
Most conversations about AI in litigation begin with a fundamental error. They assume a singular, intelligent system that ingests case files and outputs a winning strategy. The reality is a fractured ecosystem of narrowly-focused models, brittle APIs, and data normalization scripts held together with the digital equivalent of duct tape. Success isn’t about buying the right platform. It’s about the brutal, unglamorous work of engineering a data pipeline that can feed these disparate tools without collapsing.
The core challenge is not the sophistication of the AI, but the abysmal state of the source data. Your case management system, your document repositories, your billing software. These are not clean, structured databases. They are data graveyards, filled with unstructured text, inconsistent metadata, and years of manual entry errors. Before any model can predict an outcome or analyze evidence, that data must be extracted, cleaned, and forced into a uniform schema. This is a data engineering problem, not a legal one, and it’s where most projects die.
Deconstructing Predictive Outcome Modeling
Predictive analytics vendors promise to forecast case outcomes by analyzing historical data. They build models based on factors like jurisdiction, judge, case type, and key legal motions. The technical foundation for this is typically a classification algorithm, like a gradient-boosted tree or a simple logistic regression model, trained on thousands of past dockets. The model learns to associate certain input features with specific outcomes, such as “summary judgment granted” or “settled.”
The marketing pitch obscures the statistical sausage-making. These models are dangerously sensitive to the quality of their training data. If your firm’s historical case data is poorly tagged or incomplete, the model’s predictions are worthless. It will confidently produce garbage. The model has no concept of legal nuance; it only recognizes statistical correlations in the data it was fed. A model trained on federal court data will perform terribly on state-level cases due to different procedures and precedents.
We are forced to build an aggressive feature engineering process to even get started. This involves writing scripts to strip key information from raw text documents. For example, we might use regular expressions or a Named Entity Recognition (NER) model to identify motions, judges, and law firms from docket sheets. This extracted, structured data becomes the input for the predictive model.
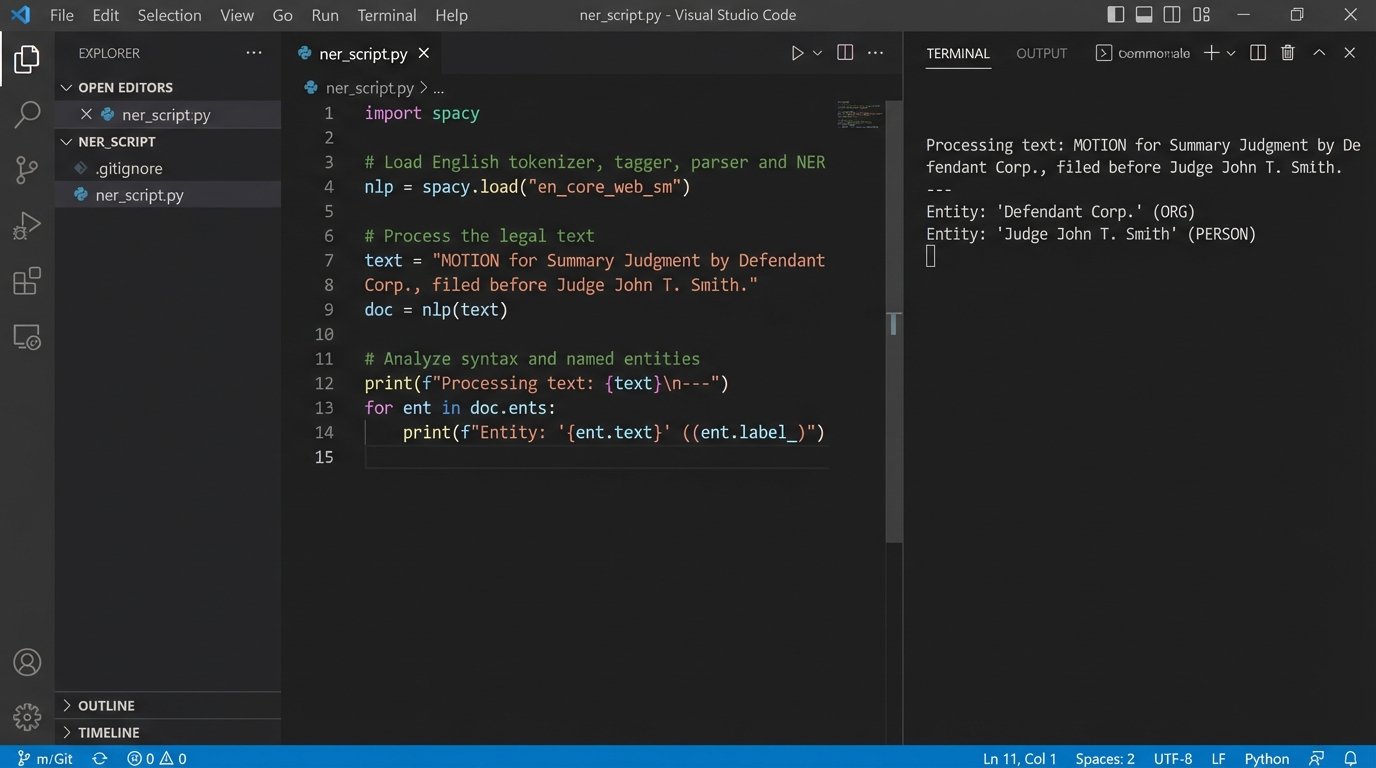
Here’s a simplified Python example using a library like spaCy to pull entities from a sample docket entry. This is the first, basic step in turning unstructured text into something a machine can analyze.
