
The marketing around AI in legal research sells a fantasy of instant, infallible answers. The operational reality involves wrestling with brittle APIs, sanitizing mangled OCR outputs from scanned court documents, and building validation layers to catch model hallucinations before they infect a legal brief. These tools are not replacements for legal intellect. They are powerful, but deeply flawed, text retrieval and summarization engines that require constant supervision.
Dumping a terabyte of case law into a generic large language model and expecting coherent legal analysis is an exercise in futility. The process is far more mechanical. The actual work begins with data ingestion and structuring, a thankless task that determines the ultimate reliability of the entire system. Without a clean, versioned, and properly indexed data source, the AI is just a sophisticated garbage-in, garbage-out machine.
Deconstructing the AI Research Stack
At the core of these platforms are three components working in sequence: a data pipeline, a vector database, and a language model for synthesis. The pipeline pulls documents from sources like PACER, court websites, or internal document management systems. It then chunks these documents into manageable pieces, often paragraphs or logical sections, before passing them to an embedding model. This is the first point of failure. Poor chunking strategies can sever a critical legal argument in half, rendering the resulting data useless.
The embedding model’s job is to convert these text chunks into numerical vectors. Think of it as assigning a unique coordinate to each piece of information in a massive, multi-dimensional space. Concepts that are semantically similar are placed closer together. This mathematical representation is what enables the system to find relevant context for a user’s query, moving beyond simple keyword matching to conceptual retrieval.
The Vector Database: A Glorified Index
Once vectorized, the data is loaded into a specialized database, like Pinecone or Chroma, that is optimized for finding the nearest neighbors to a query vector. When a lawyer asks, “Find precedents related to breach of fiduciary duty in Delaware corporate law,” their query is also converted into a vector. The database then performs a similarity search to retrieve the text chunks whose vectors are closest to the query vector.
This is nothing more than a high-speed lookup. The system has no understanding of “fiduciary duty.” It only knows that the cluster of numbers representing that query is mathematically proximate to other clusters of numbers derived from specific legal texts. It’s a brute-force association engine, not a cognitive partner.
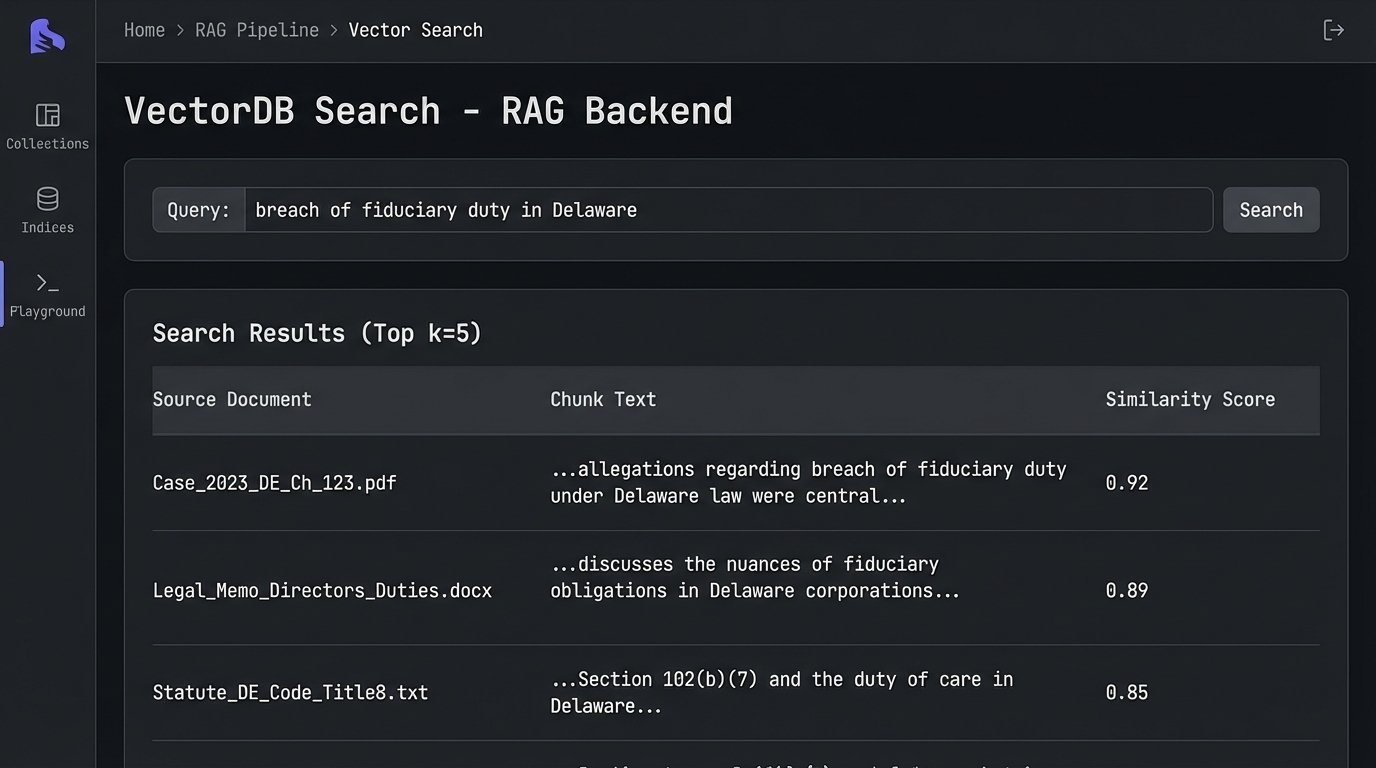
This entire retrieval process, often called Retrieval-Augmented Generation (RAG), is designed to mitigate the LLM’s tendency to invent facts. The retrieved text chunks are injected into the prompt that is sent to the final language model, effectively telling it: “Using only the following information, answer the user’s question.” This reduces hallucinations but does not eliminate them. The model can still misinterpret the provided context or blend concepts from different retrieved sources into a dangerously incorrect synthesis.
