
The core function of most legal AI is not reasoning. It is vector math. A large language model converts a legal query and a massive corpus of case law into numerical representations, or embeddings. The system then calculates the mathematical distance between your query vector and the document vectors to find the closest matches. This is a powerful retrieval mechanism, not a synthetic associate junior.
Forgetting this fundamental distinction is the fastest path to malpractice. These systems are sold as intelligence amplifiers, but they are, at their core, sophisticated pattern matchers that inherit every bias and gap from their training data. They don’t understand legal nuance. They calculate proximity.
Beyond Keyword Search: The Semantic Vector Space
Traditional legal research platforms operate on keyword matching and Boolean logic. You search for “contract frustration” AND “act of God,” and the engine returns documents containing those exact strings. The process is transparent but brittle. A judge using the term “impossibility of performance” instead of “frustration” might cause you to miss a key ruling. This is the problem vector search was built to solve.
Semantic search engines map words and phrases into a high-dimensional space where concepts with similar meanings are located near each other. The query “Can a contract be voided by an unforeseen pandemic?” gets converted into a vector. The system then finds case documents whose vectors are close to that query vector, even if they never use the word “pandemic” but instead discuss “epidemic,” “quarantine,” or “force majeure.” This allows for a conceptual search that is impossible with simple keyword lookups.
The technical underpinning is a model, often a Transformer architecture like BERT, that has been pre-trained on a colossal dataset of text. The model learns the relationships between words. The output is not an answer but a ranked list of text chunks that are probabilistically relevant to the query’s vector. The quality of this output depends entirely on the quality and scope of the training data and the specificity of the fine-tuning process for the legal domain.
The Fine-Tuning Problem in Legal AI
A general-purpose model trained on the public internet does not understand the specific syntax of legal citations or the hierarchy of courts. A vendor claiming their product uses “AI” must be forced to specify how their foundation model was adapted for legal work. Was it fine-tuned on a curated dataset from PACER, state court databases, and secondary sources? Or did they just layer a generic search index over a public data dump?
A properly fine-tuned model can distinguish between a binding precedent from the Supreme Court and a persuasive but non-binding opinion from a district court in another circuit. A generic model cannot. It sees both as just text, with the relevance score dictated by semantic similarity, not jurisdictional authority. This is a critical failure mode that can lead a junior associate down a completely wrong path.
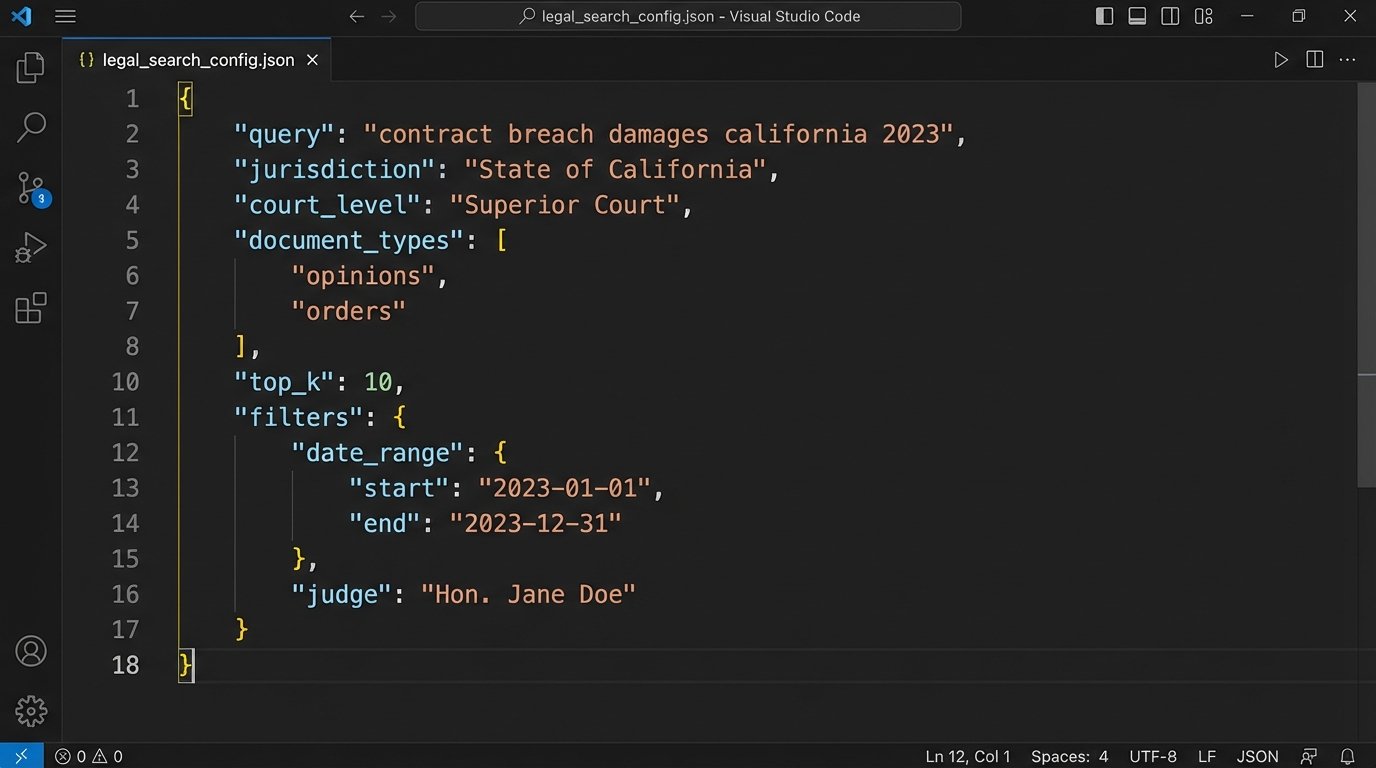
The request to a vendor’s API might look simple, but the work is happening on their servers.