import spacy
# Load a pre-trained model
nlp = spacy.load("en_core_web_sm")
text = "MOTION for Summary Judgment by Defendant Corp. Assigned to Judge John T. Smith. Response due 11/30/2023."
doc = nlp(text)
# Extract entities the model recognizes
for ent in doc.ents:
print(f"Entity: {ent.text}, Label: {ent.label_}")
# Expected output might be:
# Entity: Defendant Corp., Label: ORG
# Entity: John T. Smith, Label: PERSON
# Entity: 11/30/2023, Label: DATE
This snippet only finds generic entities. A production system requires custom models trained to recognize legal-specific terms like “Motion to Compel” or “Daubert Motion.” Building and maintaining these custom models is a continuous, expensive process.
The Overfitting Trap
A primary risk is overfitting. An overfit model learns the noise and random fluctuations in the training data, not the underlying patterns. It performs exceptionally well on past cases it has already seen but fails spectacularly when presented with a new, unseen case. It’s like a student who memorizes the answers to last year’s test but cannot solve a new problem.
To fight this, we have to enforce rigorous cross-validation techniques. We split the historical data, training the model on one subset and testing its performance on another, completely separate subset. If the accuracy on the test set is significantly lower than on the training set, the model is overfit. The fix often involves simplifying the model or acquiring a much larger and more varied dataset, which is rarely cheap or easy.
Evidence Analysis: Beyond Keyword Search
E-discovery has moved past simple keyword searches. The current generation of tools uses Natural Language Processing (NLP) to analyze massive document sets for concepts, sentiment, and communication patterns. Technology-Assisted Review (TAR) systems use active learning models to prioritize documents for human review, saving countless hours of manual labor.
The process works by having a senior attorney review a small seed set of documents, coding them as responsive or non-responsive. The system trains a model on these initial decisions. It then uses the model to score the entire remaining document population, presenting the documents it is most uncertain about to the human reviewer next. With each human decision, the model retrains and becomes more accurate. This iterative feedback loop dramatically reduces the number of irrelevant documents that attorneys must inspect.
Building the data pipeline for these systems is a serious architectural challenge. You are not processing a few megabytes of text. You are processing terabytes of PST files, PDFs, and scanned documents. This is shoving a firehose through a needle. The data must first be processed through an optical character recognition (OCR) engine, its text extracted, and its metadata indexed in a searchable database like Elasticsearch. Only then can the NLP models begin their work.
