
Most conversations about the future of legal CRM are marketing fluff. They promise AI that reads a client’s mind and automation that runs the firm for you. The reality is a mess of broken APIs, siloed data, and expensive systems that function as little more than digital address books. The core problem is not a lack of sophisticated tools. It’s a fundamental misunderstanding of the data infrastructure required to make those tools function.
Firms believe they can buy a solution. They cannot. They must build a foundation.
The Single Source of Truth is a Lie
Every CRM vendor pitches their platform as the “single source of truth.” This is an operational fantasy. In any law firm, client data lives in at least three hostile environments: the Practice Management System (PMS) for billing, the Document Management System (DMS) for work product, and the CRM for relationship tracking. These systems were never designed to speak the same language, and forcing them to sync is a constant, manual battle.
The result is data drift and decay. An address updated in the billing system never makes it to the CRM, leading to marketing materials sent to the wrong office. A key contact from the DMS is never formally logged as a relationship, so their importance is invisible. This is not a software problem. It is an architectural failure.
Building a true central data hub means abandoning the idea of perfect, real-time, two-way syncs. It’s too slow and failure-prone. A better architecture uses a one-way data flow with a defined hierarchy. The PMS is the master for billing information. The DMS is the master for matter-related documents. The CRM is the master for contact and relationship data only. You build lightweight data connectors that push updates from the master system to the others, overwriting stale data.
This approach accepts that the systems are separate and forces discipline. It’s not elegant, but it works.
Wrangling Unstructured Data
The most valuable client information is not in a structured field. It is buried in the text of emails, meeting notes, and court filings. This is unstructured data, and legacy CRMs are completely blind to it. The future of client intelligence depends on the ability to programmatically extract entities, dates, and intent from these text sources and inject them into a structured format.
This is where targeted application of Natural Language Processing (NLP) becomes practical. We are not talking about a sentient AI. We are talking about specific models trained to do one thing well: identify a counterparty’s name, extract a filing deadline, or classify an email’s sentiment as positive, negative, or neutral. These data points then populate new fields in the CRM, creating a far richer client profile than any human could maintain manually.
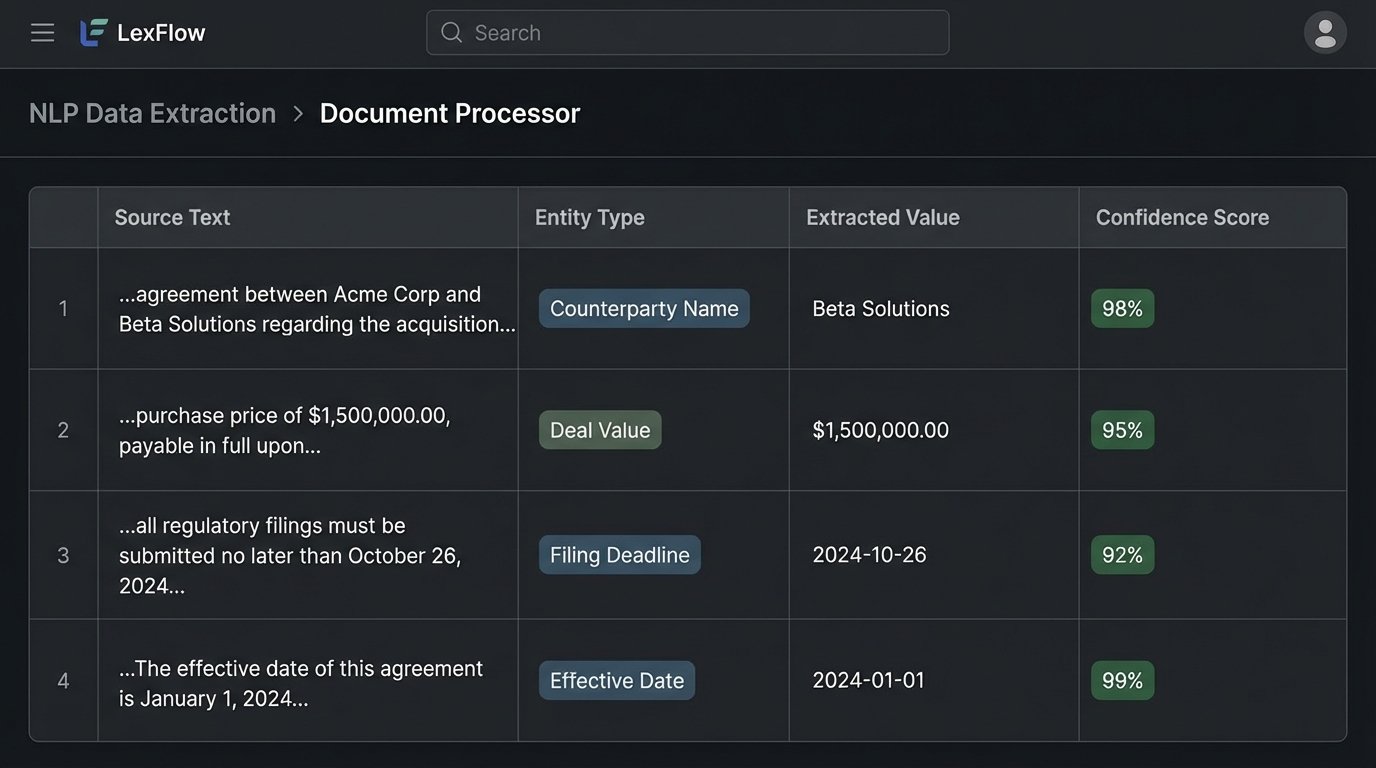
Consider an M&A deal. An NLP pipeline can scan all email traffic related to the matter, automatically extracting key deal terms like purchase price, closing date, and key personnel. These are not just notes. They become structured data points. You can then run analytics across all M&A deals from the last five years to identify trends in deal cycles or common points of failure.
