
The term “legal research automation” is a marketing fiction. It implies a clean, push-button process that magically extracts relevant case law from the ether. The reality is a brutal data plumbing problem. Most off-the-shelf platforms are black boxes, offering slick UIs that obscure rigid, opaque backends. They sell you access to their data, their algorithms, their conclusions. You are renting insights, not building an asset.
True automation isn’t about paying a vendor to run a search faster. It’s about constructing a proprietary data pipeline that ingests, structures, and interrogates legal information on your terms. The goal is to build an internal data warehouse that becomes a strategic asset, not to get locked into another per-seat license that drains the budget.
Deconstructing the Vendor-Locked Ecosystem
Commercial legal research platforms are walled gardens. They provide massive, pre-packaged datasets and powerful search tools, but they fundamentally control the environment. Their APIs, when they exist, are often sluggish, rate-limited, and expose only a fraction of the underlying data. You get the data points they choose to expose, formatted in the way they deem appropriate.
This model forces you to operate within their constraints. You cannot, for example, easily join their case law data with your internal matter management data to find correlations between judicial rulings and case outcomes. The platform’s analytics are generic, designed for the broadest possible audience. They can tell you a judge’s reversal rate on appeal, but they can’t tell you that judge’s average time to rule on a specific type of motion to dismiss filed by a particular opposing counsel in your firm’s most profitable practice area. The value is capped.
The Opaque Algorithm Problem
When you use a vendor’s “AI-powered” brief analysis tool, you are trusting their algorithm implicitly. You have no visibility into its training data, its weighting, or its potential biases. The system might flag a “key argument” because it appears frequently in the vendor’s dataset, not because it is the most legally salient point for your specific facts. It’s a statistical best guess, presented as authoritative analysis.
This lack of transparency is a critical failure point. You cannot audit the logic. You cannot fine-tune the model with your firm’s own work product. You are left hoping the black box was programmed correctly, a poor substitute for verifiable, deterministic logic. The dependency creates a strategic vulnerability. If the vendor changes its algorithm or pricing model, your entire research workflow is subject to their whims.
An API-First Architecture for Legal Data