Topic Modeling and Communication Mapping
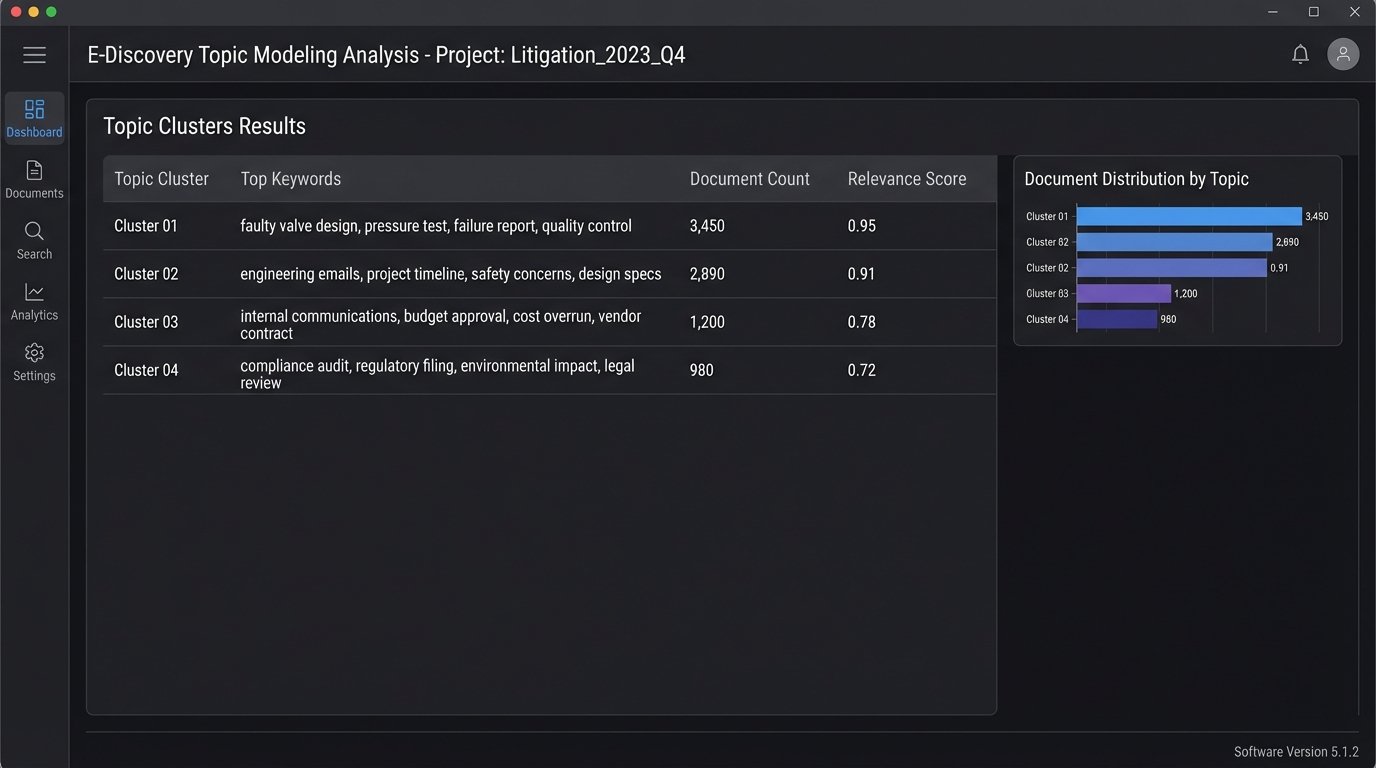
Two powerful techniques are topic modeling and communication mapping. Topic modeling algorithms, like Latent Dirichlet Allocation (LDA), can scan hundreds of thousands of emails and identify the main themes of conversation without any human guidance. The output might reveal a hidden cluster of documents discussing a “faulty valve design” that keyword searches missed entirely.
Communication mapping involves extracting the “to,” “from,” and “cc” fields from emails and other communications to build a social network graph. This visualizes who was talking to whom, and how frequently. This analysis can quickly identify key custodians or expose communication patterns that contradict a witness’s testimony. For instance, a graph might show a lead engineer, who claimed ignorance, was consistently copied on emails discussing the core issue in a product liability case.
The outputs of these models are not direct evidence. They are investigative tools that point human lawyers to the most critical documents. An LDA model doesn’t understand the legal meaning of the topics it finds. It just clusters words that tend to appear together. A human must interpret those clusters and determine their relevance to the case strategy.
Scheduling and Logistics as an Optimization Problem
So-called “AI scheduling” is often a misnomer. These systems are not using generative AI. They are using constraint satisfaction solvers, a well-established branch of operations research. The problem is to find an optimal schedule for depositions, court dates, and expert witness meetings that respects a large set of rigid constraints.
These constraints include:
- Court availability and deadlines
- Attorney and paralegal calendars
- Witness availability and travel time
- Venue booking and resource allocation
- Dependencies, such as deposing Witness A before Witness B
The system models this as a mathematical problem. Each person’s calendar is a set of available time slots, and each event has a required duration and set of participants. The solver’s job is to assign each event to a time slot in a way that violates no constraints. It’s a computationally intensive task, but it is deterministic. It does not “learn” or “predict” in the way a machine learning model does.
The real difficulty is integrating with the source-of-truth calendar systems. Most firms run on a mix of on-premise Exchange servers and cloud-based Office 365 or Google Workspace. Getting reliable, real-time calendar data requires authenticating through a mess of different APIs, each with its own quirks and rate limits. A broken API connection can render the entire scheduling system useless, creating chaos.
