
Most discussions about AI in client intake are a waste of time. They fixate on the conversational interface, the chatbot’s personality, or the color of the widget. This is a fatal misdirection. The value is not in the chat window. It is in the plumbing behind the wall, the system that can digest, validate, and route a potential client’s problem without a human touching it for the first seven steps.
The current generation of legal chatbots are mostly just prettier web forms. They ask questions, collect strings of text, and then bundle it all into an email that lands in a paralegal’s inbox. This is not automation. It’s a digital repackaging of a manual process. The real work, the actual operational lift, begins only after that email is opened. True intake automation intercepts the data stream much earlier and forces a series of critical decisions before it ever becomes a task for a human.
The Anatomy of a Failed Intake System
A typical off-the-shelf intake tool operates in a dangerous silo. It lives on your website as a snippet of JavaScript, completely disconnected from your firm’s central nervous system: the case management system (CMS). This architecture creates immediate, predictable failures. A prospect submits their information, detailing an issue with a specific corporation. The chatbot politely thanks them and promises a follow-up. Twenty-four hours later, a paralegal performs a manual conflict check and discovers the corporation is a major firm client. The result is a wasted intake cycle and an awkward rejection email to a now-annoyed prospect.
This delay is a direct product of a system that cannot perform real-time validation. The chatbot has no access to the firm’s conflict database. It cannot check if the prospect’s problem matches the firm’s current practice area focus. It cannot query the marketing database to see if this lead came from a high-value campaign. It is a dumb terminal, a data collection device that punts all intelligence down the line. That’s not a step forward, it’s a lateral move with a nicer interface.
This entire model is built on a faulty premise. The goal isn’t just to collect information faster. It’s to qualify and reject faster. Your most valuable asset is attorney and paralegal time. A system that simply dumps unvetted leads into a queue does not respect that asset. It actually creates more noise by lowering the barrier to submission, flooding the intake team with low-quality or conflicted inquiries that must be manually sorted and discarded.
Building a Headless Intake Engine
A functional system treats intake as a backend process, not a frontend feature. The chat widget, the web form, the contact page, they are all just clients of a centralized, API-driven intake engine. This engine is the single point of truth. It contains the logic, the integrations, and the rules that determine a lead’s fate. Decoupling the intake logic from the user interface means you can swap out the frontend, add new channels like a mobile app, or accept direct API submissions from referral partners without rebuilding your core process every time.
The architecture for this engine has four primary components.
1. The Logic Core
This is a rules-based service that executes a decision tree on incoming data. At its simplest, this can be a series of `if/then` statements coded directly. A more mature setup uses a dedicated business rules management system (BRMS). The service takes a JSON payload from the frontend, runs it against the ruleset, and appends a score or status. Rules can be simple, like rejecting submissions from certain geographic locations, or complex, like cross-referencing the stated legal problem against a weighted list of the firm’s most profitable case types.
This logic must be brutal. Its primary job is to say “no.” It should disqualify leads aggressively based on non-negotiable criteria like practice area mismatch, budget constraints, or statute of limitations issues that are obvious from the initial data points. Every lead rejected by the machine is a victory for operational efficiency.
2. The Conflict Check Integration
Here is where most projects fail. The engine must query the firm’s conflict database in real-time. The problem is that many law firms run on old, on-premise CMS platforms with sluggish, poorly documented APIs, if they have APIs at all. Making a synchronous API call to these systems during an active user session is a recipe for unacceptable latency. The user is left waiting while your engine struggles to get a response.
The only workable solution is to bypass direct queries for initial checks. A better architecture involves a nightly or hourly ETL (Extract, Transform, Load) job that pulls key entity names, like current and past client names, from the CMS into a dedicated, high-speed search index like Elasticsearch or a Redis cache. The intake engine queries this lean, optimized cache for an initial “soft” conflict check. This returns a response in milliseconds, not seconds. A full, formal check is still required later, but this step catches the obvious blockers instantly. Trying to run real-time conflict checks against a 15-year-old CMS API is like shoving a firehose of data through a rusty garden spigot. You get pressure buildup, leaks, and a trickle of useful information.
3. Data Enrichment Services
A prospect provides a name and an email. Before this lead is ever presented to a human, the intake engine should automatically enrich it. It makes API calls to third-party services to pull back supplemental information. For a B2B prospect, it might query a service like Clearbit to get their company’s size, industry, and revenue. For an individual, it might check public records databases or social media profiles through a service like Pipl.
This step transforms a simple lead into a dossier. When the intake team finally sees the lead, it’s not just a name and a problem description. It’s a person or company placed in a business context. This allows for a much more intelligent and informed first contact, and it saves the team hours of manual Google searching.