{
"query": "Impact of force majeure clause on supply chain disruption due to government-mandated shutdown.",
"jurisdiction": "NY",
"court_level": ["appellate", "supreme"],
"date_range": "2020-01-01_to_2023-12-31",
"top_k": 10
}
The JSON object above defines the search parameters. The `top_k` value requests the 10 most semantically similar document chunks. The critical question is what corpus of documents the system is searching and how the model weighs the `jurisdiction` and `court_level` parameters against the raw semantic score of the `query`.
A lazy implementation might just filter the results after the semantic search is complete, which is inefficient and can exclude relevant cases that were just outside the initial `top_k` semantic matches. A better architecture integrates these filters directly into the retrieval process. You have to ask vendors how they built it.
Predictive Analytics: A Minefield of Biased Data
The next frontier being sold is predictive analytics. Tools claim to forecast case outcomes, predict a judge’s ruling on a motion, or estimate settlement values. These systems are typically regression models trained on historical court data. They identify patterns in past cases, such as the judge assigned, the law firms involved, the motion type, and the ultimate outcome, to build a predictive model.
The immediate problem is data quality. Public court records are notoriously messy. They contain missing data, typos, and inconsistent formatting. A model trained on this “dirty” data will produce unreliable predictions. The classic “garbage in, garbage out” principle applies with force. If a model is trained on a dataset where a certain type of litigant historically received unfavorable outcomes due to systemic bias, the model will not correct for that bias. It will learn the bias and project it forward as a mathematical certainty.
Connecting a sophisticated AI model to a legacy case management system full of unstructured, inconsistent data is like shoving a firehose through a needle. The pressure is immense, and the output is a useless trickle. The core engineering problem is almost always data sanitation and structuring, not the fanciness of the algorithm.
Consider a model designed to predict the likelihood of a motion to dismiss being granted. If the training data is pulled primarily from a jurisdiction where judges heavily favor dismissal, the model will develop a strong pro-dismissal bias. When applied to a case in a different, more plaintiff-friendly jurisdiction, its predictions will be dangerously inaccurate. The model has no concept of judicial philosophy. It only knows the statistical patterns from the data it was fed.
The Black Box Dilemma
Many predictive models are effectively black boxes. They provide an output, a percentage likelihood, but cannot explain the “why” behind their prediction. This lack of explainability is a massive risk in a profession built on reasoned argumentation. You cannot cite an algorithm’s opaque prediction in a legal brief. You must be able to articulate the legal reasoning, grounded in statutes and precedent, that supports your position.
A lawyer who relies on a predictive tool without independently verifying the underlying legal principles is committing a form of intellectual outsourcing. They are trusting the model’s correlation as causation. This creates a dangerous dependency on a tool whose internal logic is hidden and whose training data is likely flawed. Real legal analysis requires understanding the chain of reasoning, not just accepting a statistical output.
The only responsible way to use these tools is as a starting point for analysis, not as a replacement for it. The prediction can help identify areas of risk or opportunity, but each one must be torn down and validated against primary legal sources. The tool is a compass, not a self-driving car.
Building a Defensible AI Integration Strategy
Integrating AI into legal research is not a matter of buying a subscription. It is an engineering challenge that requires a new set of skills within the firm. The focus must shift from merely using the tools to actively auditing and validating them. Every AI-powered research platform should be subjected to a rigorous internal testing protocol before being deployed to lawyers.
This process involves creating a “golden set” of test queries. These are legal research problems where your firm’s experts already know the correct answer, the key cases, and the relevant statutes. You run these queries through the AI tool and meticulously analyze the results. Does it find the controlling precedent? Does it hallucinate citations? Does it misinterpret the holding of a key case? The failure modes you discover during this testing phase are more valuable than any marketing demo.
Questions to Force on Your AI Vendor
When evaluating a legal AI vendor, you must bypass the sales pitch and interrogate their engineering and data science teams. Their answers, or lack thereof, will tell you everything you need to know about the integrity of their system.
- Data Sources and Refresh Rate: What specific databases are you using to train and operate your model? How often is this data updated? A model trained on case law that is six months out of date is a liability.
- Handling of Jurisdictional Nuance: How does your model differentiate between binding and persuasive authority? Can we inspect the weighting system it applies to different courts?
- Citation Validation: What mechanism do you have in place to check for and flag “hallucinated” citations, where the AI invents a plausible but nonexistent case?
- Model Explainability: Can your system provide the specific text chunks from source documents that led to its conclusion? If it provides a summary, can we trace every sentence in that summary back to a primary source?
- Data Privacy and Security: When we run a query, is that data used to train your model? How do you segregate client data to prevent leakage between firms? What is your protocol for handling privileged information?
A vendor who cannot provide clear, technical answers to these questions is not selling a serious tool. They are selling a wrapper around a generic API with a legal-themed user interface.
The true impact of AI on legal research will not be a sudden replacement of lawyers. It will be a quiet separation between the firms that learn to master and audit these complex systems and the firms that are led astray by their outputs. The advantage goes to the legal professionals who treat AI with the same skepticism and demand for evidence that they apply to any other legal argument.
The future requires a hybrid professional, a legal engineer who understands both the logic of the law and the logic of the code. This person’s job is to act as the quality control layer between the raw output of the machine and the analytical mind of the lawyer. They don’t just use the software. They interrogate it, they stress-test it, and they know when to override its judgment. Without this human-in-the-loop, AI is just a faster way to get the wrong answer.