
The marketing slides for litigation technology promise a future of AI-powered case analysis and automated strategy. The reality is a partner’s laptop struggling to open a 500-page PDF while your e-discovery platform chokes on malformed PST files from a legacy email server. Before we talk about the future, we need to be brutally honest about the present. Most legal tech infrastructure is a patchwork of brittle APIs, siloed data, and systems that were never designed to communicate.
This is not a failure of vision. It is the accumulated technical debt of decades. The next wave of litigation prep technology will not be a shrink-wrapped solution you install. It will be a series of brutal integration projects that force a new level of discipline on data governance and internal workflows. Those who succeed will build a significant strategic advantage. Those who fail will be sold expensive dashboards that show nothing of value.
Deconstructing AI-Driven Document Analysis
The term “AI” in e-discovery is often a fraudulent label for what amounts to advanced keyword searching and basic natural language processing. True analytical power comes from forcing machines to understand context, not just count words. This involves moving from simple string matching to semantic analysis, where document vectors and topic models can group concepts and identify relationships that a human reviewer might miss after eight hours of staring at a screen.
This process is computationally expensive and entirely dependent on the quality of your input data. It is not magic.
Beyond Keyword and Boolean Logic
A standard e-discovery workflow relies on attorneys crafting boolean search queries. For example, `(contract OR agreement) AND (terminate* OR breach*) NOT (draft)`. This is effective but crude. It finds documents containing specific words, but misses conceptually related documents that use different terminology. A contract termination letter that never uses the word “terminate” but discusses “cessation of services” would be missed entirely.
Semantic analysis bypasses this. It ingests a corpus of documents, strips out common words, and converts each document into a high-dimensional vector based on its content. Documents with similar meanings will have vectors that are mathematically close to each other in this vector space. Running a clustering algorithm like K-Means on these vectors automatically groups related documents. You are no longer searching for keywords. You are searching for concepts.
This lets you find the unknown unknowns. You can identify entire categories of communication you didn’t even know to look for. The trade-off is control. The machine decides what is conceptually similar, and the logic is not always immediately apparent.
The Data Integrity Bottleneck
This entire process collapses without clean, structured text. The most advanced language model on the planet cannot parse a poorly scanned, coffee-stained document with heavy graphical artifacts. Your firm’s document repository is likely a toxic swamp of multi-generational file formats, from `.wpd` files to image-only PDFs and password-protected ZIP archives. Preprocessing this data is 80% of the work. It involves building a pipeline that can identify file types, route them to appropriate text extraction engines, and normalize the output.
Think of it as building a digital refinery. You need a system to crack open different types of containers (PST, MSG, PDF, DOCX), apply optical character recognition (OCR) to images, and strip out all the junk formatting and metadata. Only then can you feed the resulting raw text to the analytical model. Shoving a firehose of unstructured data through this needle is the single biggest engineering challenge.
A simplified version of this data pipeline might look something like this in Python, using common libraries for a proof-of-concept. This does not represent a production-ready system but illustrates the logical steps.
import textract
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
def process_document(file_path):
“””Extracts raw text from a document file.”””
try:
# textract handles various file types like .pdf, .docx, etc.
text = textract.process(file_path).decode(‘utf-8’)
# Basic cleaning: lowercase and remove line breaks
return text.lower().replace(‘\n’, ‘ ‘)
except Exception as e:
# Production systems require robust error logging
print(f”Error processing {file_path}: {e}”)
return “”
# Assume ‘document_paths’ is a list of file paths to your evidence
corpus = [process_document(path) for path in document_paths]
# Vectorize the text corpus
vectorizer = TfidfVectorizer(stop_words=’english’)
X = vectorizer.fit_transform(corpus)
# Cluster documents into 10 conceptual groups
kmeans = KMeans(n_clusters=10, random_state=0)
kmeans.fit(X)
# Now ‘kmeans.labels_’ holds the cluster ID for each document
# You can analyze the top terms per cluster to understand the topics
This snippet glosses over the immense difficulty of dependency management, error handling for corrupted files, and scaling this to terabytes of data. It is a starting point, not a solution.