The Data Integrity Problem You Can’t Ignore
The primary engineering challenge is not model selection but data sanitation. Legacy legal data is a mess. We are not dealing with clean, structured JSON from a modern web API. We are dealing with poorly scanned PDFs, inconsistent formatting from hundreds of different courts, and metadata that is frequently incomplete or just plain wrong. Building a reliable ingestion pipeline is 90 percent of the work.
We often have to build custom parsers for specific jurisdictions or document types. A script designed to extract case details from a California Supreme Court filing will break when pointed at a filing from a Texas district court. This requires a library of adaptable scrapers and a robust error-handling system to flag documents that fail to parse correctly for manual review.
Here is a simplified Python example showing how we might attempt to pull and structure data from a hypothetical, and predictably awkward, court API. Notice the defensive coding needed to handle missing keys, which is the norm, not the exception.
import requests
import json
def fetch_case_data(case_id):
# This endpoint is fictional, but its flakiness is very real.
api_url = f"https://legacy.courtdatabase.gov/api/v1/cases/{case_id}"
headers = {"X-API-KEY": "your_very_old_api_key"}
try:
response = requests.get(api_url, headers=headers, timeout=10)
response.raise_for_status() # Will raise an exception for 4XX/5XX status codes
raw_data = response.json()
# Assume the API returns a mess. We have to pick it apart carefully.
structured_data = {
"case_number": raw_data.get("caseInfo", {}).get("number", "UNKNOWN"),
"filing_date": raw_data.get("filingDate", None),
"jurisdiction": raw_data.get("court_details", {}).get("name", "UNKNOWN"),
"raw_text": raw_data.get("fullTextOCR", "") # OCR text is notoriously dirty.
}
# Basic sanitation step
if not structured_data["raw_text"]:
print(f"Warning: No OCR text found for case {case_id}")
return None
return structured_data
except requests.exceptions.RequestException as e:
print(f"API request failed for case {case_id}: {e}")
return None
# Usage
case_details = fetch_case_data("CV-2023-9876")
if case_details:
print(json.dumps(case_details, indent=2))
The code above only gets the data. It does not even begin to address the cleaning of the `raw_text` field, which will be riddled with OCR errors like “fiduciary” being misinterpreted as “fduciary.” These small errors corrupt the vector embeddings and poison the retrieval results. The data sanitation layer must correct these before they enter the vector database. Feeding raw, unvalidated data into this system is like shoving a firehose through a needle. It creates a high-pressure mess that sprays garbage everywhere.
