instead treat it as a collection of concepts. This is achieved by converting text into numerical representations called vector embeddings. An embedding model, a type of neural network, reads a chunk of text, a paragraph, or an entire document, and outputs a list of numbers, a vector, that captures the semantic essence of that text.
This process moves legal data from the discrete world of words into a continuous, high-dimensional vector space. In this space, proximity equals similarity. A paragraph discussing “an employee’s duty of loyalty” will be located mathematically close to another paragraph discussing “fiduciary responsibilities of an agent,” even if they share no keywords. This is the critical leap. We are no longer searching for strings. We are searching for meaning.
The pipeline for this is straightforward in concept but demands precision in execution. First, you strip and chunk source documents, case law, statutes, or internal memos, into digestible pieces. Second, you push each chunk through an embedding model to generate a vector. Third, you store these vectors and their corresponding text in a specialized vector database. Now, your entire legal corpus is a queryable, mathematical map of concepts.
This is not a simple database operation. It is about building a system that can navigate legal nuance at a massive scale. It’s the difference between using a dictionary to find a word and using an encyclopedia to understand a topic. One is a lookup, the other is a knowledge retrieval system.
Building the Retrieval-Augmented Generation (RAG) Pipeline
Once you have a vector database, the retrieval process is inverted. A user’s natural language query, “What constitutes a breach of fiduciary duty in a tech startup context?”, is itself converted into a vector. The system then performs a similarity search, a nearest-neighbor lookup, within the vector database. It pulls the top N text chunks whose vectors are closest to the query vector.
These retrieved chunks of text provide grounded, verifiable context. The next step in a modern stack is to inject this context into a prompt for a Large Language Model (LLM). The LLM is instructed to synthesize an answer to the original query using *only* the provided text snippets. This is Retrieval-Augmented Generation (RAG). It forces the LLM to act as a summarizer and synthesizer of retrieved facts, not as a generator of its own knowledge, which dramatically reduces the risk of hallucination.
Here is a conceptual Python snippet showing the core logic using a hypothetical SDK. This is not production code, it is an illustration of the data flow.
from legal_search_sdk import VectorDB, EmbeddingClient, LLMClient
# Initialize clients (API keys and endpoints configured elsewhere)
vector_db = VectorDB()
embedding_client = EmbeddingClient()
llm_client = LLMClient()
query_text = "What precedents exist for piercing the corporate veil due to undercapitalization?"
# 1. Embed the user's query
query_vector = embedding_client.embed(query_text)
# 2. Retrieve relevant text chunks from the vector database
retrieved_chunks = vector_db.similarity_search(vector=query_vector, k=5)
# 3. Build a prompt for the LLM, injecting the retrieved context
prompt = f"""
Answer the following question based ONLY on the provided context.
Cite the source for each point.
Context:
{retrieved_chunks[0].text} (Source: {retrieved_chunks[0].source})
{retrieved_chunks[1].text} (Source: {retrieved_chunks[1].source})
{retrieved_chunks[2].text} (Source: {retrieved_chunks[2].source})
...
Question: {query_text}
Answer:
"""
# 4. Generate a grounded answer
response = llm_client.generate(prompt)
print(response.text)
The strength of this architecture is its transparency. You can inspect the retrieved chunks to sanity-check the LLM’s output. If the summary is odd, you can see the source material it used. It provides a chain of evidence that is absent when you interact directly with a black-box LLM.
This is not a magic bullet. The quality of the output depends entirely on the quality of the chunks, the power of the embedding model, and the intelligence of the prompt. A failure in any one of these components will produce garbage.
The Hard Parts: Data Hygiene and Model Selection
Building a vector index is not a one-time event. The source data from courts is notoriously messy. PDFs are scanned poorly, metadata is missing or incorrect, and formatting is inconsistent. A significant portion of any project is spent building a robust ETL (Extract, Transform, Load) pipeline to clean and structure this data before it ever sees an embedding model.
The chunking strategy is another critical failure point. If you chunk by a fixed number of characters, you risk splitting a sentence or a key legal argument in half, destroying its context. Smarter chunking strategies operate on logical boundaries like paragraphs or sections, and sometimes use overlapping windows to ensure a complete thought is captured. Getting this wrong means your retrieval system will return useless, fragmented snippets.
Model selection presents its own challenges. Do you use a closed-source API like OpenAI’s `text-embedding-3-large` for ease of use and top-tier performance, accepting the data privacy implications and per-token cost? Or do you host an open-source model like those from the MTEB leaderboard, which gives you data sovereignty but requires managing GPU infrastructure and dealing with a potentially less capable model?
Each path has deep operational consequences. The API route is a persistent operational expense and ties you to a vendor. The self-hosted route is a capital expense and requires specialized in-house talent. There is no easy answer here, only a series of engineering decisions with different consequences.