Predictive Analytics: The Unreliable Crystal Ball
Vendors love to demo predictive analytics for case outcomes. They show dashboards predicting settlement values or motion success rates with alluring precision. These systems are not clairvoyant. They are statistical models built on historical data, and their accuracy is entirely dependent on the quality and relevance of that data. For most firms, the data required to build a reliable model simply does not exist in a usable format.
Data Dependencies and The Scraping Problem
To predict the ruling of a specific judge on a motion to dismiss, you need a structured dataset of that judge’s prior rulings on similar motions. This data is technically public, locked away in systems like PACER. However, it is not available via a clean, stable API. It requires a massive web scraping and data extraction effort. You have to pull down thousands of PDF court filings, parse them to identify the motion type, the parties, the ruling, and the core legal arguments. This is a significant data engineering project in itself.
Internal firm data is even worse. Your case management system might track high-level outcomes, but does it tag every filing with the specific legal arguments made? Does it record the settlement amount in a structured field, or is it buried in a paragraph of unstructured text in a closing memo? Without this granular, structured data, you cannot train a model. The model will be garbage.
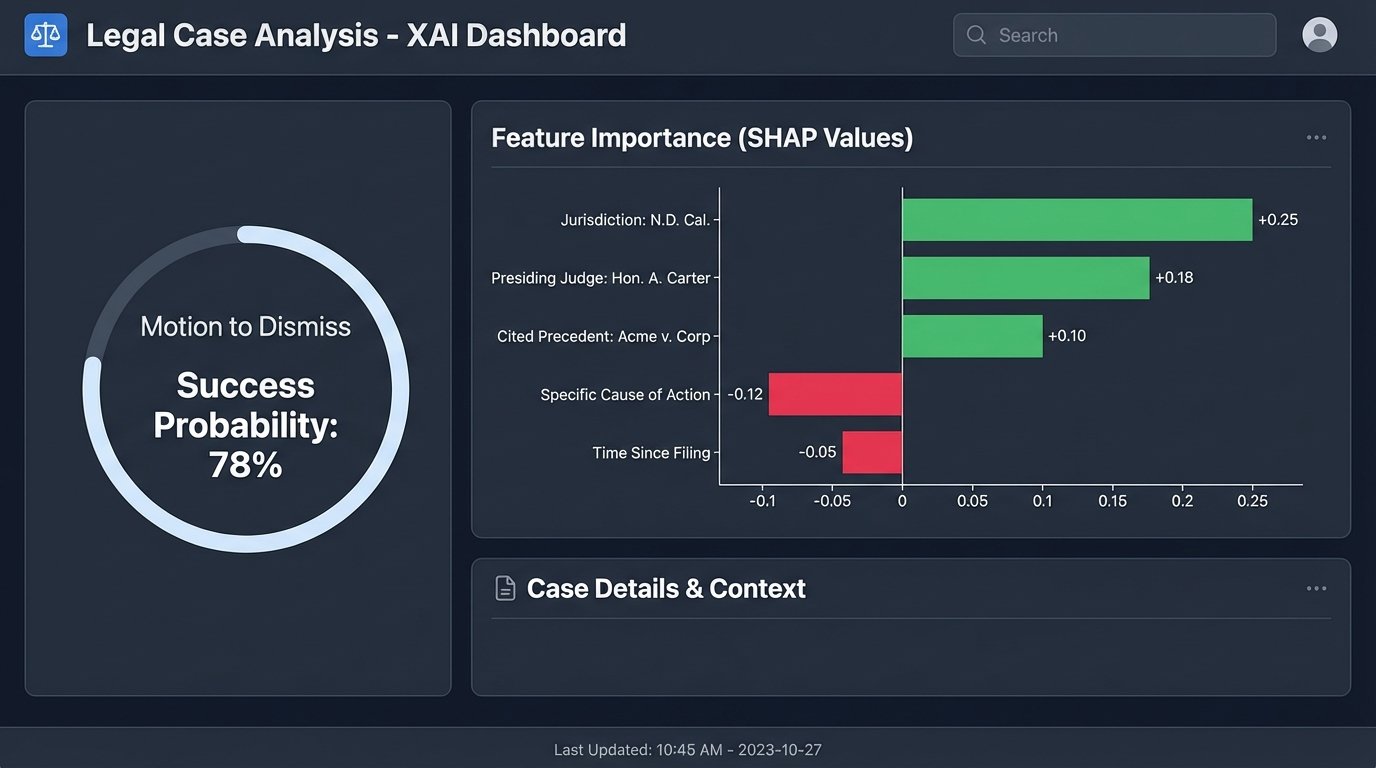
The Explainability Mandate
Let us assume you solve the data problem. You build a deep learning model that predicts a 78% probability of success for a particular legal strategy. A partner asks you why. If your answer is “because the neural network’s weights and biases configured themselves this way,” you will be laughed out of the room. This is the black box problem. You cannot present a legal argument to a court or a client based on the opaque output of a complex algorithm.