Implications for Trial Strategy: The Human-in-the-Loop Imperative
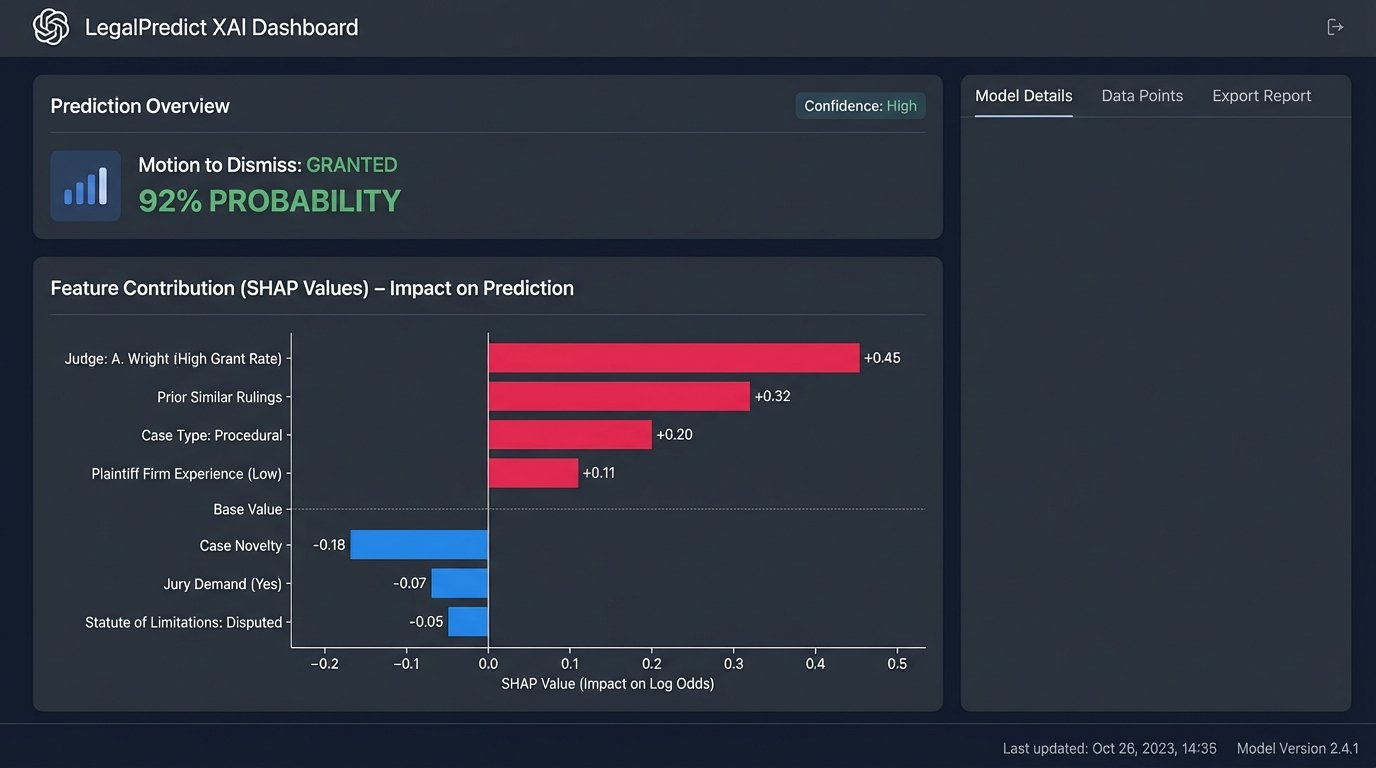
None of these tools replaces the strategic thinking of a litigation team. Their output is data, not answers. An AI model might flag a judge as having a 90% rate of granting summary judgment motions in similar cases. This is a critical piece of information, but it doesn’t automatically mean you should file one. The context of your specific case, the strength of your evidence, and the client’s goals must be evaluated by experienced counsel.
Over-reliance on these systems is a form of malpractice waiting to happen. If a model misses a key document in e-discovery because it was poorly scanned and the OCR failed, the fault lies with the legal team that failed to implement proper quality control checks. If a predictive model is wrong about a case outcome, the fault lies with the team that treated a statistical probability as a guarantee.
The proper architecture for AI in litigation is a human-in-the-loop system. The AI performs the brute-force data processing and pattern recognition that is tedious and inefficient for humans. The humans then take this distilled information, validate it, interpret it, and integrate it into a broader strategy. The AI finds the needles in the haystack. The lawyer decides what to do with them.
Explainability and Admissibility
A final, critical hurdle is explainability. If you rely on an AI-driven analysis to make a key strategic decision, you must be able to explain how the model reached its conclusion. Many powerful models, especially deep learning neural networks, operate as “black boxes.” They can produce remarkably accurate predictions, but their internal decision-making logic is opaque. This is a massive problem for legal applications.
Courts are beginning to scrutinize the use of these technologies. You cannot simply tell a judge “the computer said this document was important.” You must be able to articulate the criteria the model used. This is driving a push towards “Explainable AI” (XAI) techniques, like LIME or SHAP, which attempt to provide local explanations for individual predictions. Implementing and understanding these XAI layers adds another level of technical complexity to the system, but it is no longer optional. The credibility of the entire process depends on it.