Beyond Simple Retrieval: Knowledge Graphs and Temporal Analysis
A mature system moves beyond simple Q&A. By extracting entities, like case names, judges, and statutes, from the text during the ingestion process, you can start to build a knowledge graph. This graph connects cases that cite each other, judges who rule on similar topics, and the evolution of statutory interpretation. The vector search finds the documents, but the knowledge graph illuminates the relationships between them.
This enables far more sophisticated queries. You can ask the system to “show me all cases where Judge Smith cited *Marbury v. Madison* in a First Amendment context.” This query combines semantic search (First Amendment context) with structured, entity-based filtering. It is a level of analytical power that is impossible with a simple keyword index.
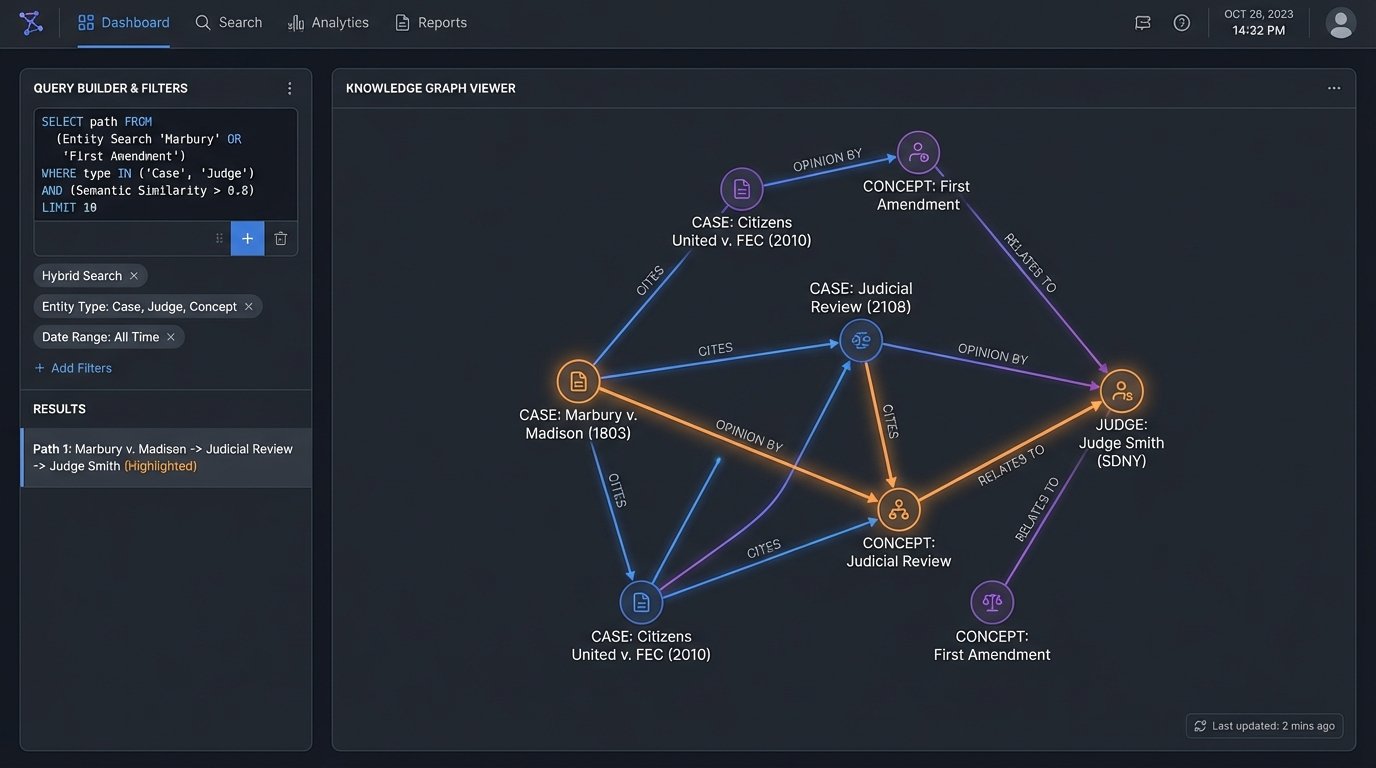
Temporal analysis becomes possible. By indexing cases with their decision dates, you can trace the lineage of a legal doctrine. You can ask for a summary of the arguments around a specific legal test before and after a landmark Supreme Court ruling. The system can then retrieve and synthesize arguments from two distinct time periods, providing a powerful analysis of doctrinal shifts.
This is not an out-of-the-box feature. It requires a significant investment in data modeling and a hybrid search architecture that can query both the vector space for semantic meaning and a graph database for structured relationships. It is difficult, but it is where the real value is unlocked.
The tooling exists, but it will not assemble itself. These systems are not about replacing legal expertise. They are about building a data-driven scaffold to augment it. The work is in the architecture, the data pipelines, and the constant, skeptical validation of the output. Believing the machine without checking its work is just a faster way to commit malpractice.