This forces a design constraint. We must favor simpler, more interpretable models over more complex, higher-performing ones. A logistic regression model or a decision tree can provide a clear rationale for its prediction. You can point to the specific factors (e.g., jurisdiction, presiding judge, presence of certain case law citations) that most heavily influenced the outcome. This transparency is not optional. It is a professional and ethical requirement.
Tools from the field of Explainable AI (XAI), such as LIME or SHAP, can help bridge this gap by providing explanations for individual predictions from more complex models. But they are an additional layer of analysis, not a substitute for building an inherently interpretable system from the ground up.
Virtual Trial Simulations: Beyond PowerPoint
The concept of virtual trial preparation is often misunderstood as simply creating more visually appealing courtroom exhibits. While better graphics are useful, the real potential lies in creating interactive, dynamic simulations for witness preparation and strategy testing. This is about moving from static presentations to dynamic training environments.
From Static Exhibits to Interactive Witness Prep
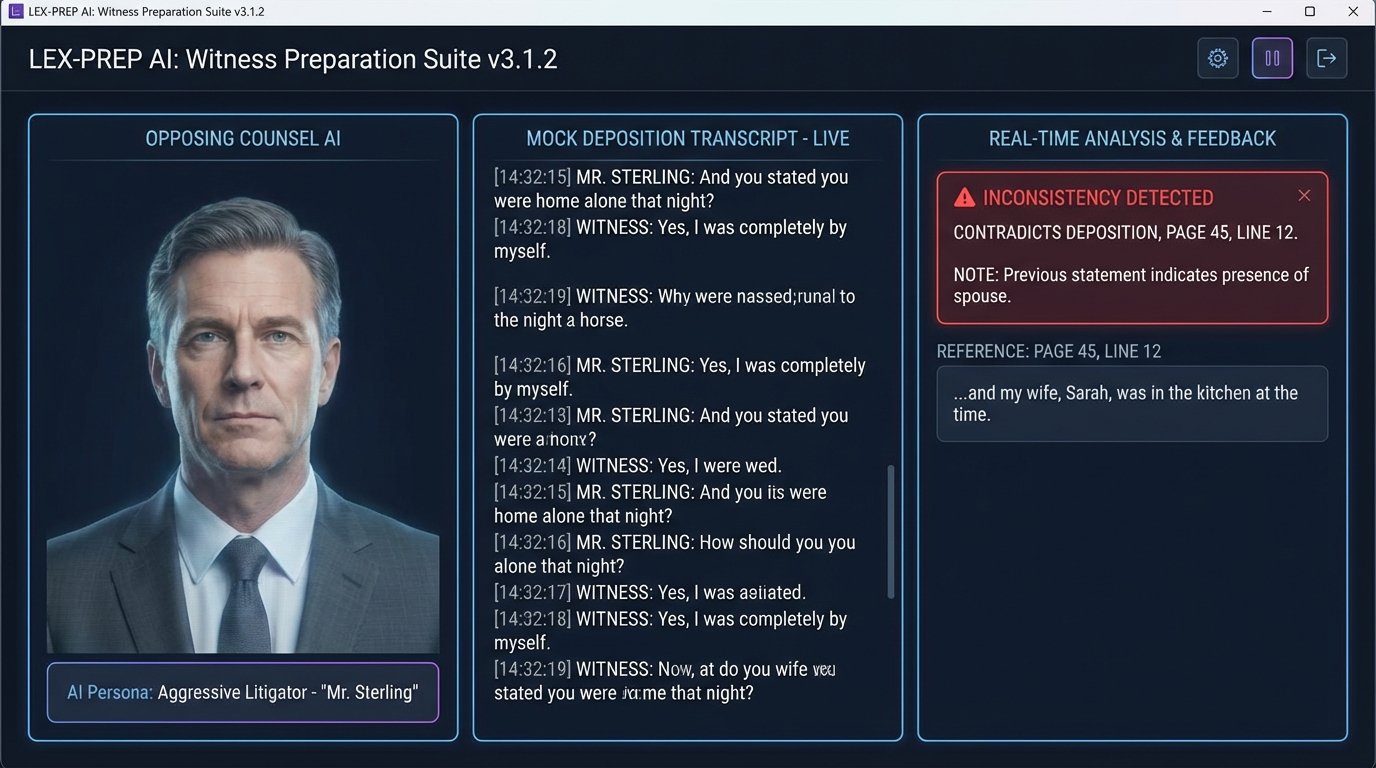
Imagine a training tool for a key witness. Instead of a partner playing the role of opposing counsel, the witness interacts with an AI-powered avatar. This system would be driven by a large language model (LLM) fine-tuned on the entire case file: depositions, emails, expert reports, and all relevant documents.
The AI could then conduct a mock cross-examination, probing for weaknesses and inconsistencies in the witness’s testimony. It could introduce exhibits dynamically and ask targeted questions about them. It could adapt its line of questioning in real-time based on the witness’s answers, simulating the pressure of a real deposition far more effectively than a human role-player who can’t possibly memorize every detail of a multi-terabyte case file.
This allows for scalable, repeatable, and data-driven witness prep. The system could log every response, flag problematic answers, and provide an objective report on the witness’s performance, consistency, and demeanor. This is the true next step in trial simulation.