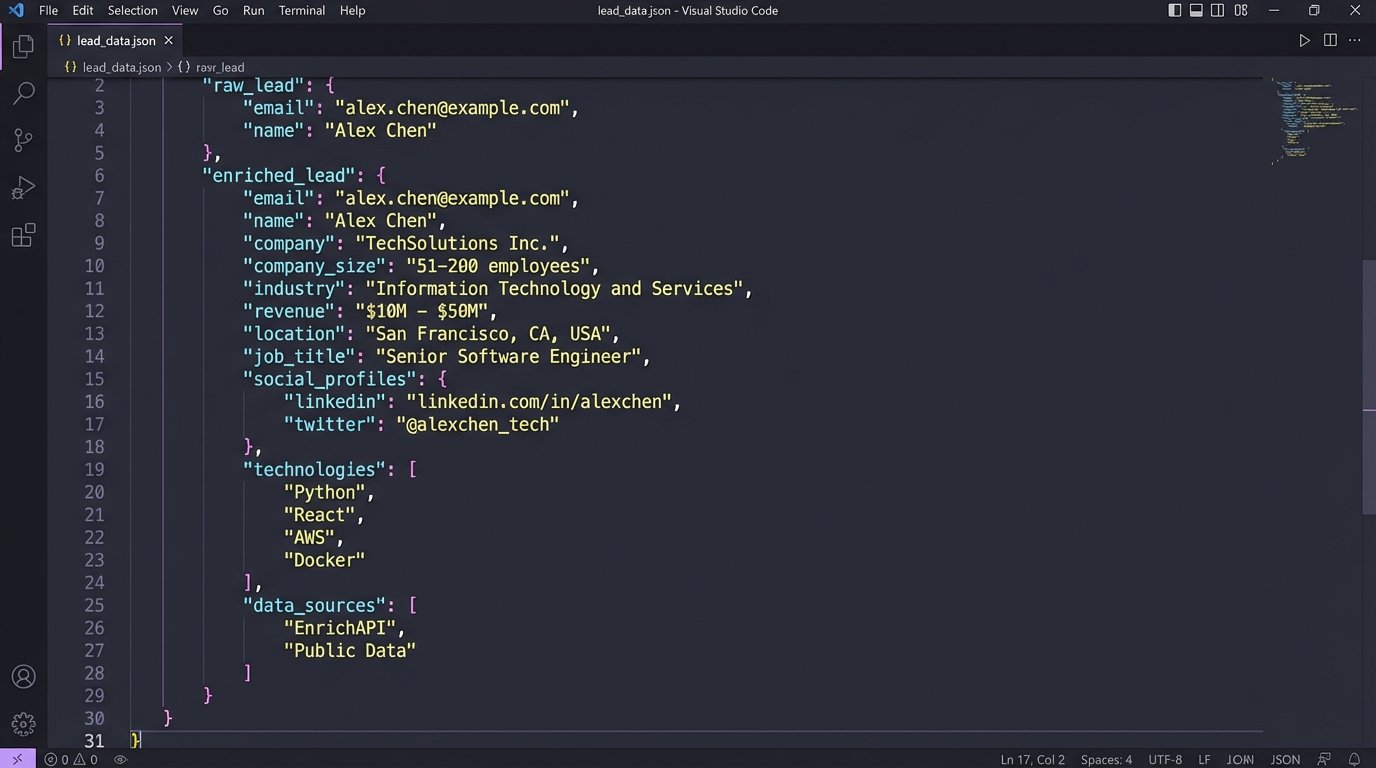
The architectural cost here is financial. These API calls are not free. You pay per request. This means the Logic Core must be smart about when it triggers enrichment. You do not enrich every single submission. You only enrich leads that have passed the initial qualification and conflict screens. It’s a metered expense that you apply only to prospects with a high probability of converting.
Using LLMs for Structure, Not Conversation
The popular application of large language models (LLMs) in legal tech is as conversational agents. This is a low-value use case. An LLM’s real power in the intake workflow is not conversation, but data structuring. Many prospects will not fill out your neat little form fields. They will paste a giant, unstructured block of text from an email or a legal document and expect you to figure it out.
This is the perfect job for an LLM. The intake engine can pass this text blob to a model like GPT-4 with a specific instruction: “Extract the following entities from this text and return them as a JSON object: plaintiff_name, defendant_name, key_dates, incident_location, and a one-sentence summary of the legal issue.” The model’s sole purpose is to act as a parser, transforming a chaotic narrative into a structured, machine-readable format.
Here is a simplified example of what that looks like in practice. The engine receives a raw text input from the user:
"Hi, I was rear-ended on I-5 near the main street exit on May 1st, 2023. The other driver was John Smith from Acme Corp. My car is totaled and their insurance is giving me the runaround. I need help."
The engine sends this to an LLM with a structuring prompt. The LLM returns a clean JSON object:
{
"potential_client_name": "unknown",
"opposing_party_person": "John Smith",
"opposing_party_entity": "Acme Corp",
"incident_date": "2023-05-01",
"incident_location": "I-5 near main street exit",
"case_type_guess": "Personal Injury - Motor Vehicle Accident",
"summary": "Client was involved in a car accident and is having issues with the other party's insurance."
}
This structured output can now be fed directly into the Logic Core and Conflict Check components. The system has manufactured data integrity from a chaotic input. This is a far more powerful application than asking a bot to say “I’m sorry to hear that.”