This is the first step toward building a proprietary data asset.
Predictive Models Need Clean Fuel
The promise of “predictive client needs” is largely nonsense for high-value legal work. Off-the-shelf predictive models are trained on massive, generic datasets. They cannot understand the specific nuances of a client relationship or a complex legal matter. A model might predict a client in the manufacturing sector needs supply chain advice, which is an obvious and useless insight.
A more realistic and valuable application of predictive analytics is for internal process optimization. You can build models that predict budget overruns, matter duration, or the probability of a specific litigation outcome. These models, however, are entirely dependent on the quality of your historical data. If your firm doesn’t have at least five years of clean, consistently tagged data on past matters, any predictive model you build will be a random number generator.
The prerequisite for any predictive project is a data hygiene initiative. This involves a painful, often manual process of going back through old matters and standardizing data. You must enforce a strict data entry protocol for all new matters. Without this discipline, you are just feeding garbage into the algorithm. Trying to build a predictive model on top of a messy PMS is like trying to shove a firehose through a needle. It creates a high-pressure mess and delivers nothing.
Building the Data Schema
To support this, the CRM’s data schema must be expanded beyond basic contact information. You need to create custom objects and fields that reflect the business of law. For example:
- Matter Object: Linked to client contacts, it should have fields for practice area, matter type, key dates, budget, and current status.
- Billing Object: A simplified view of data from the PMS, showing total fees, realization rate, and last invoice date. This avoids giving everyone full access to the billing system.
- Relationship Object: A custom object to map the connections between contacts. Who introduced whom? Who is the key decision-maker at the client? Who is the opposing counsel? This maps the human network.
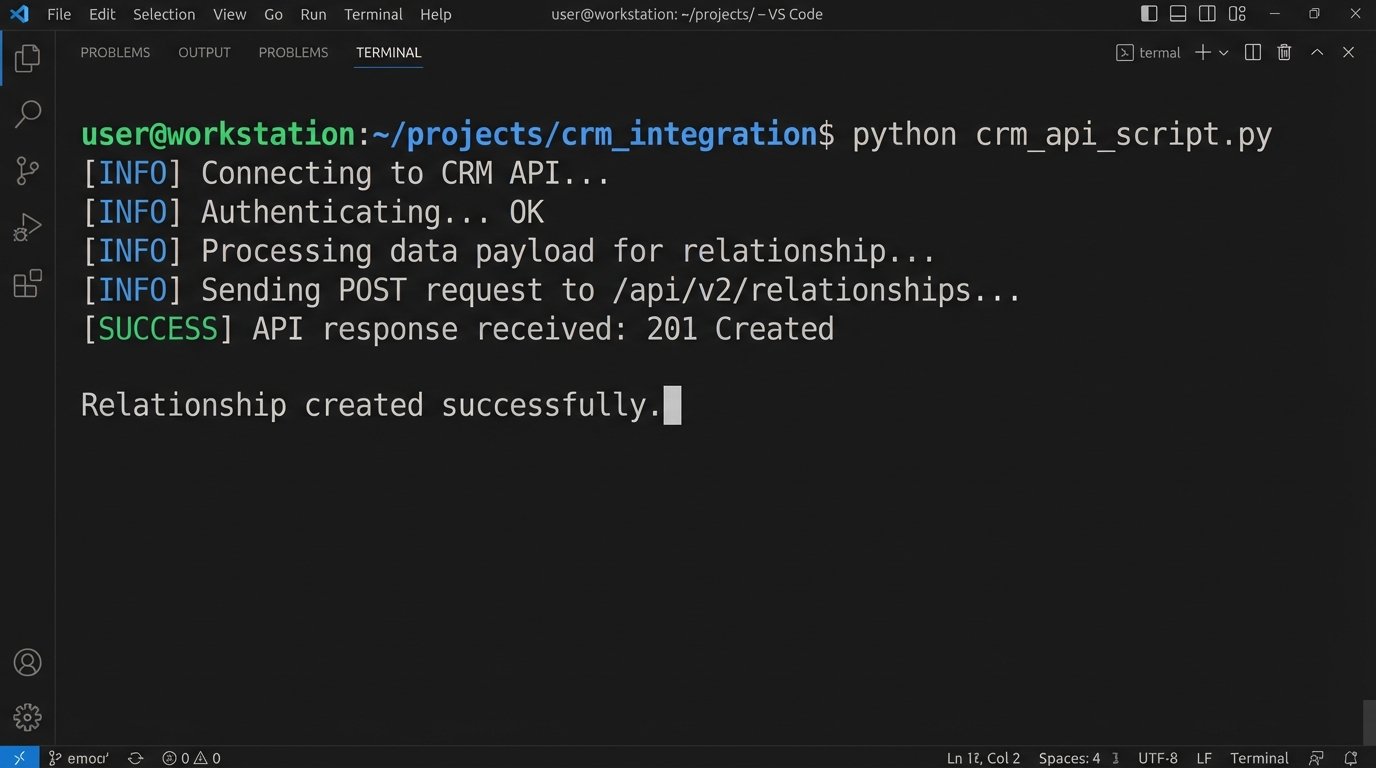