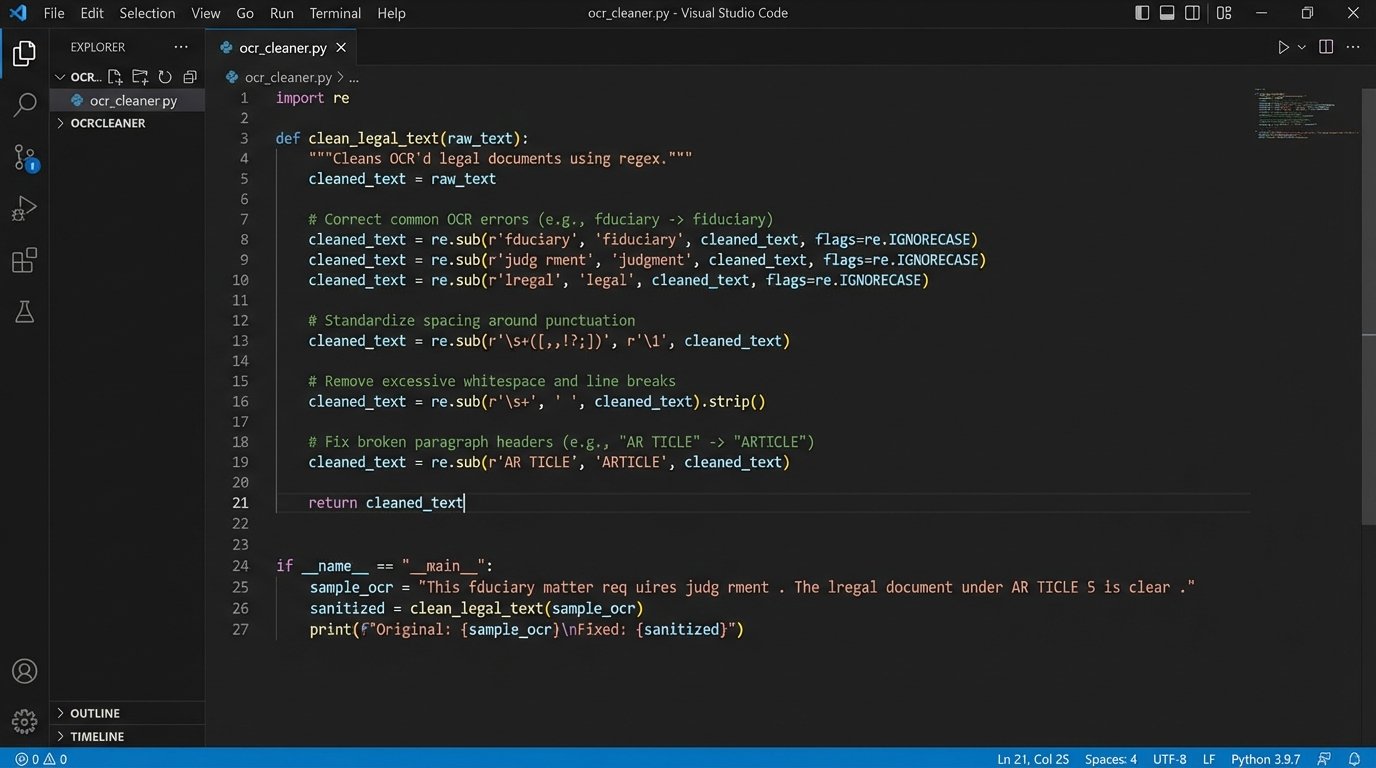
Building a Defensible AI Workflow
Trusting the output of these systems without a validation protocol is professional malpractice waiting to happen. An effective workflow does not end when the AI generates an answer. It begins there. The output must be treated as an unverified lead, not a final conclusion. Every claim, every citation, and every summary must be traceable back to its source document.
A functional system must provide explicit source linking. When the model summarizes a point, it needs to footnote the exact chunk of text from the source document it used. The user interface must allow a lawyer to click that footnote and see the original text in context. Without this traceability, the tool is a black box, and a black box has no place in a profession built on verifiable evidence.
Logic-Checking and Guardrails
We also build post-processing logic to act as a guardrail. This can be a set of rules or another, smaller AI model trained to check the output of the primary model. For example, if a query is about contract law in New York, a guardrail can flag any citations from California case law in the response. It is a crude but effective filter.
Another technique involves forcing the model to reason step-by-step before giving a final answer, a method known as chain-of-thought prompting. Instead of just asking for a summary, we prompt it to first identify the relevant legal principles, then find supporting facts in the text, and only then construct the summary. This makes the output more structured and easier to validate for a human reviewer.
Integration with Existing Legal Tech is Non-Trivial
These AI research tools do not operate in a vacuum. They must integrate with the firm’s existing ecosystem of case management systems (CMS), document management systems (DMS), and billing platforms. This is where the real wallet-drainer projects live. Most legal tech platforms have archaic, poorly documented APIs that were not designed for the kind of high-volume data exchange that AI systems require.