A superior approach is to assemble a deconstructed, firm-owned research stack. This isn’t about replacing Westlaw for citation checking. It’s about building a supplementary system for generating proprietary analytics. This architecture consists of three core layers: ingestion, normalization, and interrogation.
The foundation is a robust ingestion engine. This involves programmatically pulling data from primary sources like PACER, state court e-filing portals, and regulatory websites. This is the grimiest part of the job. It requires writing and maintaining scrapers that can navigate login portals, handle CAPTCHAs, and parse inconsistent HTML structures. It’s a constant battle against undocumented site changes and defensive anti-bot measures.
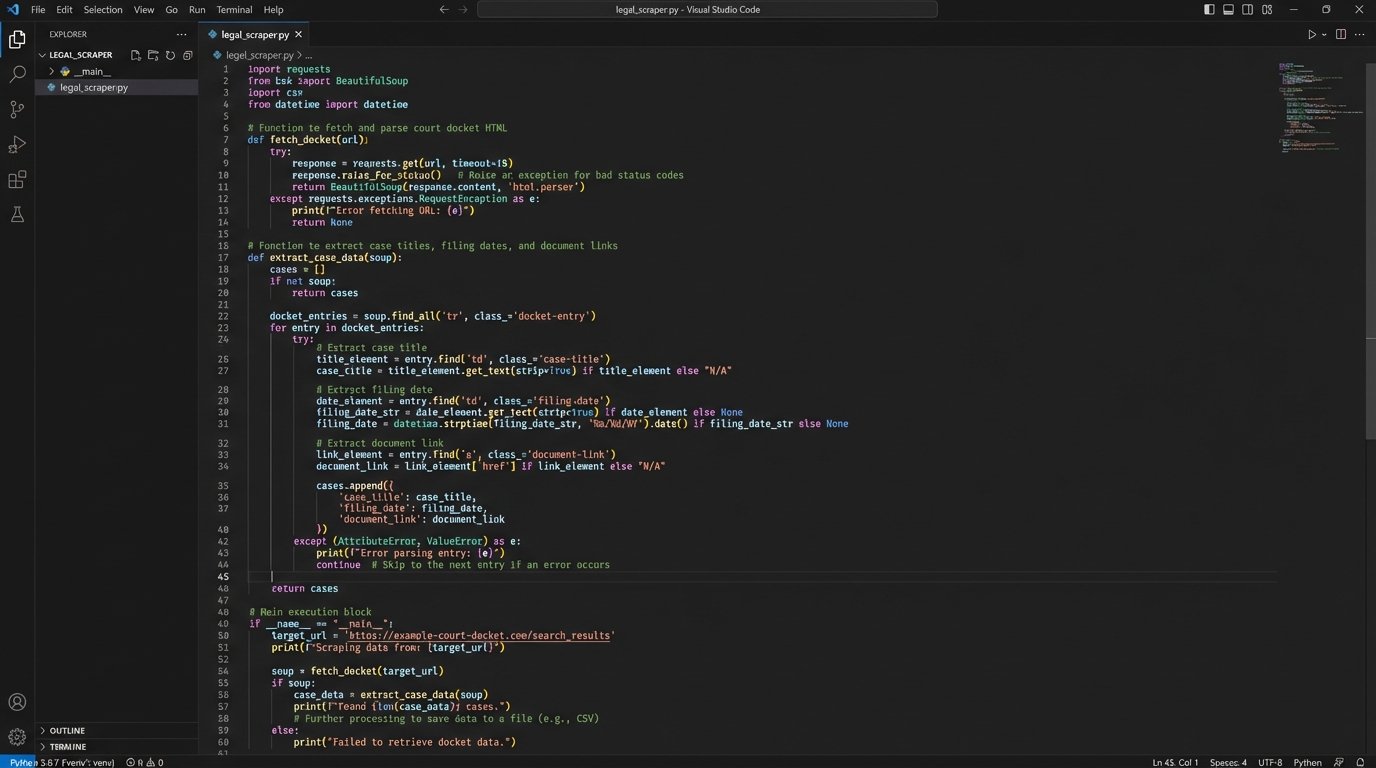
You might use a Python library like Selenium to drive a headless browser for sites that rely heavily on JavaScript, or the Requests and BeautifulSoup libraries for simpler, static sites. The key is to build resilient, fault-tolerant scrapers that log errors aggressively and can be restarted without losing their place.
This process is about capturing the raw source material, not a vendor’s interpretation of it. You get the full PDF, the complete docket entry text, and all associated metadata, straight from the court. This raw data becomes the ground truth for everything that follows.
The Normalization and Structuring Layer
Raw data is a liability until it’s structured. A folder full of a million PDFs is a digital landfill. The normalization layer is responsible for taking this chaotic input and forcing it into a predictable, machine-readable format. This is the most computationally intensive and complex part of the entire pipeline, like shoving a firehose of unstructured text through the eye of a needle.
First, we use Optical Character Recognition (OCR) engines like Tesseract to extract raw text from PDF filings. The output is often messy, filled with scanning artifacts and formatting errors. Custom Python scripts are then needed to clean this text, stripping out headers, footers, page numbers, and other noise. The goal is to isolate the core legal text of the document.
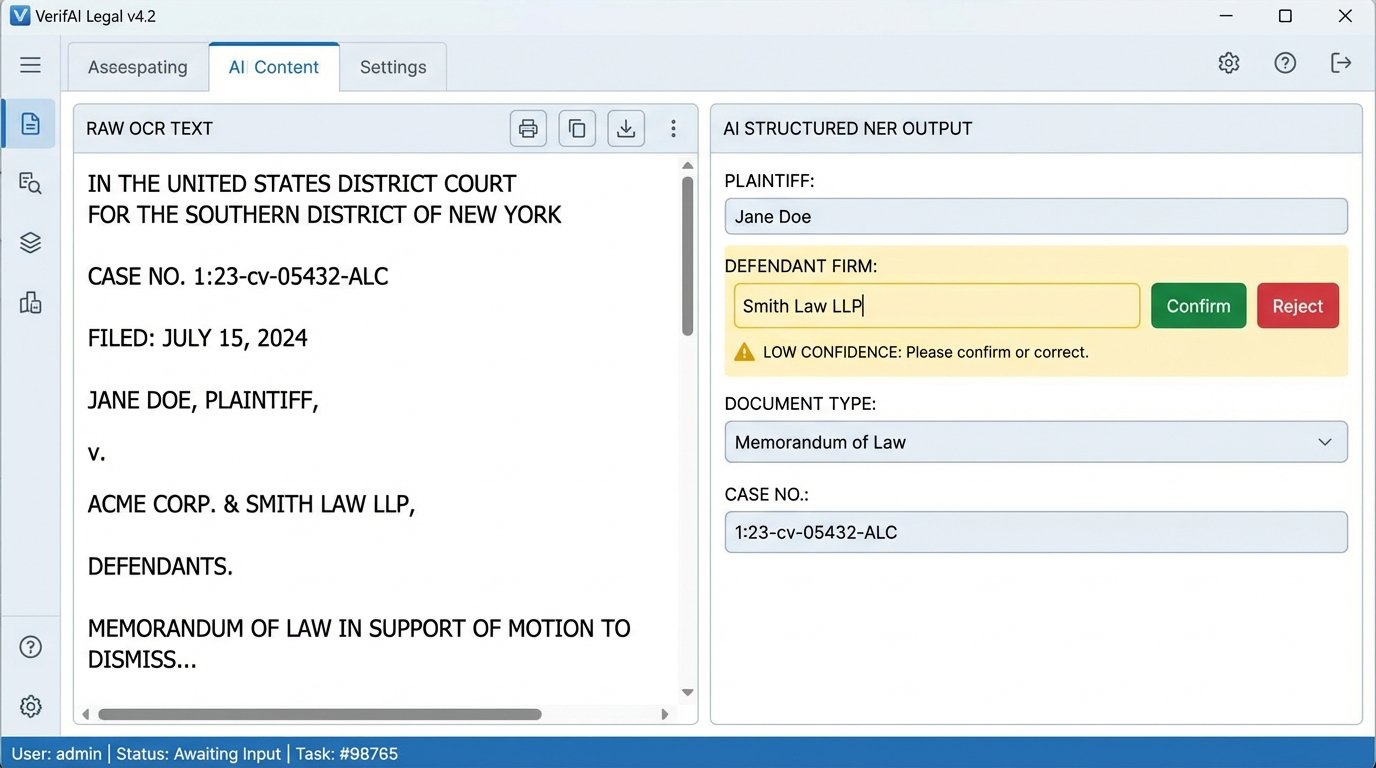
Next, we apply Natural Language Processing (NLP) models to identify and tag key entities. This process, known as Named Entity Recognition (NER), extracts structured information from the unstructured text. We train custom models to find things like:
- Parties: Plaintiff, Defendant, Third-Party
- Firms: Law Firm Names, Counsel of Record
- Judges: Presiding Judge, Magistrate Judge
- Document Types: Complaint, Motion to Dismiss, Summary Judgment
- Citations: Case Law and Statutory References