A simple python script using a CRM’s API can illustrate how you would create a relationship link between two contacts. This is not AI. This is basic data plumbing that most firms neglect.
import crm_api
# Assume contact_ids are fetched from the CRM
client_contact_id = "con_112233"
opposing_counsel_id = "con_445566"
matter_id = "mat_778899"
# Define the relationship type
relationship_details = {
"type": "Opposing Counsel",
"matter_context": matter_id,
"status": "Active"
}
# API call to create the link
try:
crm_api.create_relationship(
source_contact=client_contact_id,
target_contact=opposing_counsel_id,
details=relationship_details
)
print("Relationship created successfully.")
except crm_api.APIError as e:
print(f"Failed to create relationship: {e}")
Executing this simple logic consistently is more valuable than any “AI-powered” dashboard.
Automation Based on Triggers, Not Magic
Effective automation is not about artificial intelligence writing briefs. It is about defining simple, reliable, trigger-based workflows that execute when specific data conditions are met. The sophistication comes from the data triggers, not from the automated action itself. The goal is to reduce administrative drag and eliminate the possibility of human error on repetitive tasks.
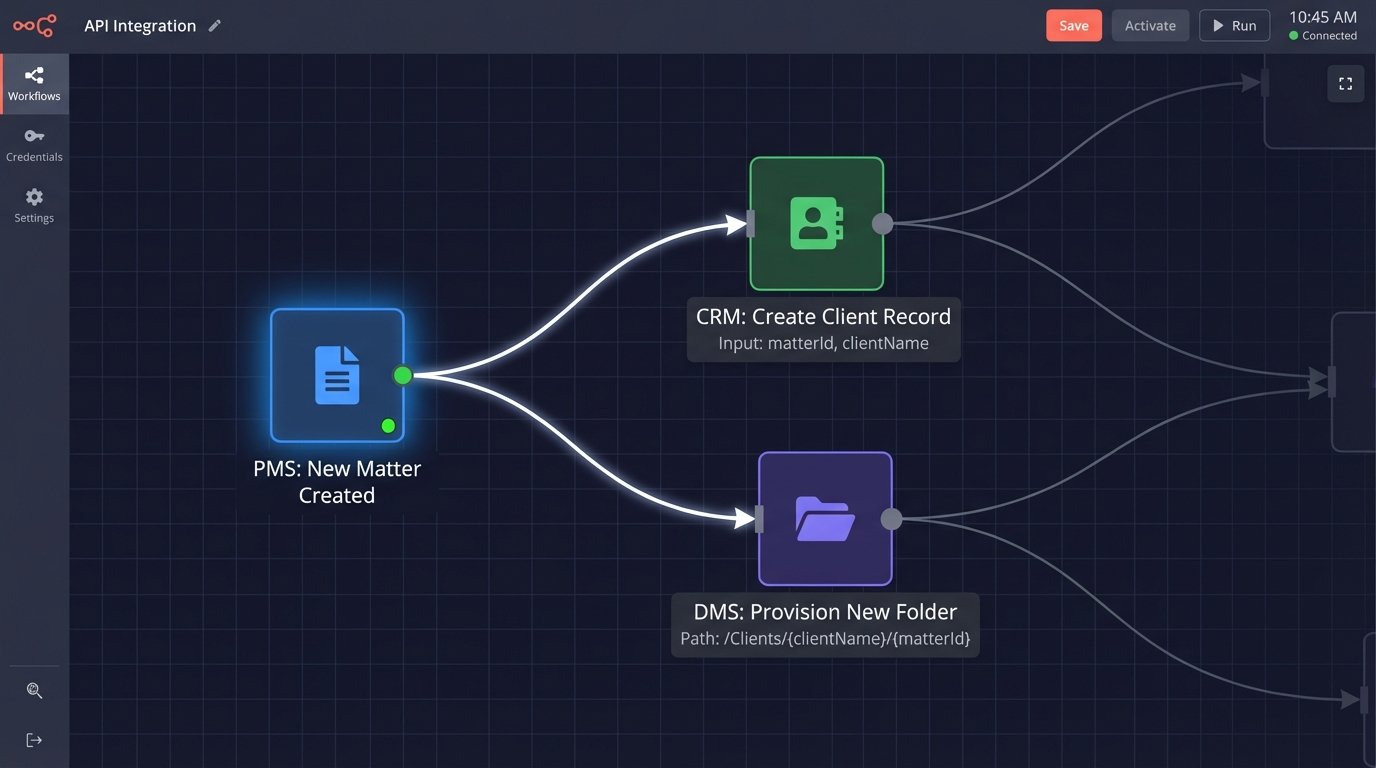
A classic example is client intake. When a new opportunity is marked as “Won” in the CRM, a workflow should automatically trigger. It can generate a conflict check request, create a new matter shell in the PMS, provision a new folder in the DMS with the correct naming convention, and assign a task to a paralegal to draft the engagement letter using a pre-approved template.
Each step is simple. The value is in the sequence and the reliability. This workflow saves hours of manual coordination and ensures the firm’s intake protocol is followed without deviation. Another powerful trigger is a date field. When a litigation matter has a “Statute of Limitations” date entered, a series of automated reminders can be scheduled for the legal team at 90, 60, and 30-day intervals. This is not complex technology, but it is a critical risk management function that a well-configured CRM should handle.
The Shift to a Composable Architecture