Closing the Loop: Intake as Business Intelligence
The process does not end when a client signs an engagement letter. The data generated by the intake engine is a goldmine for firm management, but it is almost always discarded. Every submission, whether accepted or rejected, is a data point that should inform strategy. Which marketing channels are producing the most high-value, non-conflicted leads? Are we seeing a sudden spike in a particular practice area? Which leads are being rejected, and why?
A proper intake engine is instrumented for analytics. Every major decision point in the workflow should trigger an event that is pushed to a central data warehouse or BI platform. A webhook fires when a lead is received, when it’s enriched, when the conflict check runs, when the logic core makes a qualification decision, and when the lead is finally accepted or rejected by a human.
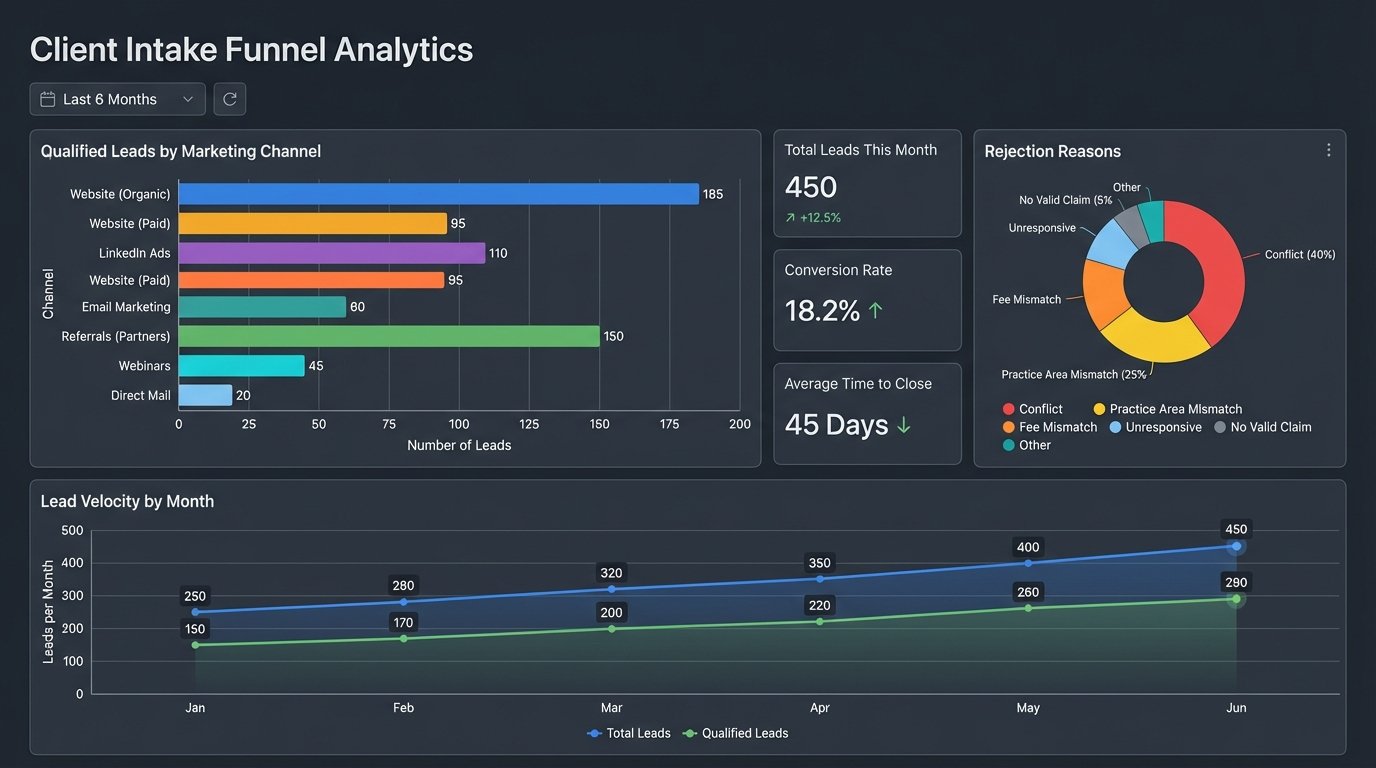
This event stream allows you to build dashboards that visualize the health and performance of your client acquisition funnel in real-time. You can see your lead velocity, your qualification rate per marketing source, and the most common reasons for rejection. This data closes the loop between marketing spend and operational reality. It allows the firm to make data-driven decisions about where to invest its marketing budget, instead of relying on guesswork.
The future of client intake has nothing to do with making a friendlier chatbot. It is about building a silent, efficient, and ruthless qualification machine. It’s an API-driven backend system that integrates deeply with a firm’s core data, enriches leads automatically, structures unstructured data, and provides the business intelligence needed to grow intelligently. Firms that continue to bolt on superficial chat widgets are just automating the collection of emails. Firms that build the engine are automating the business of law.