The result is a rich JSON object for each document, which can then be loaded into a proper database like PostgreSQL or a document store like Elasticsearch. The unstructured blob of text is now a structured record with dozens of queryable fields.
The Interrogation Core: Beyond Keyword Search
With structured data, we can move beyond primitive keyword searching. The modern approach is to use vector embeddings for semantic search. We take the cleaned text of a legal argument and feed it into a language model (like a BERT variant fine-tuned on legal text) to generate a high-dimensional vector, a numerical representation of that text’s meaning.
These vectors are stored in a specialized vector database like Pinecone or Milvus. When a lawyer wants to find similar arguments, we convert their query into a vector and perform a nearest-neighbor search in the database. This finds documents that are semantically similar, even if they don’t share the same keywords. It’s the difference between finding briefs that *use the word* “promissory estoppel” and finding briefs that *argue the concept* of promissory estoppel.
A simplified query against the structured data might look like this, assuming a SQL backend:
SELECT
d.document_title,
d.filing_date,
j.judge_name,
fc.firm_name AS filing_counsel
FROM
documents d
JOIN
judges j ON d.judge_id = j.id
JOIN
firms fc ON d.filing_firm_id = fc.id
WHERE
d.jurisdiction = 'S.D.N.Y.'
AND d.document_type = 'Motion to Dismiss'
AND d.outcome = 'Granted'
ORDER BY
d.filing_date DESC;
This query, impossible on a standard research platform, instantly pulls every successful motion to dismiss in the Southern District of New York, tagged with the judge and filing firm. This is the foundation of real analytical power.
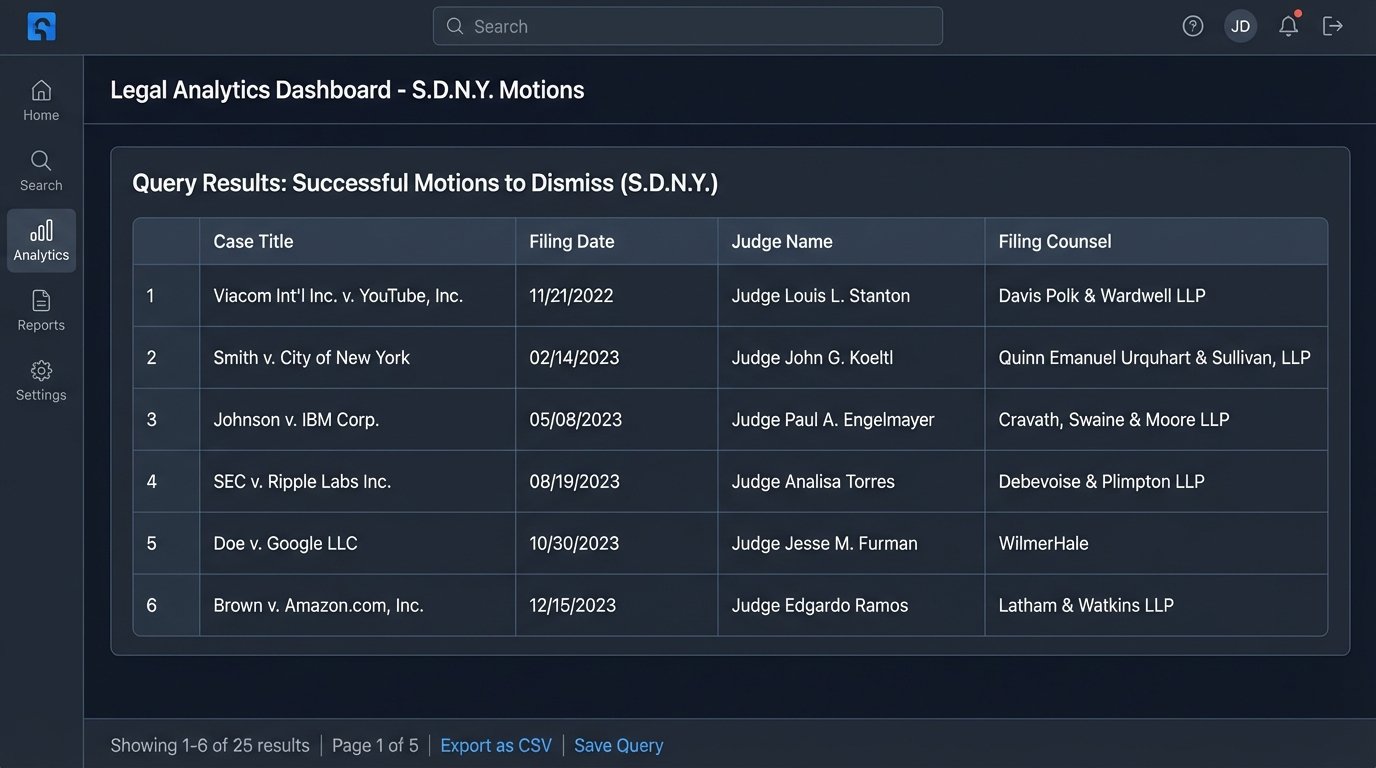
From Document Retrieval to Predictive Analytics
Owning the data pipeline unlocks capabilities that are impossible with off-the-shelf tools. The objective shifts from finding a specific document to analyzing the entire dataset for patterns and trends. This turns the research function from a reactive cost center into a proactive strategic intelligence unit.
We can build internal dashboards that provide bespoke analytics. For instance, a litigation group can have a dashboard dedicated to a specific judge. It can track their grant and deny rates for different motion types, the average time from filing to ruling, and which law firms have the highest success rates before them. This is not generic data. It is hyper-specific, actionable intelligence tailored to the firm’s active caseload.
Another powerful application is argument pattern recognition. By using clustering algorithms like K-Means on the document vectors, we can identify recurring patterns in an opposing counsel’s filings. The system can automatically group their summary judgment motions into distinct argumentative clusters. This deconstructs their playbook, revealing their preferred lines of reasoning and go-to case citations before you even start drafting a response.