The future is not a single, monolithic CRM that tries to do everything. That model is too inflexible and expensive. The future is a composable, API-first architecture. In this model, the firm selects the best-in-class tool for each specific job: a powerful DMS, a reliable PMS, a flexible CRM, and specialized e-discovery or IP management tools.
The CRM’s role shifts from being the center of all activity to being the central data hub. It ingests key data from these other systems via their APIs. It becomes the system of record for the client relationship, but not for the documents or the invoices themselves. This approach requires an investment in integration development, either through an integration platform (iPaaS) or custom code, but it provides far more flexibility. When a better DMS comes along, you can swap it out without having to replace your entire technology stack.
This architecture treats the firm’s data as the primary asset, and the software applications as interchangeable tools used to interact with that data.
The Human Checkpoint is Non-Negotiable
Even with perfect data and flawless automation, the final decision point in any significant client matter must be a human. The risk of automated error in a legal context is too high. An AI cannot understand the strategic nuance of a negotiation or the emotional state of a client. Pushing for full “lights out” automation is a direct path to a malpractice claim.
The proper role of automation is to augment the lawyer, not replace them. An automation can analyze a contract and flag non-standard clauses. It should then present those flagged clauses to the lawyer for review. The system can draft a standard response to a discovery request, but a lawyer must approve it before it is sent. The CRM can suggest that a client might be at risk for a new regulatory change, but the partner must make the call and frame the conversation.
The user interface for these systems must be designed around this principle of human-in-the-loop validation. Every automated action that affects a client or a legal outcome must pass through a human approval gate. There is no other responsible way to operate.
Ultimately, the firm that succeeds will not be the one with the most “AI” features. It will be the one with the cleanest data, the most reliable internal APIs, and the deepest understanding that technology is a tool to support professional judgment, not a substitute for it.