Connecting a modern vector search system to a 15-year-old CMS often requires building a custom middleware layer. This piece of software acts as a translator, converting requests and data formats between the new AI tool and the old legacy system. It’s a slow, painful process of mapping data fields, handling authentication quirks, and implementing rate limiting to avoid crashing the old server.
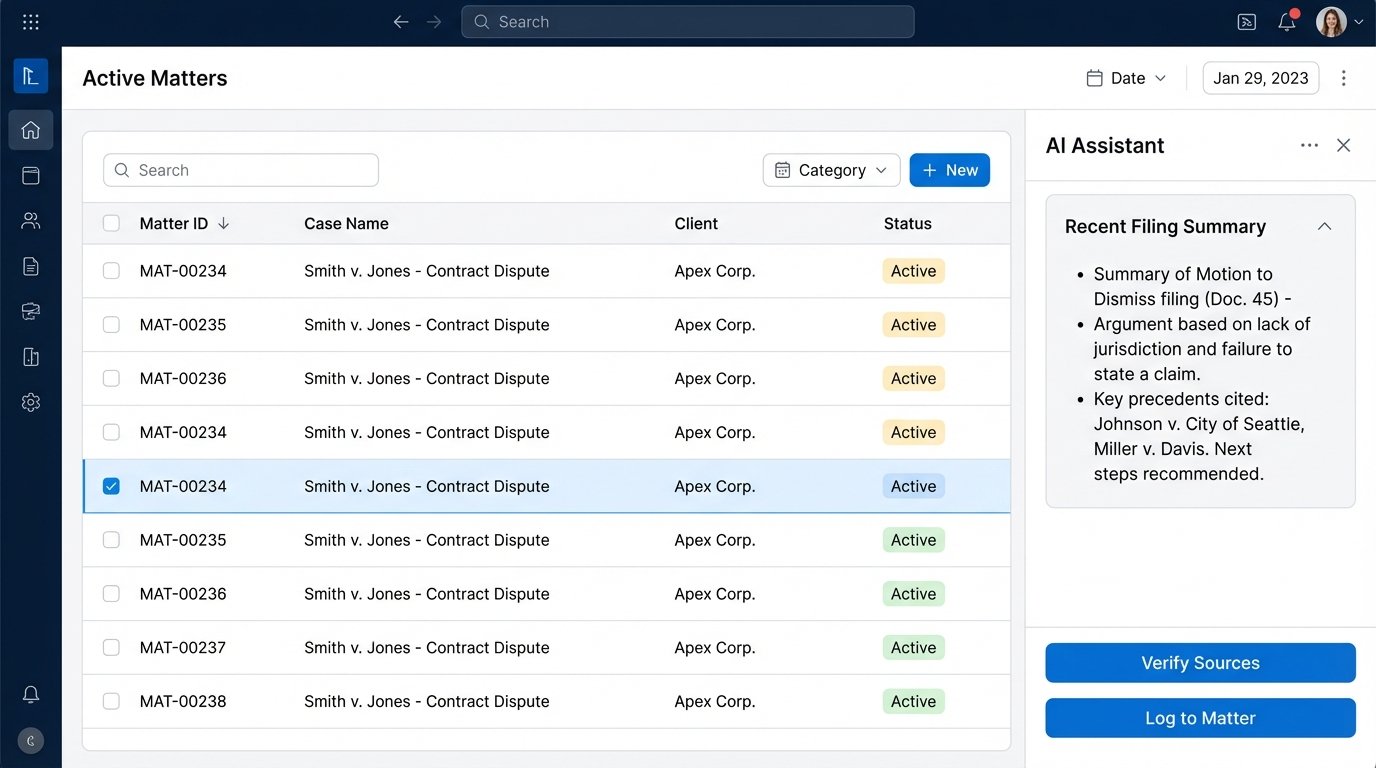
The goal is to create a seamless flow of information. A lawyer should be able to trigger a research query directly from a matter record in their CMS. The results should be automatically logged back to that matter, along with the generated summary and links to the source documents. Getting this to work reliably across disparate systems is a significant engineering effort that is often completely underestimated in the initial sales pitch.
Ultimately, the value of an AI research tool is not determined by the sophistication of its language model. It is determined by the quality of its data pipeline, the transparency of its source attribution, and its ability to be securely bridged into the firm’s core operational software. Anything else is just a demo.