Building a Proprietary Litigation Dataset
Every document ingested and every analysis performed enriches the firm’s private data asset. Over time, this dataset becomes a powerful competitive advantage. While competitors are relying on the same public information from vendors, your firm is building a deep, historical record of litigation that is mapped, structured, and interconnected with your own internal case data.
This allows for predictive modeling. You can start to build models that forecast the probability of a motion’s success based on the judge, the jurisdiction, the motion type, and the arguments presented. These models are not oracles, but they provide a data-driven check against a lawyer’s intuition, grounding strategic decisions in statistical reality rather than gut feeling alone.
The Inescapable Realities of Implementation
This approach is not a simple software installation. It is a significant infrastructure project. It requires a dedicated team of data engineers, cloud computing resources, and a budget for ongoing maintenance and development. The ingestion scrapers will break. The NLP models will need to be retrained. The database will need to be optimized. It is a capital investment in a data factory, not a subscription expense.
Data quality is a persistent threat. A poorly calibrated OCR process or a misconfigured NER model can poison the entire dataset with inaccurate information. The principle of “garbage in, garbage out” is absolute. This necessitates a human-in-the-loop validation process, where lawyers or paralegals periodically spot-check the system’s output to ensure accuracy. The automation assists the human expert. It does not replace them.
There are also ethical considerations. An algorithm trained on historical judicial data can inherit and amplify existing societal biases. If a model observes that certain arguments are less successful when made by certain demographics, it may perpetuate that bias in its predictions. Building these systems requires a conscious effort to identify and mitigate bias, a task that is part technical and part ethical. It demands oversight.
The firms that treat legal research as a data engineering discipline will build an insurmountable strategic advantage. They will move from simply finding the law to modeling the entire litigation landscape. Those who remain dependent on vendor-supplied black boxes will be competing with one hand tied behind their back, relying on generic insights while their competition leverages proprietary, data-driven intelligence.