The Infrastructure Wallet-Drainer
This level of simulation is not a software feature. It is an infrastructure project. Fine-tuning and running a large language model on a massive case file requires immense computational power. We are talking about fleets of high-end GPUs, the kind used for scientific computing and cryptocurrency mining. A single NVIDIA A100 GPU can cost over ten thousand dollars, and a production system would require multiple.
This is a wallet-drainer. The cost must be justified by the value of the case. Building this on-premise is a capital expenditure nightmare. The more plausible route is to leverage cloud computing platforms like AWS SageMaker or Azure Machine Learning, which allow you to rent this processing power by the hour. Even so, the operational costs for a major piece of litigation could run into the tens or hundreds of thousands of dollars just for the compute time to train and run the simulation models.
A Pragmatic Path Forward
The technologies discussed are not science fiction. They are plausible extensions of current capabilities. However, they cannot be purchased off the shelf. They must be built on a solid foundation of clean data and modern infrastructure.
Firms looking to prepare for this future should ignore the marketing hype and focus on the unglamorous foundational work. Start by auditing your data sources. Launch projects to standardize and structure the data within your existing case management and document systems. Invest in modernizing your APIs to allow for programmatic access to this data.
Begin with small, high-impact automation projects. Build a script to classify incoming documents. Create a tool to extract key entities from court filings. These small wins build institutional knowledge and expose the real-world data quality problems you will need to solve. The future of litigation technology will not be delivered by a vendor. It will be painstakingly assembled by technical teams who understand that data is the bedrock of everything to come.